 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianFluent: Gaussian Simulation for Dynamic Scenes with Mixed Materials
Jan 14, 20263D Gaussian Splatting (3DGS) has emerged as a prominent 3D representation for high-fidelity and real-time rendering. Prior work has coupled physics simulation with Gaussians, but predominantly targets soft, deformable materials, leaving brittle fracture largely unresolved. This stems from two key obstacles: the lack of volumetric interiors with coherent textures in GS representation, and the absence of fracture-aware simulation methods for Gaussians. To address these challenges, we introduce GaussianFluent, a unified framework for realistic simulation and rendering of dynamic object states. First, it synthesizes photorealistic interiors by densifying internal Gaussians guided by generative models. Second, it integrates an optimized Continuum Damage Material Point Method (CD-MPM) to enable brittle fracture simulation at remarkably high speed. Our approach handles complex scenarios including mixed-material objects and multi-stage fracture propagation, achieving results infeasible with previous methods. Experiments clearly demonstrate GaussianFluent's capability for photo-realistic, real-time rendering with structurally consistent interiors, highlighting its potential for downstream application, such as VR and Robotics.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
3D Scene Change Modeling With Consistent Multi-View Aggregation
Dec 28, 2025Change detection plays a vital role in scene monitoring, exploration, and continual reconstruction. Existing 3D change detection methods often exhibit spatial inconsistency in the detected changes and fail to explicitly separate pre- and post-change states. To address these limitations, we propose SCaR-3D, a novel 3D scene change detection framework that identifies object-level changes from a dense-view pre-change image sequence and sparse-view post-change images. Our approach consists of a signed-distance-based 2D differencing module followed by multi-view aggregation with voting and pruning, leveraging the consistent nature of 3DGS to robustly separate pre- and post-change states. We further develop a continual scene reconstruction strategy that selectively updates dynamic regions while preserving the unchanged areas. We also contribute CCS3D, a challenging synthetic dataset that allows flexible combinations of 3D change types to support controlled evaluations. Extensive experiments demonstrate that our method achieves both high accuracy and efficiency, outperforming existing methods.
Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and Understanding
Dec 25, 2025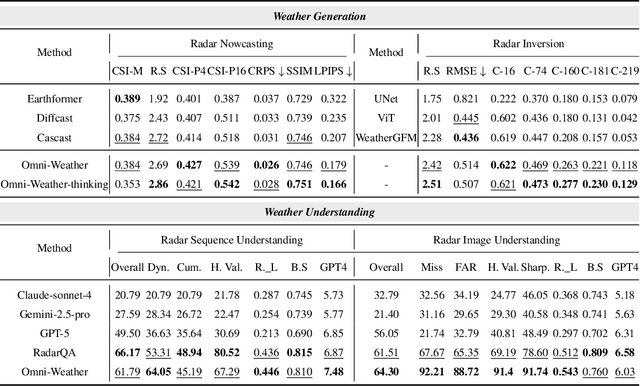
