 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
AD-CARE: A Guideline-grounded, Modality-agnostic LLM Agent for Real-world Alzheimer's Disease Diagnosis with Multi-cohort Assessment, Fairness Analysis, and Reader Study
Mar 26, 2026Alzheimer's disease (AD) is a growing global health challenge as populations age, and timely, accurate diagnosis is essential to reduce individual and societal burden. However, real-world AD assessment is hampered by incomplete, heterogeneous multimodal data and variability across sites and patient demographics. Although large language models (LLMs) have shown promise in biomedicine, their use in AD has largely been confined to answering narrow, disease-specific questions rather than generating comprehensive diagnostic reports that support clinical decision-making. Here we expand LLM capabilities for clinical decision support by introducing AD-CARE, a modality-agnostic agent that performs guideline-grounded diagnostic assessment from incomplete, heterogeneous inputs without imputing missing modalities. By dynamically orchestrating specialized diagnostic tools and embedding clinical guidelines into LLM-driven reasoning, AD-CARE generates transparent, report-style outputs aligned with real-world clinical workflows. Across six cohorts comprising 10,303 cases, AD-CARE achieved 84.9% diagnostic accuracy, delivering 4.2%-13.7% relative improvements over baseline methods. Despite cohort-level differences, dataset-specific accuracies remain robust (80.4%-98.8%), and the agent consistently outperforms all baselines. AD-CARE reduced performance disparities across racial and age subgroups, decreasing the average dispersion of four metrics by 21%-68% and 28%-51%, respectively. In a controlled reader study, the agent improved neurologist and radiologist accuracy by 6%-11% and more than halved decision time. The framework yielded 2.29%-10.66% absolute gains over eight backbone LLMs and converges their performance. These results show that AD-CARE is a scalable, practically deployable framework that can be integrated into routine clinical workflows for multimodal decision support in AD.
Moving Beyond Functional Connectivity: Time-Series Modeling for fMRI-Based Brain Disorder Classification
Feb 09, 2026Functional magnetic resonance imaging (fMRI) enables non-invasive brain disorder classification by capturing blood-oxygen-level-dependent (BOLD) signals. However, most existing methods rely on functional connectivity (FC) via Pearson correlation, which reduces 4D BOLD signals to static 2D matrices, discarding temporal dynamics and capturing only linear inter-regional relationships. In this work, we benchmark state-of-the-art temporal models (e.g., time-series models such as PatchTST, TimesNet, and TimeMixer) on raw BOLD signals across five public datasets. Results show these models consistently outperform traditional FC-based approaches, highlighting the value of directly modeling temporal information such as cycle-like oscillatory fluctuations and drift-like slow baseline trends. Building on this insight, we propose DeCI, a simple yet effective framework that integrates two key principles: (i) Cycle and Drift Decomposition to disentangle cycle and drift within each ROI (Region of Interest); and (ii) Channel-Independence to model each ROI separately, improving robustness and reducing overfitting. Extensive experiments demonstrate that DeCI achieves superior classification accuracy and generalization compared to both FC-based and temporal baselines. Our findings advocate for a shift toward end-to-end temporal modeling in fMRI analysis to better capture complex brain dynamics. The code is available at https://github.com/Levi-Ackman/DeCI.
Guided by the Plan: Enhancing Faithful Autoregressive Text-to-Audio Generation with Guided Decoding
Jan 18, 2026Autoregressive (AR) models excel at generating temporally coherent audio by producing tokens sequentially, yet they often falter in faithfully following complex textual prompts, especially those describing complex sound events. We uncover a surprising capability in AR audio generators: their early prefix tokens implicitly encode global semantic attributes of the final output, such as event count and sound-object category, revealing a form of implicit planning. Building on this insight, we propose Plan-Critic, a lightweight auxiliary model trained with a Generalized Advantage Estimation (GAE)-inspired objective to predict final instruction-following quality from partial generations. At inference time, Plan-Critic enables guided exploration: it evaluates candidate prefixes early, prunes low-fidelity trajectories, and reallocates computation to high-potential planning seeds. Our Plan-Critic-guided sampling achieves up to a 10-point improvement in CLAP score over the AR baseline-establishing a new state of the art in AR text-to-audio generation-while maintaining computational parity with standard best-of-N decoding. This work bridges the gap between causal generation and global semantic alignment, demonstrating that even strictly autoregressive models can plan ahead.
