 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEFL: Prediction-Residual-Guided Rolling Forecasting for Multi-Horizon Time Series
Feb 26, 2026Time series forecasting plays a critical role in domains such as transportation, energy, and meteorology. Despite their success, modern deep forecasting models are typically trained to minimize point-wise prediction loss without leveraging the rich information contained in past prediction residuals from rolling forecasts - residuals that reflect persistent biases, unmodeled patterns, or evolving dynamics. We propose TEFL (Temporal Error Feedback Learning), a unified learning framework that explicitly incorporates these historical residuals into the forecasting pipeline during both training and evaluation. To make this practical in deep multi-step settings, we address three key challenges: (1) selecting observable multi-step residuals under the partial observability of rolling forecasts, (2) integrating them through a lightweight low-rank adapter to preserve efficiency and prevent overfitting, and (3) designing a two-stage training procedure that jointly optimizes the base forecaster and error module. Extensive experiments across 10 real-world datasets and 5 backbone architectures show that TEFL consistently improves accuracy, reducing MAE by 5-10% on average. Moreover, it demonstrates strong robustness under abrupt changes and distribution shifts, with error reductions exceeding 10% (up to 19.5%) in challenging scenarios. By embedding residual-based feedback directly into the learning process, TEFL offers a simple, general, and effective enhancement to modern deep forecasting systems.
Learning from Yesterday's Error: An Efficient Online Learning Method for Traffic Demand Prediction
Feb 25, 2026Accurately predicting short-term traffic demand is critical for intelligent transportation systems. While deep learning models achieve strong performance under stationary conditions, their accuracy often degrades significantly when faced with distribution shifts caused by external events or evolving urban dynamics. Frequent model retraining to adapt to such changes incurs prohibitive computational costs, especially for large-scale or foundation models. To address this challenge, we propose FORESEE (Forecasting Online with Residual Smoothing and Ensemble Experts), a lightweight online adaptation framework that is accurate, robust, and computationally efficient. FORESEE operates without any parameter updates to the base model. Instead, it corrects today's forecast in each region using yesterday's prediction error, stabilized through exponential smoothing guided by a mixture-of-experts mechanism that adapts to recent error dynamics. Moreover, an adaptive spatiotemporal smoothing component propagates error signals across neighboring regions and time slots, capturing coherent shifts in demand patterns. Extensive experiments on seven real-world datasets with three backbone models demonstrate that FORESEE consistently improves prediction accuracy, maintains robustness even when distribution shifts are minimal (avoiding performance degradation), and achieves the lowest computational overhead among existing online methods. By enabling real-time adaptation of traffic forecasting models with negligible computational cost, FORESEE paves the way for deploying reliable, up-to-date prediction systems in dynamic urban environments. Code and data are available at https://github.com/xiannanhuang/FORESEE
Online time series prediction using feature adjustment
Sep 04, 2025Time series forecasting is of significant importance across various domains. However, it faces significant challenges due to distribution shift. This issue becomes particularly pronounced in online deployment scenarios where data arrives sequentially, requiring models to adapt continually to evolving patterns. Current time series online learning methods focus on two main aspects: selecting suitable parameters to update (e.g., final layer weights or adapter modules) and devising suitable update strategies (e.g., using recent batches, replay buffers, or averaged gradients). We challenge the conventional parameter selection approach, proposing that distribution shifts stem from changes in underlying latent factors influencing the data. Consequently, updating the feature representations of these latent factors may be more effective. To address the critical problem of delayed feedback in multi-step forecasting (where true values arrive much later than predictions), we introduce ADAPT-Z (Automatic Delta Adjustment via Persistent Tracking in Z-space). ADAPT-Z utilizes an adapter module that leverages current feature representations combined with historical gradient information to enable robust parameter updates despite the delay. Extensive experiments demonstrate that our method consistently outperforms standard base models without adaptation and surpasses state-of-the-art online learning approaches across multiple datasets. The code is available at https://github.com/xiannanhuang/ADAPT-Z.