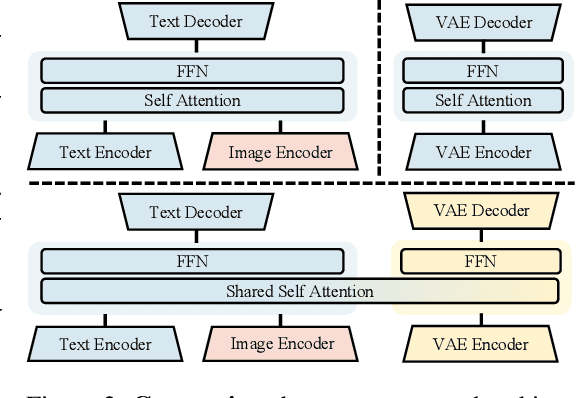
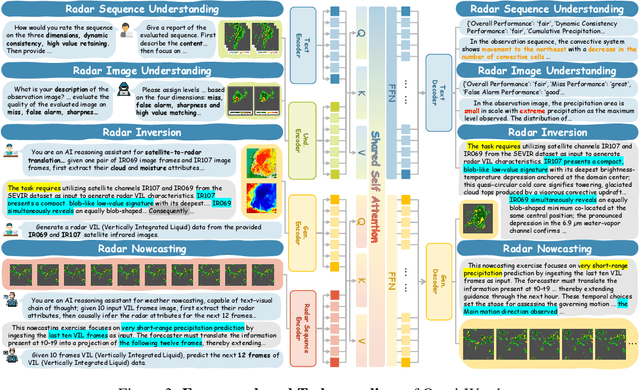

Weather modeling requires both accurate prediction and mechanistic interpretation, yet existing methods treat these goals in isolation, separating generation from understanding. To address this gap, we present Omni-Weather, the first multimodal foundation model that unifies weather generation and understanding within a single architecture. Omni-Weather integrates a radar encoder for weather generation tasks, followed by unified processing using a shared self-attention mechanism. Moreover, we construct a Chain-of-Thought dataset for causal reasoning in weather generation, enabling interpretable outputs and improved perceptual quality. Extensive experiments show Omni-Weather achieves state-of-the-art performance in both weather generation and understanding. Our findings further indicate that generative and understanding tasks in the weather domain can mutually enhance each other. Omni-Weather also demonstrates the feasibility and value of unifying weather generation and understanding.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
GRIP: In-Parameter Graph Reasoning through Fine-Tuning Large Language Models
Nov 06, 2025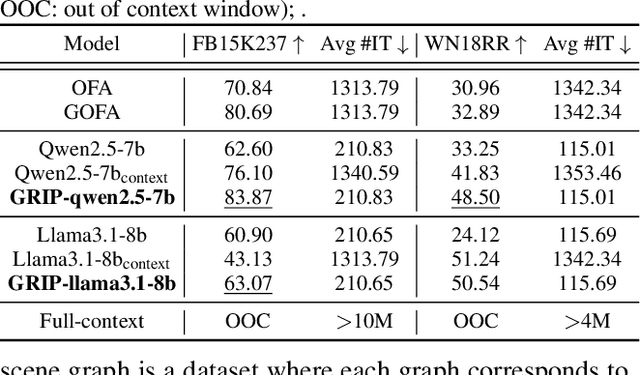
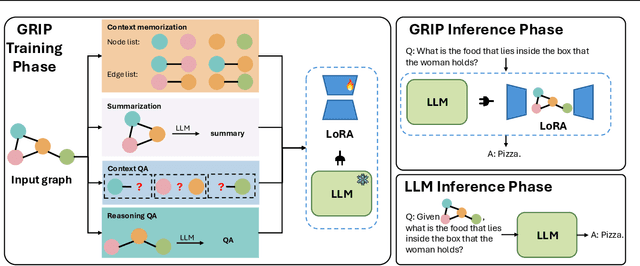
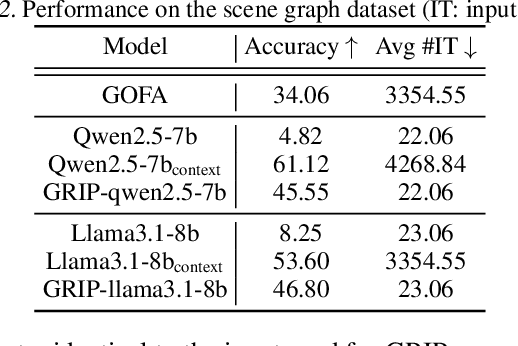
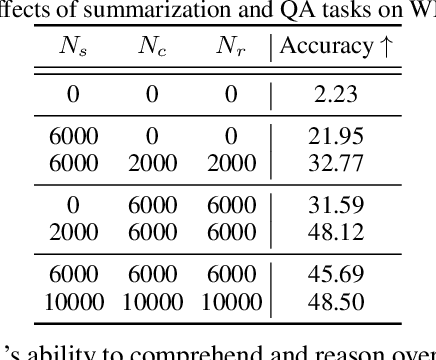
Large Language Models (LLMs) have demonstrated remarkable capabilities in modeling sequential textual data and generalizing across diverse tasks. However, adapting LLMs to effectively handle structural data, such as knowledge graphs or web data, remains a challenging problem. Some approaches adopt complex strategies to convert graphs into text sequences, resulting in significant token overhead and rendering them impractical for large-scale graphs. Others introduce additional modules to encode graphs into fixed-size token representations for LLMs. However, these methods typically require large-scale post-training on graph-text corpus and complex alignment procedures, yet often yield sub-optimal results due to poor modality alignment. Inspired by in-parameter knowledge injection for test-time adaptation of LLMs, we propose GRIP, a novel framework that equips LLMs with the ability to internalize complex relational information from graphs through carefully designed fine-tuning tasks. This knowledge is efficiently stored within lightweight LoRA parameters, enabling the fine-tuned LLM to perform a wide range of graph-related tasks without requiring access to the original graph at inference time. Extensive experiments across multiple benchmarks validate the effectiveness and efficiency of our approach.
