 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Guided Noisy Negative Suppression for Zero-Shot Classification and Grounding of Chest X-Ray Findings
May 19, 2026Vision-language alignment using chest X-rays and radiology reports has emerged as an advanced paradigm for zero-shot classification and grounding of chest X-ray findings. However, standard contrastive learning typically treats radiographs and reports from different patients simply as negative pairs. This assumption introduces noisy negatives, as different patients frequently exhibit similar findings. Such noisy negatives cause semantic ambiguity and degrade performance in zero-shot understanding tasks. To address this challenge, we propose CoNNS, a concept-guided noisy-negative suppression framework. To support the negative suppression mechanism, unlike previous methods that use raw reports or templatized texts, we construct a hierarchical concept ontology using large language models. The ontology structures 41 key clinical concepts by explicitly modeling presence, attributes (location and characteristics), and texts (evidential segment and presence statement). Leveraging this ontology, we implement a cross-patient pair relabeling strategy comprising three steps: (1) Fine-Grained Breakdown to categorize pairs based on finding presence; (2) Noisy Negative Filtering to resolve semantic conflicts by removing false negatives; and (3) Hard Negative Mining to identify subtle attribute discrepancies using a lightweight language model. Finally, we propose a Concept-Aware NCE loss to align visual features with text while suppressing the identified noisy negatives. Extensive experiments across multi-granularity zero-shot grounding tasks and five zero-shot classification datasets validate that CoNNS outperforms existing state-of-the-art models. The code is available at https://github.com/DopamineLcy/conns.
Evidential Reasoning Advances Interpretable Real-World Disease Screening
May 14, 2026Disease screening is critical for early detection and timely intervention in clinical practice. However, most current screening models for medical images suffer from limited interpretability and suboptimal performance. They often lack effective mechanisms to reference historical cases or provide transparent reasoning pathways. To address these challenges, we introduce EviScreen, an evidential reasoning framework for disease screening that leverages region-level evidence from historical cases. The proposed EviScreen offers retrospection interpretability through regional evidence retrieved from dual knowledge banks. Using this evidential mechanism, the subsequent evidence-aware reasoning module makes predictions using both the current case and evidence from historical cases, thereby enhancing disease screening performance. Furthermore, rather than relying on post-hoc saliency maps, EviScreen enhances localization interpretability by leveraging abnormality maps derived from contrastive retrieval. Our method achieves superior performance on our carefully established benchmarks for real-world disease screening, yielding notably higher specificity at clinical-level recall. Code is publicly available at https://github.com/DopamineLcy/EviScreen.
Efficient Medical Vision-Language Alignment Through Adapting Masked Vision Models
Jun 10, 2025Medical vision-language alignment through cross-modal contrastive learning shows promising performance in image-text matching tasks, such as retrieval and zero-shot classification. However, conventional cross-modal contrastive learning (CLIP-based) methods suffer from suboptimal visual representation capabilities, which also limits their effectiveness in vision-language alignment. In contrast, although the models pretrained via multimodal masked modeling struggle with direct cross-modal matching, they excel in visual representation. To address this contradiction, we propose ALTA (ALign Through Adapting), an efficient medical vision-language alignment method that utilizes only about 8% of the trainable parameters and less than 1/5 of the computational consumption required for masked record modeling. ALTA achieves superior performance in vision-language matching tasks like retrieval and zero-shot classification by adapting the pretrained vision model from masked record modeling. Additionally, we integrate temporal-multiview radiograph inputs to enhance the information consistency between radiographs and their corresponding descriptions in reports, further improving the vision-language alignment. Experimental evaluations show that ALTA outperforms the best-performing counterpart by over 4% absolute points in text-to-image accuracy and approximately 6% absolute points in image-to-text retrieval accuracy. The adaptation of vision-language models during efficient alignment also promotes better vision and language understanding. Code is publicly available at https://github.com/DopamineLcy/ALTA.