Feature Fitted Online Conformal Prediction for Deep Time Series Forecasting Model
May 13, 2025Time series forecasting is critical for many applications, where deep learning-based point prediction models have demonstrated strong performance. However, in practical scenarios, there is also a need to quantify predictive uncertainty through online confidence intervals. Existing confidence interval modeling approaches building upon these deep point prediction models suffer from key limitations: they either require costly retraining, fail to fully leverage the representational strengths of deep models, or lack theoretical guarantees. To address these gaps, we propose a lightweight conformal prediction method that provides valid coverage and shorter interval lengths without retraining. Our approach leverages features extracted from pre-trained point prediction models to fit a residual predictor and construct confidence intervals, further enhanced by an adaptive coverage control mechanism. Theoretically, we prove that our method achieves asymptotic coverage convergence, with error bounds dependent on the feature quality of the underlying point prediction model. Experiments on 12 datasets demonstrate that our method delivers tighter confidence intervals while maintaining desired coverage rates. Code, model and dataset in \href{https://github.com/xiannanhuang/FFDCI}{Github}
CONTINA: Confidence Interval for Traffic Demand Prediction with Coverage Guarantee
Apr 17, 2025Accurate short-term traffic demand prediction is critical for the operation of traffic systems. Besides point estimation, the confidence interval of the prediction is also of great importance. Many models for traffic operations, such as shared bike rebalancing and taxi dispatching, take into account the uncertainty of future demand and require confidence intervals as the input. However, existing methods for confidence interval modeling rely on strict assumptions, such as unchanging traffic patterns and correct model specifications, to guarantee enough coverage. Therefore, the confidence intervals provided could be invalid, especially in a changing traffic environment. To fill this gap, we propose an efficient method, CONTINA (Conformal Traffic Intervals with Adaptation) to provide interval predictions that can adapt to external changes. By collecting the errors of interval during deployment, the method can adjust the interval in the next step by widening it if the errors are too large or shortening it otherwise. Furthermore, we theoretically prove that the coverage of the confidence intervals provided by our method converges to the target coverage level. Experiments across four real-world datasets and prediction models demonstrate that the proposed method can provide valid confidence intervals with shorter lengths. Our method can help traffic management personnel develop a more reasonable and robust operation plan in practice. And we release the code, model and dataset in \href{ https://github.com/xiannanhuang/CONTINA/}{ Github}.
Individual Bus Trip Chain Prediction and Pattern Identification Considering Similarities
Dec 16, 2024Predicting future bus trip chains for an existing user is of great significance for operators of public transit systems. Existing methods always treat this task as a time-series prediction problem, but the 1-dimensional time series structure cannot express the complex relationship between trips. To better capture the inherent patterns in bus travel behavior, this paper proposes a novel approach that synthesizes future bus trip chains based on those from similar days. Key similarity patterns are defined and tested using real-world data, and a similarity function is then developed to capture these patterns. Afterwards, a graph is constructed where each day is represented as a node and edge weight reflects the similarity between days. Besides, the trips on a given day can be regarded as labels for each node, transferring the bus trip chain prediction problem to a semi-supervised classification problem on a graph. To address this, we propose several methods and validate them on a real-world dataset of 10000 bus users, achieving state-of-the-art prediction results. Analyzing the parameters of similarity function reveals some interesting bus usage patterns, allowing us can to cluster bus users into three types: repeat-dominated, evolve-dominate and repeat-evolve balanced. In summary, our work demonstrates the effectiveness of similarity-based prediction for bus trip chains and provides a new perspective for analyzing individual bus travel patterns. The code for our prediction model is publicly available.
Predicting Subway Passenger Flows under Incident Situation with Causality
Dec 09, 2024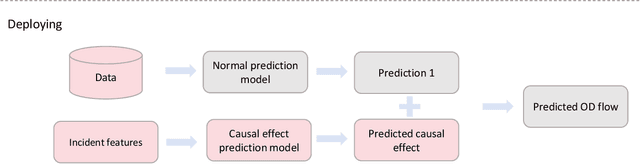
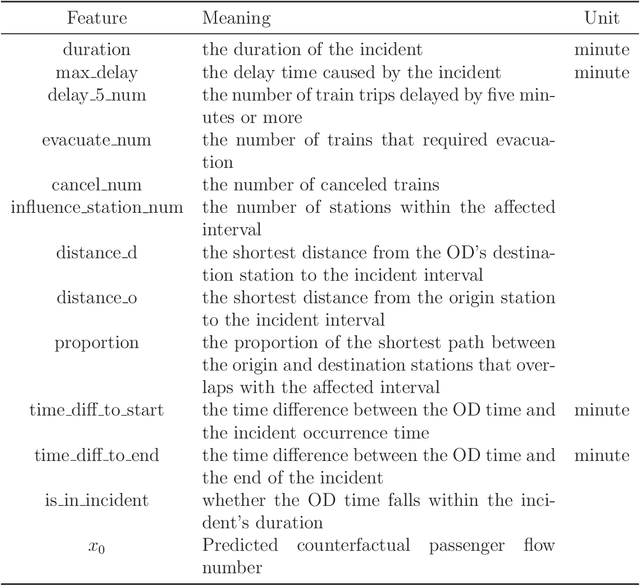
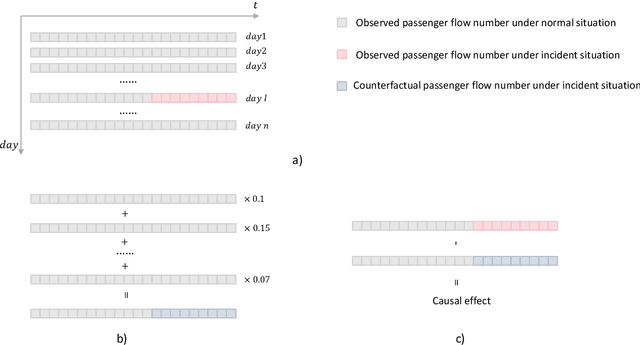
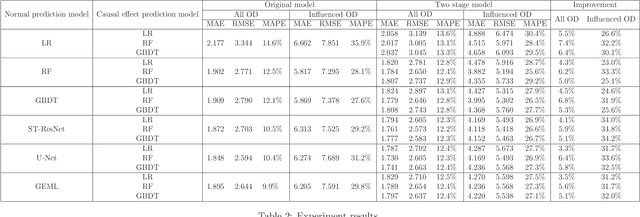
In the context of rail transit operations, real-time passenger flow prediction is essential; however, most models primarily focus on normal conditions, with limited research addressing incident situations. There are several intrinsic challenges associated with prediction during incidents, such as a lack of interpretability and data scarcity. To address these challenges, we propose a two-stage method that separates predictions under normal conditions and the causal effects of incidents. First, a normal prediction model is trained using data from normal situations. Next, the synthetic control method is employed to identify the causal effects of incidents, combined with placebo tests to determine significant levels of these effects. The significant effects are then utilized to train a causal effect prediction model, which can forecast the impact of incidents based on features of the incidents and passenger flows. During the prediction phase, the results from both the normal situation model and the causal effect prediction model are integrated to generate final passenger flow predictions during incidents. Our approach is validated using real-world data, demonstrating improved accuracy. Furthermore, the two-stage methodology enhances interpretability. By analyzing the causal effect prediction model, we can identify key influencing factors related to the effects of incidents and gain insights into their underlying mechanisms. Our work can assist subway system managers in estimating passenger flow affected by incidents and enable them to take proactive measures. Additionally, it can deepen researchers' understanding of the impact of incidents on subway passenger flows.
