 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourierPET: Deep Fourier-based Unrolled Network for Low-count PET Reconstruction
Jan 16, 2026Low-count positron emission tomography (PET) reconstruction is a challenging inverse problem due to severe degradations arising from Poisson noise, photon scarcity, and attenuation correction errors. Existing deep learning methods typically address these in the spatial domain with an undifferentiated optimization objective, making it difficult to disentangle overlapping artifacts and limiting correction effectiveness. In this work, we perform a Fourier-domain analysis and reveal that these degradations are spectrally separable: Poisson noise and photon scarcity cause high-frequency phase perturbations, while attenuation errors suppress low-frequency amplitude components. Leveraging this insight, we propose FourierPET, a Fourier-based unrolled reconstruction framework grounded in the Alternating Direction Method of Multipliers. It consists of three tailored modules: a spectral consistency module that enforces global frequency alignment to maintain data fidelity, an amplitude-phase correction module that decouples and compensates for high-frequency phase distortions and low-frequency amplitude suppression, and a dual adjustment module that accelerates convergence during iterative reconstruction. Extensive experiments demonstrate that FourierPET achieves state-of-the-art performance with significantly fewer parameters, while offering enhanced interpretability through frequency-aware correction.
Prompt Guiding Multi-Scale Adaptive Sparse Representation-driven Network for Low-Dose CT MAR
Apr 28, 2025Low-dose CT (LDCT) is capable of reducing X-ray radiation exposure, but it will potentially degrade image quality, even yields metal artifacts at the case of metallic implants. For simultaneous LDCT reconstruction and metal artifact reduction (LDMAR), existing deep learning-based efforts face two main limitations: i) the network design neglects multi-scale and within-scale information; ii) training a distinct model for each dose necessitates significant storage space for multiple doses. To fill these gaps, we propose a prompt guiding multi-scale adaptive sparse representation-driven network, abbreviated as PMSRNet, for LDMAR task. Specifically, we construct PMSRNet inspired from multi-scale sparsifying frames, and it can simultaneously employ within-scale characteristics and cross-scale complementarity owing to an elaborated prompt guiding scale-adaptive threshold generator (PSATG) and a built multi-scale coefficient fusion module (MSFuM). The PSATG can adaptively capture multiple contextual information to generate more faithful thresholds, achieved by fusing features from local, regional, and global levels. Furthermore, we elaborate a model interpretable dual domain LDMAR framework called PDuMSRNet, and train single model with a prompt guiding strategy for multiple dose levels. We build a prompt guiding module, whose input contains dose level, metal mask and input instance, to provide various guiding information, allowing a single model to accommodate various CT dose settings. Extensive experiments at various dose levels demonstrate that the proposed methods outperform the state-of-the-art LDMAR methods.
MMR-Mamba: Multi-Modal MRI Reconstruction with Mamba and Spatial-Frequency Information Fusion
Jul 07, 2024Multi-modal MRI offers valuable complementary information for diagnosis and treatment; however, its utility is limited by prolonged scanning times. To accelerate the acquisition process, a practical approach is to reconstruct images of the target modality, which requires longer scanning times, from under-sampled k-space data using the fully-sampled reference modality with shorter scanning times as guidance. The primary challenge of this task is comprehensively and efficiently integrating complementary information from different modalities to achieve high-quality reconstruction. Existing methods struggle with this: 1) convolution-based models fail to capture long-range dependencies; 2) transformer-based models, while excelling in global feature modeling, struggle with quadratic computational complexity. To address this, we propose MMR-Mamba, a novel framework that thoroughly and efficiently integrates multi-modal features for MRI reconstruction, leveraging Mamba's capability to capture long-range dependencies with linear computational complexity while exploiting global properties of the Fourier domain. Specifically, we first design a Target modality-guided Cross Mamba (TCM) module in the spatial domain, which maximally restores the target modality information by selectively incorporating relevant information from the reference modality. Then, we introduce a Selective Frequency Fusion (SFF) module to efficiently integrate global information in the Fourier domain and recover high-frequency signals for the reconstruction of structural details. Furthermore, we devise an Adaptive Spatial-Frequency Fusion (ASFF) module, which mutually enhances the spatial and frequency domains by supplementing less informative channels from one domain with corresponding channels from the other.