Round-trip Reinforcement Learning: Self-Consistent Training for Better Chemical LLMs
Oct 01, 2025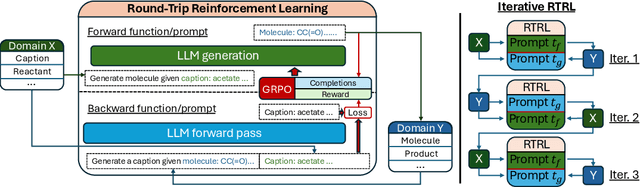
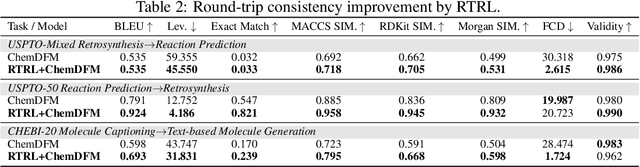
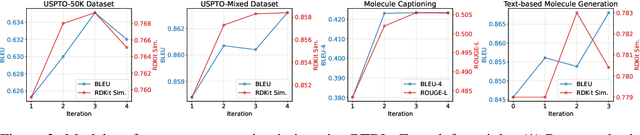
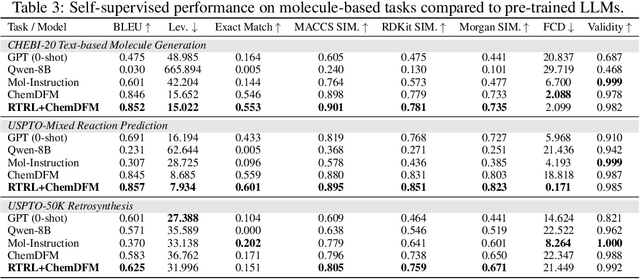
Large Language Models (LLMs) are emerging as versatile foundation models for computational chemistry, handling bidirectional tasks like reaction prediction and retrosynthesis. However, these models often lack round-trip consistency. For instance, a state-of-the-art chemical LLM may successfully caption a molecule, yet be unable to accurately reconstruct the original structure from its own generated text. This inconsistency suggests that models are learning unidirectional memorization rather than flexible mastery. Indeed, recent work has demonstrated a strong correlation between a model's round-trip consistency and its performance on the primary tasks. This strong correlation reframes consistency into a direct target for model improvement. We therefore introduce Round-Trip Reinforcement Learning (RTRL), a novel framework that trains a model to improve its consistency by using the success of a round-trip transformation as a reward signal. We further propose an iterative variant where forward and reverse mappings alternately train each other in a self-improvement loop, a process that is highly data-efficient and notably effective with the massive amount of unlabelled data common in chemistry. Experiments demonstrate that RTRL significantly \textbf{boosts performance and consistency} over strong baselines across supervised, self-supervised, and synthetic data regimes. This work shows that round-trip consistency is not just a desirable property but a trainable objective, offering a new path toward more robust and reliable foundation models.
Addressing accuracy and hallucination of LLMs in Alzheimer's disease research through knowledge graphs
Aug 28, 2025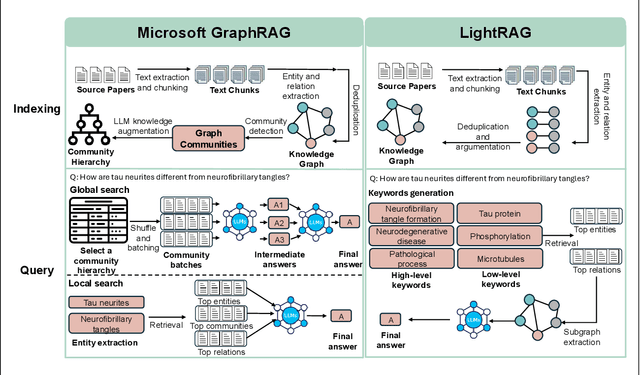
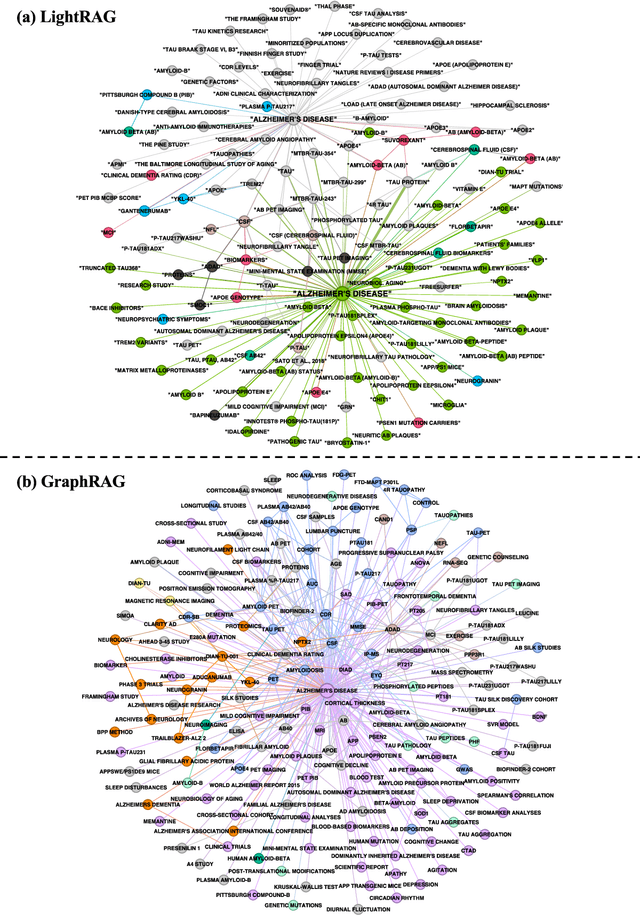


In the past two years, large language model (LLM)-based chatbots, such as ChatGPT, have revolutionized various domains by enabling diverse task completion and question-answering capabilities. However, their application in scientific research remains constrained by challenges such as hallucinations, limited domain-specific knowledge, and lack of explainability or traceability for the response. Graph-based Retrieval-Augmented Generation (GraphRAG) has emerged as a promising approach to improving chatbot reliability by integrating domain-specific contextual information before response generation, addressing some limitations of standard LLMs. Despite its potential, there are only limited studies that evaluate GraphRAG on specific domains that require intensive knowledge, like Alzheimer's disease or other biomedical domains. In this paper, we assess the quality and traceability of two popular GraphRAG systems. We compile a database of 50 papers and 70 expert questions related to Alzheimer's disease, construct a GraphRAG knowledge base, and employ GPT-4o as the LLM for answering queries. We then compare the quality of responses generated by GraphRAG with those from a standard GPT-4o model. Additionally, we discuss and evaluate the traceability of several Retrieval-Augmented Generation (RAG) and GraphRAG systems. Finally, we provide an easy-to-use interface with a pre-built Alzheimer's disease database for researchers to test the performance of both standard RAG and GraphRAG.