CorBenchX: Large-Scale Chest X-Ray Error Dataset and Vision-Language Model Benchmark for Report Error Correction
May 17, 2025AI-driven models have shown great promise in detecting errors in radiology reports, yet the field lacks a unified benchmark for rigorous evaluation of error detection and further correction. To address this gap, we introduce CorBenchX, a comprehensive suite for automated error detection and correction in chest X-ray reports, designed to advance AI-assisted quality control in clinical practice. We first synthesize a large-scale dataset of 26,326 chest X-ray error reports by injecting clinically common errors via prompting DeepSeek-R1, with each corrupted report paired with its original text, error type, and human-readable description. Leveraging this dataset, we benchmark both open- and closed-source vision-language models,(e.g., InternVL, Qwen-VL, GPT-4o, o4-mini, and Claude-3.7) for error detection and correction under zero-shot prompting. Among these models, o4-mini achieves the best performance, with 50.6 % detection accuracy and correction scores of BLEU 0.853, ROUGE 0.924, BERTScore 0.981, SembScore 0.865, and CheXbertF1 0.954, remaining below clinical-level accuracy, highlighting the challenge of precise report correction. To advance the state of the art, we propose a multi-step reinforcement learning (MSRL) framework that optimizes a multi-objective reward combining format compliance, error-type accuracy, and BLEU similarity. We apply MSRL to QwenVL2.5-7B, the top open-source model in our benchmark, achieving an improvement of 38.3% in single-error detection precision and 5.2% in single-error correction over the zero-shot baseline.
Less Could Be Better: Parameter-efficient Fine-tuning Advances Medical Vision Foundation Models
Jan 22, 2024Parameter-efficient fine-tuning (PEFT) that was initially developed for exploiting pre-trained large language models has recently emerged as an effective approach to perform transfer learning on computer vision tasks. However, the effectiveness of PEFT on medical vision foundation models is still unclear and remains to be explored. As a proof of concept, we conducted a detailed empirical study on applying PEFT to chest radiography foundation models. Specifically, we delved into LoRA, a representative PEFT method, and compared it against full-parameter fine-tuning (FFT) on two self-supervised radiography foundation models across three well-established chest radiograph datasets. Our results showed that LoRA outperformed FFT in 13 out of 18 transfer learning tasks by at most 2.9% using fewer than 1% tunable parameters. Combining LoRA with foundation models, we set up new state-of-the-art on a range of data-efficient learning tasks, such as an AUROC score of 80.6% using 1% labeled data on NIH ChestX-ray14. We hope this study can evoke more attention from the community in the use of PEFT for transfer learning on medical imaging tasks. Code and models are available at https://github.com/RL4M/MED-PEFT.
Advancing Radiograph Representation Learning with Masked Record Modeling
Feb 15, 2023



Modern studies in radiograph representation learning rely on either self-supervision to encode invariant semantics or associated radiology reports to incorporate medical expertise, while the complementarity between them is barely noticed. To explore this, we formulate the self- and report-completion as two complementary objectives and present a unified framework based on masked record modeling (MRM). In practice, MRM reconstructs masked image patches and masked report tokens following a multi-task scheme to learn knowledge-enhanced semantic representations. With MRM pre-training, we obtain pre-trained models that can be well transferred to various radiography tasks. Specifically, we find that MRM offers superior performance in label-efficient fine-tuning. For instance, MRM achieves 88.5% mean AUC on CheXpert using 1% labeled data, outperforming previous R$^2$L methods with 100% labels. On NIH ChestX-ray, MRM outperforms the best performing counterpart by about 3% under small labeling ratios. Besides, MRM surpasses self- and report-supervised pre-training in identifying the pneumonia type and the pneumothorax area, sometimes by large margins.