Leveraging Intra-Period and Inter-Period Features for Enhanced Passenger Flow Prediction of Subway Stations
Oct 16, 2024



Accurate short-term passenger flow prediction of subway stations plays a vital role in enabling subway station personnel to proactively address changes in passenger volume. Despite existing literature in this field, there is a lack of research on effectively integrating features from different periods, particularly intra-period and inter-period features, for subway station passenger flow prediction. In this paper, we propose a novel model called \textbf{M}uti \textbf{P}eriod \textbf{S}patial \textbf{T}emporal \textbf{N}etwork \textbf{MPSTN}) that leverages features from different periods by transforming one-dimensional time series data into two-dimensional matrices based on periods. The folded matrices exhibit structural characteristics similar to images, enabling the utilization of image processing techniques, specifically convolutional neural networks (CNNs), to integrate features from different periods. Therefore, our MPSTN model incorporates a CNN module to extract temporal information from different periods and a graph neural network (GNN) module to integrate spatial information from different stations. We compared our approach with various state-of-the-art methods for spatiotemporal data prediction using a publicly available dataset and achieved minimal prediction errors. The code for our model is publicly available in the following repository: https://github.com/xiannanhuang/MPSTN
Incorporating Long-term Data in Training Short-term Traffic Prediction Model
Oct 16, 2024



Short-term traffic volume prediction is crucial for intelligent transportation system and there are many researches focusing on this field. However, most of these existing researches concentrated on refining model architecture and ignored amount of training data. Therefore, there remains a noticeable gap in thoroughly exploring the effect of augmented dataset, especially extensive historical data in training. In this research, two datasets containing taxi and bike usage spanning over eight years in New York were used to test such effects. Experiments were conducted to assess the precision of models trained with data in the most recent 12, 24, 48, and 96 months. It was found that the training set encompassing 96 months, at times, resulted in diminished accuracy, which might be owing to disparities between historical traffic patterns and present ones. An analysis was subsequently undertaken to discern potential sources of inconsistent patterns, which may include both covariate shift and concept shift. To address these shifts, we proposed an innovative approach that aligns covariate distributions using a weighting scheme to manage covariate shift, coupled with an environment aware learning method to tackle the concept shift. Experiments based on real word datasets demonstrate the effectiveness of our method which can significantly decrease testing errors and ensure an improvement in accuracy when training with large-scale historical data. As far as we know, this work is the first attempt to assess the impact of contiguously expanding training dataset on the accuracy of traffic prediction models. Besides, our training method is able to be incorporated into most existing short-term traffic prediction models and make them more suitable for long term historical training dataset.
Enhancing Traffic Prediction with Textual Data Using Large Language Models
May 10, 2024Traffic prediction is pivotal for rational transportation supply scheduling and allocation. Existing researches into short-term traffic prediction, however, face challenges in adequately addressing exceptional circumstances and integrating non-numerical contextual information like weather into models. While, Large language models offer a promising solution due to their inherent world knowledge. However, directly using them for traffic prediction presents drawbacks such as high cost, lack of determinism, and limited mathematical capability. To mitigate these issues, this study proposes a novel approach. Instead of directly employing large models for prediction, it utilizes them to process textual information and obtain embeddings. These embeddings are then combined with historical traffic data and inputted into traditional spatiotemporal forecasting models. The study investigates two types of special scenarios: regional-level and node-level. For regional-level scenarios, textual information is represented as a node connected to the entire network. For node-level scenarios, embeddings from the large model represent additional nodes connected only to corresponding nodes. This approach shows a significant improvement in prediction accuracy according to our experiment of New York Bike dataset.