GWM: Towards Scalable Gaussian World Models for Robotic Manipulation
Aug 25, 2025



Training robot policies within a learned world model is trending due to the inefficiency of real-world interactions. The established image-based world models and policies have shown prior success, but lack robust geometric information that requires consistent spatial and physical understanding of the three-dimensional world, even pre-trained on internet-scale video sources. To this end, we propose a novel branch of world model named Gaussian World Model (GWM) for robotic manipulation, which reconstructs the future state by inferring the propagation of Gaussian primitives under the effect of robot actions. At its core is a latent Diffusion Transformer (DiT) combined with a 3D variational autoencoder, enabling fine-grained scene-level future state reconstruction with Gaussian Splatting. GWM can not only enhance the visual representation for imitation learning agent by self-supervised future prediction training, but can serve as a neural simulator that supports model-based reinforcement learning. Both simulated and real-world experiments depict that GWM can precisely predict future scenes conditioned on diverse robot actions, and can be further utilized to train policies that outperform the state-of-the-art by impressive margins, showcasing the initial data scaling potential of 3D world model.
Beyond Semantic Similarity: Reducing Unnecessary API Calls via Behavior-Aligned Retriever
Aug 20, 2025Tool-augmented large language models (LLMs) leverage external functions to extend their capabilities, but inaccurate function calls can lead to inefficiencies and increased costs.Existing methods address this challenge by fine-tuning LLMs or using demonstration-based prompting, yet they often suffer from high training overhead and fail to account for inconsistent demonstration samples, which misguide the model's invocation behavior. In this paper, we trained a behavior-aligned retriever (BAR), which provides behaviorally consistent demonstrations to help LLMs make more accurate tool-using decisions. To train the BAR, we construct a corpus including different function-calling behaviors, i.e., calling or non-calling.We use the contrastive learning framework to train the BAR with customized positive/negative pairs and a dual-negative contrastive loss, ensuring robust retrieval of behaviorally consistent examples.Experiments demonstrate that our approach significantly reduces erroneous function calls while maintaining high task performance, offering a cost-effective and efficient solution for tool-augmented LLMs.