Breaking the Dilemma of Medical Image-to-image Translation
Oct 13, 2021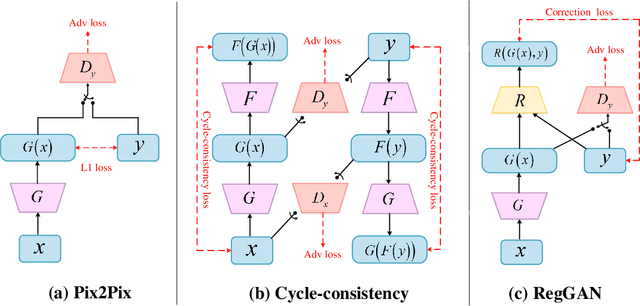
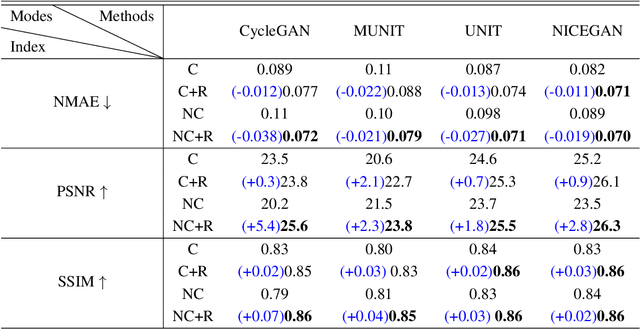
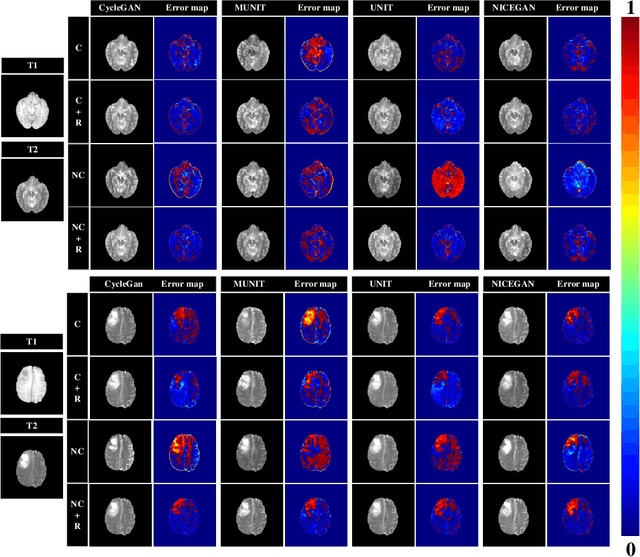
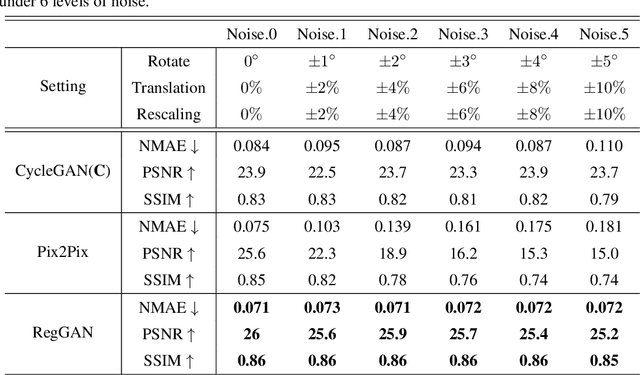
Supervised Pix2Pix and unsupervised Cycle-consistency are two modes that dominate the field of medical image-to-image translation. However, neither modes are ideal. The Pix2Pix mode has excellent performance. But it requires paired and well pixel-wise aligned images, which may not always be achievable due to respiratory motion or anatomy change between times that paired images are acquired. The Cycle-consistency mode is less stringent with training data and works well on unpaired or misaligned images. But its performance may not be optimal. In order to break the dilemma of the existing modes, we propose a new unsupervised mode called RegGAN for medical image-to-image translation. It is based on the theory of "loss-correction". In RegGAN, the misaligned target images are considered as noisy labels and the generator is trained with an additional registration network to fit the misaligned noise distribution adaptively. The goal is to search for the common optimal solution to both image-to-image translation and registration tasks. We incorporated RegGAN into a few state-of-the-art image-to-image translation methods and demonstrated that RegGAN could be easily combined with these methods to improve their performances. Such as a simple CycleGAN in our mode surpasses latest NICEGAN even though using less network parameters. Based on our results, RegGAN outperformed both Pix2Pix on aligned data and Cycle-consistency on misaligned or unpaired data. RegGAN is insensitive to noises which makes it a better choice for a wide range of scenarios, especially for medical image-to-image translation tasks in which well pixel-wise aligned data are not available