 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-FedRAG: A Confidential Federated Retrieval-Augmented Generation System
Dec 17, 2024



Organizations seeking to utilize Large Language Models (LLMs) for knowledge querying and analysis often encounter challenges in maintaining an LLM fine-tuned on targeted, up-to-date information that keeps answers relevant and grounded. Retrieval Augmented Generation (RAG) has quickly become a feasible solution for organizations looking to overcome the challenges of maintaining proprietary models and to help reduce LLM hallucinations in their query responses. However, RAG comes with its own issues regarding scaling data pipelines across tiered-access and disparate data sources. In many scenarios, it is necessary to query beyond a single data silo to provide richer and more relevant context for an LLM. Analyzing data sources within and across organizational trust boundaries is often limited by complex data-sharing policies that prohibit centralized data storage, therefore, inhibit the fast and effective setup and scaling of RAG solutions. In this paper, we introduce Confidential Computing (CC) techniques as a solution for secure Federated Retrieval Augmented Generation (FedRAG). Our proposed Confidential FedRAG system (C-FedRAG) enables secure connection and scaling of a RAG workflows across a decentralized network of data providers by ensuring context confidentiality. We also demonstrate how to implement a C-FedRAG system using the NVIDIA FLARE SDK and assess its performance using the MedRAG toolkit and MIRAGE benchmarking dataset.
Self-supervised similarity search for large scientific datasets
Oct 25, 2021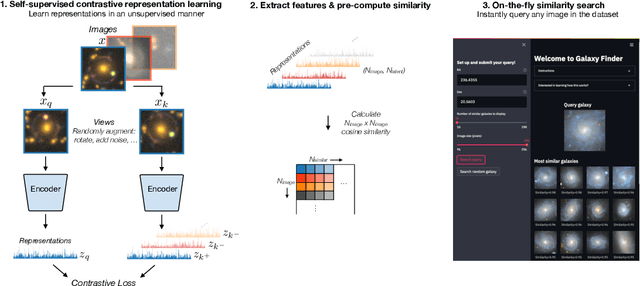

We present the use of self-supervised learning to explore and exploit large unlabeled datasets. Focusing on 42 million galaxy images from the latest data release of the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys, we first train a self-supervised model to distil low-dimensional representations that are robust to symmetries, uncertainties, and noise in each image. We then use the representations to construct and publicly release an interactive semantic similarity search tool. We demonstrate how our tool can be used to rapidly discover rare objects given only a single example, increase the speed of crowd-sourcing campaigns, and construct and improve training sets for supervised applications. While we focus on images from sky surveys, the technique is straightforward to apply to any scientific dataset of any dimensionality. The similarity search web app can be found at https://github.com/georgestein/galaxy_search
Mining for strong gravitational lenses with self-supervised learning
Sep 30, 2021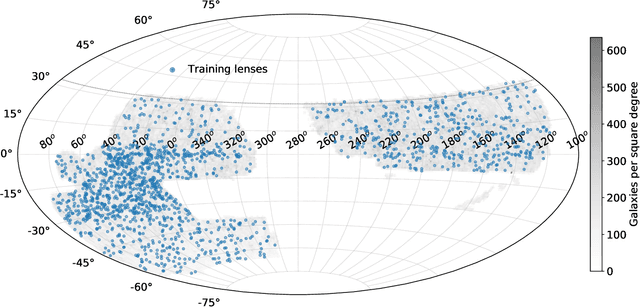
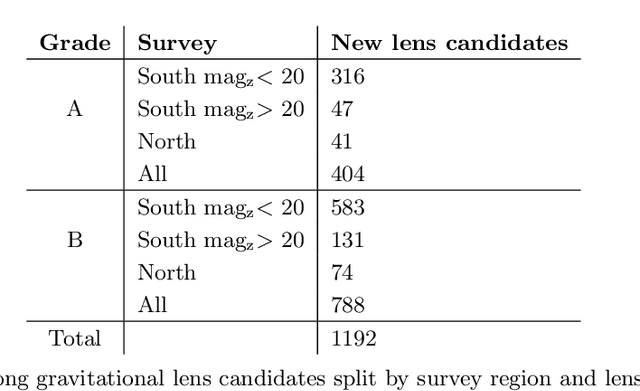
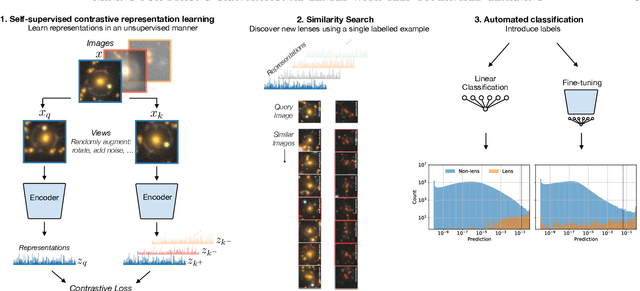

We employ self-supervised representation learning to distill information from 76 million galaxy images from the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys' Data Release 9. Targeting the identification of new strong gravitational lens candidates, we first create a rapid similarity search tool to discover new strong lenses given only a single labelled example. We then show how training a simple linear classifier on the self-supervised representations, requiring only a few minutes on a CPU, can automatically classify strong lenses with great efficiency. We present 1192 new strong lens candidates that we identified through a brief visual identification campaign, and release an interactive web-based similarity search tool and the top network predictions to facilitate crowd-sourcing rapid discovery of additional strong gravitational lenses and other rare objects: github.com/georgestein/ssl-legacysurvey