 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-FedRAG: A Confidential Federated Retrieval-Augmented Generation System
Dec 17, 2024



Organizations seeking to utilize Large Language Models (LLMs) for knowledge querying and analysis often encounter challenges in maintaining an LLM fine-tuned on targeted, up-to-date information that keeps answers relevant and grounded. Retrieval Augmented Generation (RAG) has quickly become a feasible solution for organizations looking to overcome the challenges of maintaining proprietary models and to help reduce LLM hallucinations in their query responses. However, RAG comes with its own issues regarding scaling data pipelines across tiered-access and disparate data sources. In many scenarios, it is necessary to query beyond a single data silo to provide richer and more relevant context for an LLM. Analyzing data sources within and across organizational trust boundaries is often limited by complex data-sharing policies that prohibit centralized data storage, therefore, inhibit the fast and effective setup and scaling of RAG solutions. In this paper, we introduce Confidential Computing (CC) techniques as a solution for secure Federated Retrieval Augmented Generation (FedRAG). Our proposed Confidential FedRAG system (C-FedRAG) enables secure connection and scaling of a RAG workflows across a decentralized network of data providers by ensuring context confidentiality. We also demonstrate how to implement a C-FedRAG system using the NVIDIA FLARE SDK and assess its performance using the MedRAG toolkit and MIRAGE benchmarking dataset.
Empowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024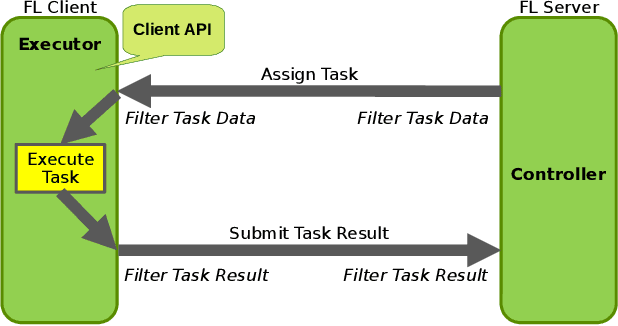

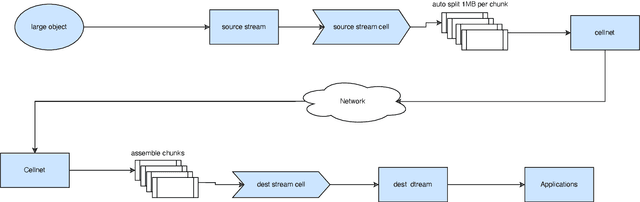
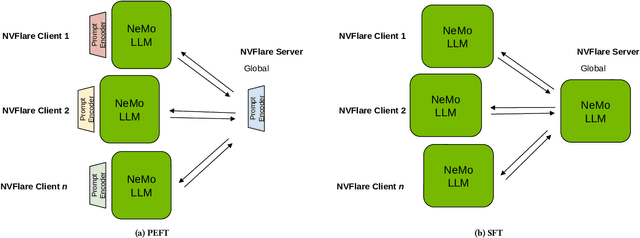
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.