 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalist Foundation Model for Total-body PET/CT Enables Diagnostic Reporting and System-wide Metabolic Profiling
Jan 19, 2026Total-body PET/CT enables system-wide molecular imaging, but heterogeneous anatomical and metabolic signals, approximately 2 m axial coverage, and structured radiology semantics challenge existing medical AI models that assume single-modality inputs, localized fields of view, and coarse image-text alignment. We introduce SDF-HOLO (Systemic Dual-stream Fusion Holo Model), a multimodal foundation model for holistic total-body PET/CT, pre-trained on more than 10,000 patients. SDF-HOLO decouples CT and PET representation learning with dual-stream encoders and couples them through a cross-modal interaction module, allowing anatomical context to refine PET aggregation while metabolic saliency guides subtle morphological reasoning. To model long-range dependencies across the body, hierarchical context modeling combines efficient local windows with global attention. To bridge voxels and clinical language, we use anatomical segmentation masks as explicit semantic anchors and perform voxel-mask-text alignment during pre-training. Across tumor segmentation, low-dose lesion detection, and multilingual diagnostic report generation, SDF-HOLO outperforms strong task-specific and clinical-reference baselines while reducing localization errors and hallucinated findings. Beyond focal interpretation, the model enables system-wide metabolic profiling and reveals tumor-associated fingerprints of inter-organ metabolic network interactions, providing a scalable computational foundation for total-body PET/CT diagnostics and system-level precision oncology.
Modality-Projection Universal Model for Comprehensive Full-Body Medical Imaging Segmentation
Dec 26, 2024The integration of deep learning in medical imaging has shown great promise for enhancing diagnostic, therapeutic, and research outcomes. However, applying universal models across multiple modalities remains challenging due to the inherent variability in data characteristics. This study aims to introduce and evaluate a Modality Projection Universal Model (MPUM). MPUM employs a novel modality-projection strategy, which allows the model to dynamically adjust its parameters to optimize performance across different imaging modalities. The MPUM demonstrated superior accuracy in identifying anatomical structures, enabling precise quantification for improved clinical decision-making. It also identifies metabolic associations within the brain-body axis, advancing research on brain-body physiological correlations. Furthermore, MPUM's unique controller-based convolution layer enables visualization of saliency maps across all network layers, significantly enhancing the model's interpretability.
Total-Body Low-Dose CT Image Denoising using Prior Knowledge Transfer Technique with Contrastive Regularization Mechanism
Dec 06, 2021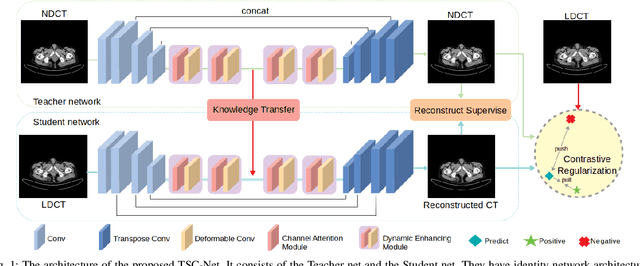
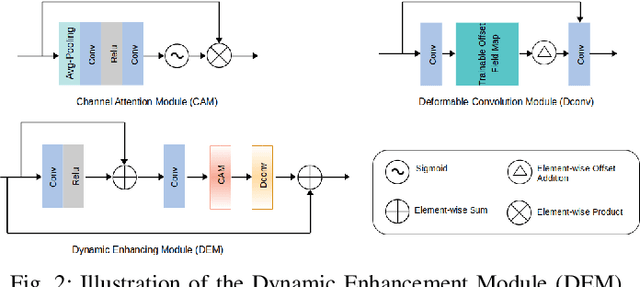

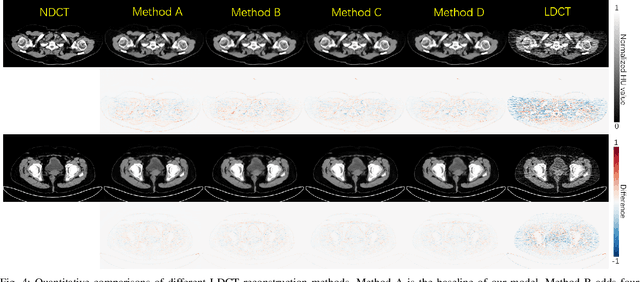
Reducing the radiation exposure for patients in Total-body CT scans has attracted extensive attention in the medical imaging community. Given the fact that low radiation dose may result in increased noise and artifacts, which greatly affected the clinical diagnosis. To obtain high-quality Total-body Low-dose CT (LDCT) images, previous deep-learning-based research work has introduced various network architectures. However, most of these methods only adopt Normal-dose CT (NDCT) images as ground truths to guide the training of the denoising network. Such simple restriction leads the model to less effectiveness and makes the reconstructed images suffer from over-smoothing effects. In this paper, we propose a novel intra-task knowledge transfer method that leverages the distilled knowledge from NDCT images to assist the training process on LDCT images. The derived architecture is referred to as the Teacher-Student Consistency Network (TSC-Net), which consists of the teacher network and the student network with identical architecture. Through the supervision between intermediate features, the student network is encouraged to imitate the teacher network and gain abundant texture details. Moreover, to further exploit the information contained in CT scans, a contrastive regularization mechanism (CRM) built upon contrastive learning is introduced.CRM performs to pull the restored CT images closer to the NDCT samples and push far away from the LDCT samples in the latent space. In addition, based on the attention and deformable convolution mechanism, we design a Dynamic Enhancement Module (DEM) to improve the network transformation capability.