JMedEthicBench: A Multi-Turn Conversational Benchmark for Evaluating Medical Safety in Japanese Large Language Models
Jan 04, 2026As Large Language Models (LLMs) are increasingly deployed in healthcare field, it becomes essential to carefully evaluate their medical safety before clinical use. However, existing safety benchmarks remain predominantly English-centric, and test with only single-turn prompts despite multi-turn clinical consultations. To address these gaps, we introduce JMedEthicBench, the first multi-turn conversational benchmark for evaluating medical safety of LLMs for Japanese healthcare. Our benchmark is based on 67 guidelines from the Japan Medical Association and contains over 50,000 adversarial conversations generated using seven automatically discovered jailbreak strategies. Using a dual-LLM scoring protocol, we evaluate 27 models and find that commercial models maintain robust safety while medical-specialized models exhibit increased vulnerability. Furthermore, safety scores decline significantly across conversation turns (median: 9.5 to 5.0, $p < 0.001$). Cross-lingual evaluation on both Japanese and English versions of our benchmark reveals that medical model vulnerabilities persist across languages, indicating inherent alignment limitations rather than language-specific factors. These findings suggest that domain-specific fine-tuning may accidentally weaken safety mechanisms and that multi-turn interactions represent a distinct threat surface requiring dedicated alignment strategies.
Think Before You Move: Latent Motion Reasoning for Text-to-Motion Generation
Dec 30, 2025Current state-of-the-art paradigms predominantly treat Text-to-Motion (T2M) generation as a direct translation problem, mapping symbolic language directly to continuous poses. While effective for simple actions, this System 1 approach faces a fundamental theoretical bottleneck we identify as the Semantic-Kinematic Impedance Mismatch: the inherent difficulty of grounding semantically dense, discrete linguistic intent into kinematically dense, high-frequency motion data in a single shot. In this paper, we argue that the solution lies in an architectural shift towards Latent System 2 Reasoning. Drawing inspiration from Hierarchical Motor Control in cognitive science, we propose Latent Motion Reasoning (LMR) that reformulates generation as a two-stage Think-then-Act decision process. Central to LMR is a novel Dual-Granularity Tokenizer that disentangles motion into two distinct manifolds: a compressed, semantically rich Reasoning Latent for planning global topology, and a high-frequency Execution Latent for preserving physical fidelity. By forcing the model to autoregressively reason (plan the coarse trajectory) before it moves (instantiates the frames), we effectively bridge the ineffability gap between language and physics. We demonstrate LMR's versatility by implementing it for two representative baselines: T2M-GPT (discrete) and MotionStreamer (continuous). Extensive experiments show that LMR yields non-trivial improvements in both semantic alignment and physical plausibility, validating that the optimal substrate for motion planning is not natural language, but a learned, motion-aligned concept space. Codes and demos can be found in \hyperlink{https://chenhaoqcdyq.github.io/LMR/}{https://chenhaoqcdyq.github.io/LMR/}
An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
Ada-FCN: Adaptive Frequency-Coupled Network for fMRI-Based Brain Disorder Classification
Nov 16, 2025Resting-state fMRI has become a valuable tool for classifying brain disorders and constructing brain functional connectivity networks by tracking BOLD signals across brain regions. However, existing mod els largely neglect the multi-frequency nature of neuronal oscillations, treating BOLD signals as monolithic time series. This overlooks the cru cial fact that neurological disorders often manifest as disruptions within specific frequency bands, limiting diagnostic sensitivity and specificity. While some methods have attempted to incorporate frequency informa tion, they often rely on predefined frequency bands, which may not be optimal for capturing individual variability or disease-specific alterations. To address this, we propose a novel framework featuring Adaptive Cas cade Decomposition to learn task-relevant frequency sub-bands for each brain region and Frequency-Coupled Connectivity Learning to capture both intra- and nuanced cross-band interactions in a unified functional network. This unified network informs a novel message-passing mecha nism within our Unified-GCN, generating refined node representations for diagnostic prediction. Experimental results on the ADNI and ABIDE datasets demonstrate superior performance over existing methods. The code is available at https://github.com/XXYY20221234/Ada-FCN.
