 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Federated Fraud Detection in Payment Transactions with NVIDIA FLARE
Mar 13, 2026Fraud-related financial losses continue to rise, while regulatory, privacy, and data-sovereignty constraints increasingly limit the feasibility of centralized fraud detection systems. Federated Learning (FL) has emerged as a promising paradigm for enabling collaborative model training across institutions without sharing raw transaction data. Yet, its practical effectiveness under realistic, non-IID financial data distributions remains insufficiently validated. In this work, we present a multi-institution, industry-oriented proof-of-concept study evaluating federated anomaly detection for payment transactions using the NVIDIA FLARE framework. We simulate a realistic federation of heterogeneous financial institutions, each observing distinct fraud typologies and operating under strict data isolation. Using a deep neural network trained via federated averaging (FedAvg), we demonstrate that federated models achieve a mean F1-score of 0.903 - substantially outperforming locally trained models (0.643) and closely approaching centralized training performance (0.925), while preserving full data sovereignty. We further analyze convergence behavior, showing that strong performance is achieved within 10 federated communication rounds, highlighting the operational viability of FL in latency- and cost-sensitive financial environments. To support deployment in regulated settings, we evaluate model interpretability using Shapley-based feature attribution and confirm that federated models rely on semantically coherent, domain-relevant decision signals. Finally, we incorporate sample-level differential privacy via DP-SGD and demonstrate favorable privacy-utility trade-offs...
CONTINA: Confidence Interval for Traffic Demand Prediction with Coverage Guarantee
Apr 17, 2025Accurate short-term traffic demand prediction is critical for the operation of traffic systems. Besides point estimation, the confidence interval of the prediction is also of great importance. Many models for traffic operations, such as shared bike rebalancing and taxi dispatching, take into account the uncertainty of future demand and require confidence intervals as the input. However, existing methods for confidence interval modeling rely on strict assumptions, such as unchanging traffic patterns and correct model specifications, to guarantee enough coverage. Therefore, the confidence intervals provided could be invalid, especially in a changing traffic environment. To fill this gap, we propose an efficient method, CONTINA (Conformal Traffic Intervals with Adaptation) to provide interval predictions that can adapt to external changes. By collecting the errors of interval during deployment, the method can adjust the interval in the next step by widening it if the errors are too large or shortening it otherwise. Furthermore, we theoretically prove that the coverage of the confidence intervals provided by our method converges to the target coverage level. Experiments across four real-world datasets and prediction models demonstrate that the proposed method can provide valid confidence intervals with shorter lengths. Our method can help traffic management personnel develop a more reasonable and robust operation plan in practice. And we release the code, model and dataset in \href{ https://github.com/xiannanhuang/CONTINA/}{ Github}.
C-FedRAG: A Confidential Federated Retrieval-Augmented Generation System
Dec 17, 2024



Organizations seeking to utilize Large Language Models (LLMs) for knowledge querying and analysis often encounter challenges in maintaining an LLM fine-tuned on targeted, up-to-date information that keeps answers relevant and grounded. Retrieval Augmented Generation (RAG) has quickly become a feasible solution for organizations looking to overcome the challenges of maintaining proprietary models and to help reduce LLM hallucinations in their query responses. However, RAG comes with its own issues regarding scaling data pipelines across tiered-access and disparate data sources. In many scenarios, it is necessary to query beyond a single data silo to provide richer and more relevant context for an LLM. Analyzing data sources within and across organizational trust boundaries is often limited by complex data-sharing policies that prohibit centralized data storage, therefore, inhibit the fast and effective setup and scaling of RAG solutions. In this paper, we introduce Confidential Computing (CC) techniques as a solution for secure Federated Retrieval Augmented Generation (FedRAG). Our proposed Confidential FedRAG system (C-FedRAG) enables secure connection and scaling of a RAG workflows across a decentralized network of data providers by ensuring context confidentiality. We also demonstrate how to implement a C-FedRAG system using the NVIDIA FLARE SDK and assess its performance using the MedRAG toolkit and MIRAGE benchmarking dataset.
Incorporating Long-term Data in Training Short-term Traffic Prediction Model
Oct 16, 2024