Synthesizing PET images from High-field and Ultra-high-field MR images Using Joint Diffusion Attention Model
May 06, 2023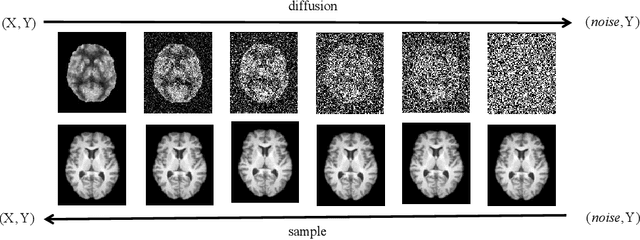
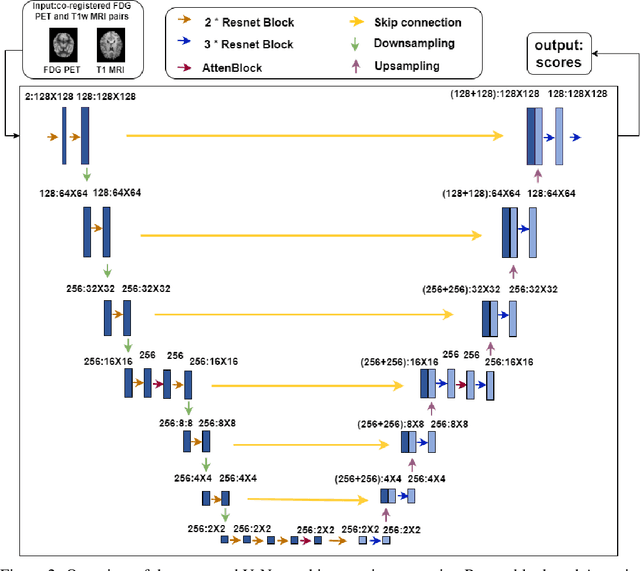
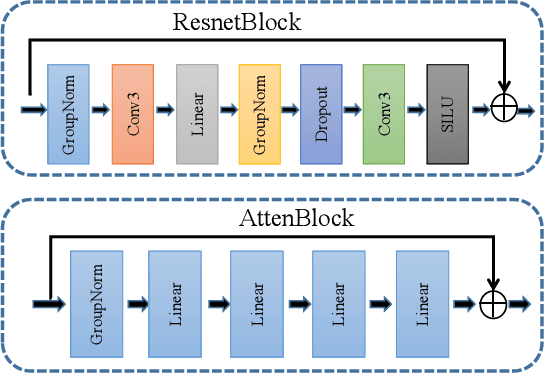
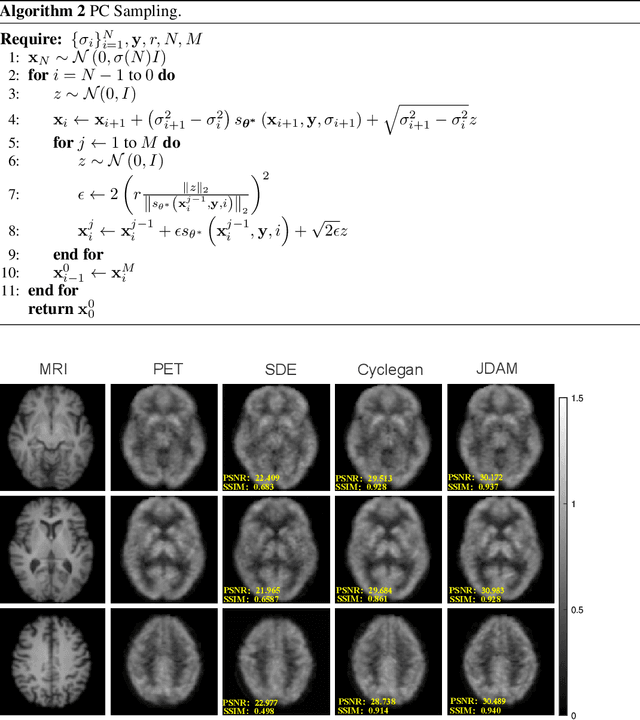
MRI and PET are crucial diagnostic tools for brain diseases, as they provide complementary information on brain structure and function. However, PET scanning is costly and involves radioactive exposure, resulting in a lack of PET. Moreover, simultaneous PET and MRI at ultra-high-field are currently hardly infeasible. Ultra-high-field imaging has unquestionably proven valuable in both clinical and academic settings, especially in the field of cognitive neuroimaging. These motivate us to propose a method for synthetic PET from high-filed MRI and ultra-high-field MRI. From a statistical perspective, the joint probability distribution (JPD) is the most direct and fundamental means of portraying the correlation between PET and MRI. This paper proposes a novel joint diffusion attention model which has the joint probability distribution and attention strategy, named JDAM. JDAM has a diffusion process and a sampling process. The diffusion process involves the gradual diffusion of PET to Gaussian noise by adding Gaussian noise, while MRI remains fixed. JPD of MRI and noise-added PET was learned in the diffusion process. The sampling process is a predictor-corrector. PET images were generated from MRI by JPD of MRI and noise-added PET. The predictor is a reverse diffusion process and the corrector is Langevin dynamics. Experimental results on the public Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate that the proposed method outperforms state-of-the-art CycleGAN for high-field MRI (3T MRI). Finally, synthetic PET images from the ultra-high-field (5T MRI and 7T MRI) be attempted, providing a possibility for ultra-high-field PET-MRI imaging.