* MICCAI2025
Medical Knowledge Intervention Prompt Tuning for Medical Image Classification
Nov 16, 2025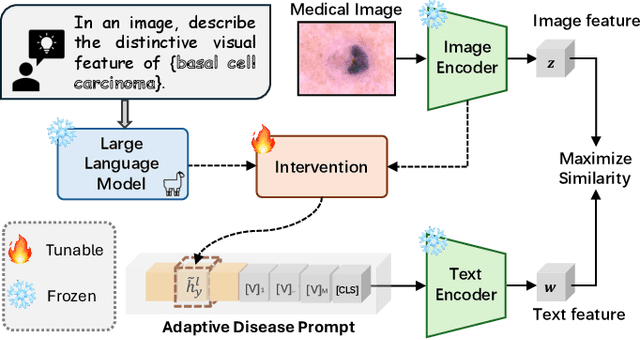
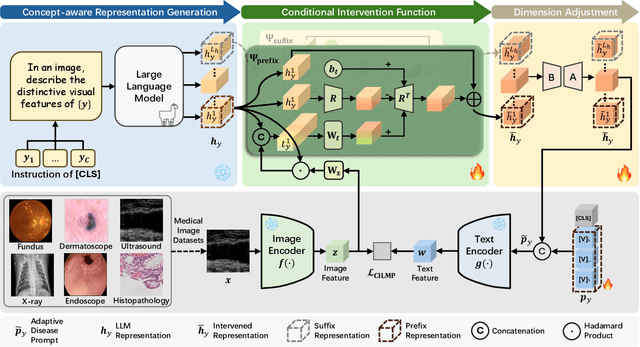
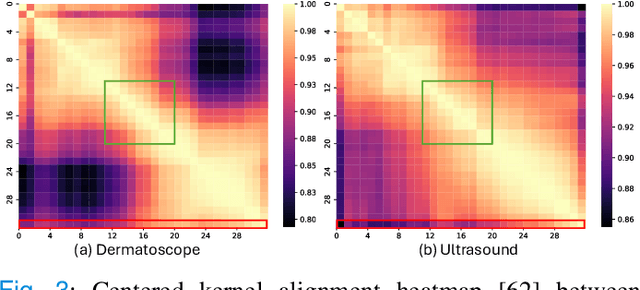
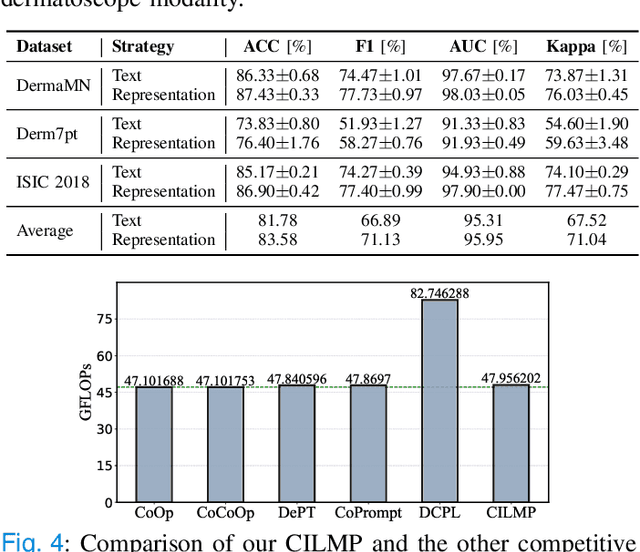
Vision-language foundation models (VLMs) have shown great potential in feature transfer and generalization across a wide spectrum of medical-related downstream tasks. However, fine-tuning these models is resource-intensive due to their large number of parameters. Prompt tuning has emerged as a viable solution to mitigate memory usage and reduce training time while maintaining competitive performance. Nevertheless, the challenge is that existing prompt tuning methods cannot precisely distinguish different kinds of medical concepts, which miss essentially specific disease-related features across various medical imaging modalities in medical image classification tasks. We find that Large Language Models (LLMs), trained on extensive text corpora, are particularly adept at providing this specialized medical knowledge. Motivated by this, we propose incorporating LLMs into the prompt tuning process. Specifically, we introduce the CILMP, Conditional Intervention of Large Language Models for Prompt Tuning, a method that bridges LLMs and VLMs to facilitate the transfer of medical knowledge into VLM prompts. CILMP extracts disease-specific representations from LLMs, intervenes within a low-rank linear subspace, and utilizes them to create disease-specific prompts. Additionally, a conditional mechanism is incorporated to condition the intervention process on each individual medical image, generating instance-adaptive prompts and thus enhancing adaptability. Extensive experiments across diverse medical image datasets demonstrate that CILMP consistently outperforms state-of-the-art prompt tuning methods, demonstrating its effectiveness. Code is available at https://github.com/usr922/cilmp.
Exploring Scale Shift in Crowd Localization under the Context of Domain Generalization
Oct 22, 2025Crowd localization plays a crucial role in visual scene understanding towards predicting each pedestrian location in a crowd, thus being applicable to various downstream tasks. However, existing approaches suffer from significant performance degradation due to discrepancies in head scale distributions (scale shift) between training and testing data, a challenge known as domain generalization (DG). This paper aims to comprehend the nature of scale shift within the context of domain generalization for crowd localization models. To this end, we address four critical questions: (i) How does scale shift influence crowd localization in a DG scenario? (ii) How can we quantify this influence? (iii) What causes this influence? (iv) How to mitigate the influence? Initially, we conduct a systematic examination of how crowd localization performance varies with different levels of scale shift. Then, we establish a benchmark, ScaleBench, and reproduce 20 advanced DG algorithms to quantify the influence. Through extensive experiments, we demonstrate the limitations of existing algorithms and underscore the importance and complexity of scale shift, a topic that remains insufficiently explored. To deepen our understanding, we provide a rigorous theoretical analysis on scale shift. Building on these insights, we further propose an effective algorithm called Causal Feature Decomposition and Anisotropic Processing (Catto) to mitigate the influence of scale shift in DG settings. Later, we also provide extensive analytical experiments, revealing four significant insights for future research. Our results emphasize the importance of this novel and applicable research direction, which we term Scale Shift Domain Generalization.