Short-term traffic volume prediction is crucial for intelligent transportation system and there are many researches focusing on this field. However, most of these existing researches concentrated on refining model architecture and ignored amount of training data. Therefore, there remains a noticeable gap in thoroughly exploring the effect of augmented dataset, especially extensive historical data in training. In this research, two datasets containing taxi and bike usage spanning over eight years in New York were used to test such effects. Experiments were conducted to assess the precision of models trained with data in the most recent 12, 24, 48, and 96 months. It was found that the training set encompassing 96 months, at times, resulted in diminished accuracy, which might be owing to disparities between historical traffic patterns and present ones. An analysis was subsequently undertaken to discern potential sources of inconsistent patterns, which may include both covariate shift and concept shift. To address these shifts, we proposed an innovative approach that aligns covariate distributions using a weighting scheme to manage covariate shift, coupled with an environment aware learning method to tackle the concept shift. Experiments based on real word datasets demonstrate the effectiveness of our method which can significantly decrease testing errors and ensure an improvement in accuracy when training with large-scale historical data. As far as we know, this work is the first attempt to assess the impact of contiguously expanding training dataset on the accuracy of traffic prediction models. Besides, our training method is able to be incorporated into most existing short-term traffic prediction models and make them more suitable for long term historical training dataset.
Phase retrieval via media diversity
Oct 16, 2024This work studies phase retrieval for wave fields, aiming to recover the phase of an incoming wave from multi-plane intensity measurements behind different types of linear and nonlinear media. We show that unique phase retrieval can be achieved by utilizing intensity data produced by multiple media. This uniqueness does not require prescribed boundary conditions for the phase in the incidence plane, in contrast to existing phase retrieval methods based on the transport of intensity equation. Moreover, the uniqueness proofs lead to explicit phase reconstruction algorithms. Numerical simulations are presented to validate the theory.
DART: Depth-Enhanced Accurate and Real-Time Background Matting
Feb 24, 2024



Matting with a static background, often referred to as ``Background Matting" (BGM), has garnered significant attention within the computer vision community due to its pivotal role in various practical applications like webcasting and photo editing. Nevertheless, achieving highly accurate background matting remains a formidable challenge, primarily owing to the limitations inherent in conventional RGB images. These limitations manifest in the form of susceptibility to varying lighting conditions and unforeseen shadows. In this paper, we leverage the rich depth information provided by the RGB-Depth (RGB-D) cameras to enhance background matting performance in real-time, dubbed DART. Firstly, we adapt the original RGB-based BGM algorithm to incorporate depth information. The resulting model's output undergoes refinement through Bayesian inference, incorporating a background depth prior. The posterior prediction is then translated into a "trimap," which is subsequently fed into a state-of-the-art matting algorithm to generate more precise alpha mattes. To ensure real-time matting capabilities, a critical requirement for many real-world applications, we distill the backbone of our model from a larger and more versatile BGM network. Our experiments demonstrate the superior performance of the proposed method. Moreover, thanks to the distillation operation, our method achieves a remarkable processing speed of 33 frames per second (fps) on a mid-range edge-computing device. This high efficiency underscores DART's immense potential for deployment in mobile applications}
Empowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024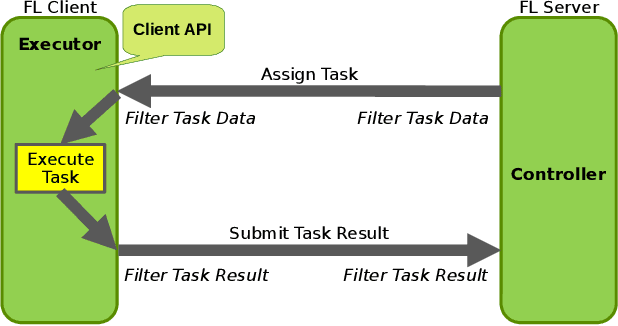