Total-Body Low-Dose CT Image Denoising using Prior Knowledge Transfer Technique with Contrastive Regularization Mechanism
Dec 06, 2021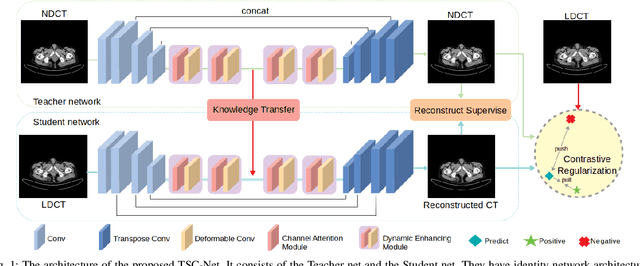
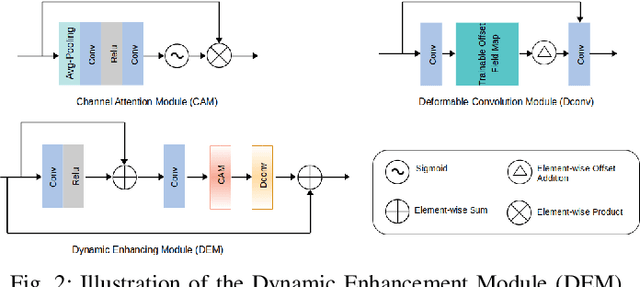

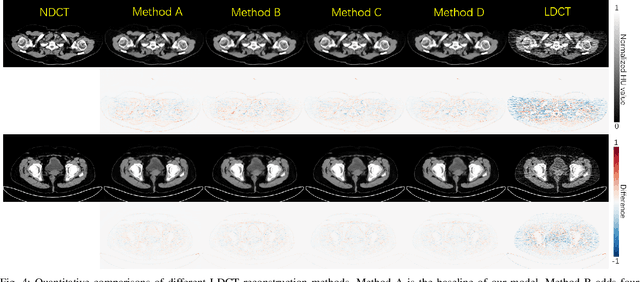
Reducing the radiation exposure for patients in Total-body CT scans has attracted extensive attention in the medical imaging community. Given the fact that low radiation dose may result in increased noise and artifacts, which greatly affected the clinical diagnosis. To obtain high-quality Total-body Low-dose CT (LDCT) images, previous deep-learning-based research work has introduced various network architectures. However, most of these methods only adopt Normal-dose CT (NDCT) images as ground truths to guide the training of the denoising network. Such simple restriction leads the model to less effectiveness and makes the reconstructed images suffer from over-smoothing effects. In this paper, we propose a novel intra-task knowledge transfer method that leverages the distilled knowledge from NDCT images to assist the training process on LDCT images. The derived architecture is referred to as the Teacher-Student Consistency Network (TSC-Net), which consists of the teacher network and the student network with identical architecture. Through the supervision between intermediate features, the student network is encouraged to imitate the teacher network and gain abundant texture details. Moreover, to further exploit the information contained in CT scans, a contrastive regularization mechanism (CRM) built upon contrastive learning is introduced.CRM performs to pull the restored CT images closer to the NDCT samples and push far away from the LDCT samples in the latent space. In addition, based on the attention and deformable convolution mechanism, we design a Dynamic Enhancement Module (DEM) to improve the network transformation capability.