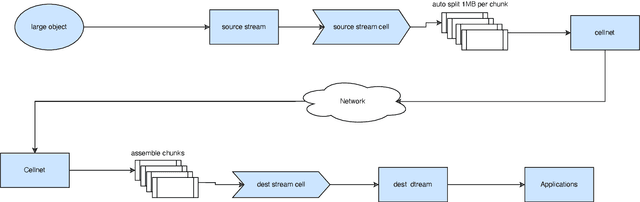
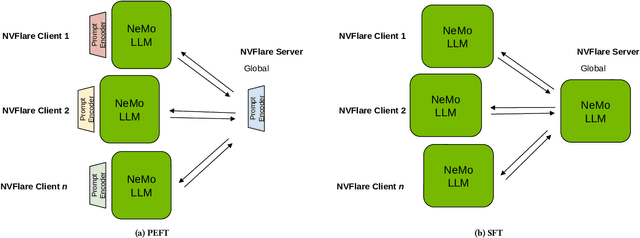
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022



Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.
Federated Learning for Breast Density Classification: A Real-World Implementation
Sep 17, 2020

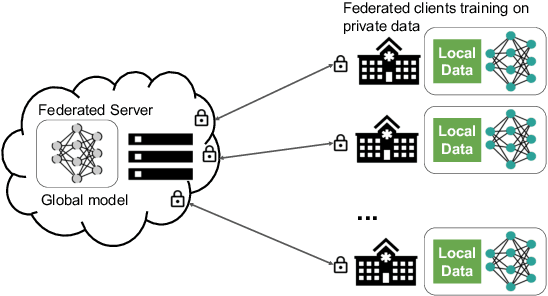
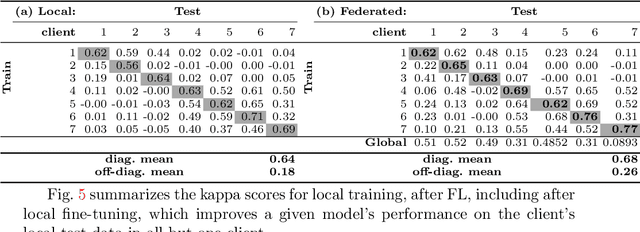
Building robust deep learning-based models requires large quantities of diverse training data. In this study, we investigate the use of federated learning (FL) to build medical imaging classification models in a real-world collaborative setting. Seven clinical institutions from across the world joined this FL effort to train a model for breast density classification based on Breast Imaging, Reporting & Data System (BI-RADS). We show that despite substantial differences among the datasets from all sites (mammography system, class distribution, and data set size) and without centralizing data, we can successfully train AI models in federation. The results show that models trained using FL perform 6.3% on average better than their counterparts trained on an institute's local data alone. Furthermore, we show a 45.8% relative improvement in the models' generalizability when evaluated on the other participating sites' testing data.
Privacy-preserving Federated Brain Tumour Segmentation
Oct 02, 2019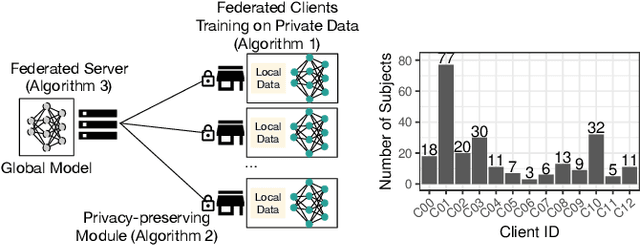

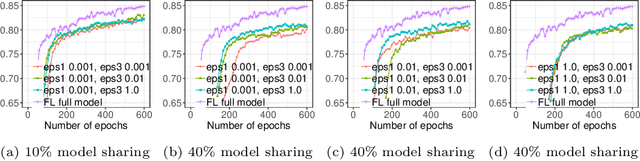
Due to medical data privacy regulations, it is often infeasible to collect and share patient data in a centralised data lake. This poses challenges for training machine learning algorithms, such as deep convolutional networks, which often require large numbers of diverse training examples. Federated learning sidesteps this difficulty by bringing code to the patient data owners and only sharing intermediate model training updates among them. Although a high-accuracy model could be achieved by appropriately aggregating these model updates, the model shared could indirectly leak the local training examples. In this paper, we investigate the feasibility of applying differential-privacy techniques to protect the patient data in a federated learning setup. We implement and evaluate practical federated learning systems for brain tumour segmentation on the BraTS dataset. The experimental results show that there is a trade-off between model performance and privacy protection costs.