 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Image Registration Approach for Measuring Local Response Patterns in Metastatic Ovarian Cancer
Jul 24, 2024



High-grade serous ovarian carcinoma (HGSOC) is characterised by significant spatial and temporal heterogeneity, typically manifesting at an advanced metastatic stage. A major challenge in treating advanced HGSOC is effectively monitoring localised change in tumour burden across multiple sites during neoadjuvant chemotherapy (NACT) and predicting long-term pathological response and overall patient survival. In this work, we propose a self-supervised deformable image registration algorithm that utilises a general-purpose image encoder for image feature extraction to co-register contrast-enhanced computerised tomography scan images acquired before and after neoadjuvant chemotherapy. This approach addresses challenges posed by highly complex tumour deformations and longitudinal lesion matching during treatment. Localised tumour changes are calculated using the Jacobian determinant maps of the registration deformation at multiple disease sites and their macroscopic areas, including hypo-dense (i.e., cystic/necrotic), hyper-dense (i.e., calcified), and intermediate density (i.e., soft tissue) portions. A series of experiments is conducted to understand the role of a general-purpose image encoder and its application in quantifying change in tumour burden during neoadjuvant chemotherapy in HGSOC. This work is the first to demonstrate the feasibility of a self-supervised image registration approach in quantifying NACT-induced localised tumour changes across the whole disease burden of patients with complex multi-site HGSOC, which could be used as a potential marker for ovarian cancer patient's long-term pathological response and survival.
Generative AI for Medical Imaging: extending the MONAI Framework
Jul 27, 2023Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.
Current State of Community-Driven Radiological AI Deployment in Medical Imaging
Dec 29, 2022



Artificial Intelligence (AI) has become commonplace to solve routine everyday tasks. Because of the exponential growth in medical imaging data volume and complexity, the workload on radiologists is steadily increasing. We project that the gap between the number of imaging exams and the number of expert radiologist readers required to cover this increase will continue to expand, consequently introducing a demand for AI-based tools that improve the efficiency with which radiologists can comfortably interpret these exams. AI has been shown to improve efficiency in medical-image generation, processing, and interpretation, and a variety of such AI models have been developed across research labs worldwide. However, very few of these, if any, find their way into routine clinical use, a discrepancy that reflects the divide between AI research and successful AI translation. To address the barrier to clinical deployment, we have formed MONAI Consortium, an open-source community which is building standards for AI deployment in healthcare institutions, and developing tools and infrastructure to facilitate their implementation. This report represents several years of weekly discussions and hands-on problem solving experience by groups of industry experts and clinicians in the MONAI Consortium. We identify barriers between AI-model development in research labs and subsequent clinical deployment and propose solutions. Our report provides guidance on processes which take an imaging AI model from development to clinical implementation in a healthcare institution. We discuss various AI integration points in a clinical Radiology workflow. We also present a taxonomy of Radiology AI use-cases. Through this report, we intend to educate the stakeholders in healthcare and AI (AI researchers, radiologists, imaging informaticists, and regulators) about cross-disciplinary challenges and possible solutions.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Estimation of Cardiac Valve Annuli Motion with Deep Learning
Oct 23, 2020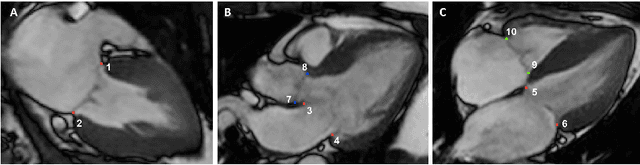
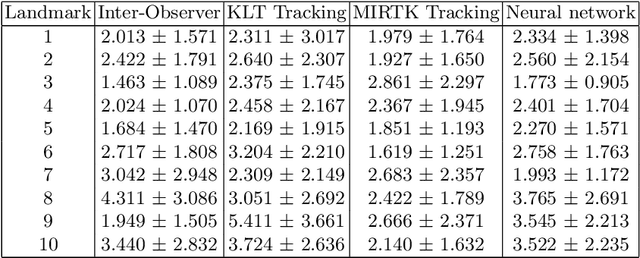
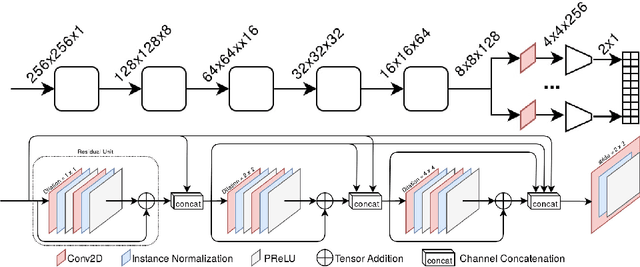
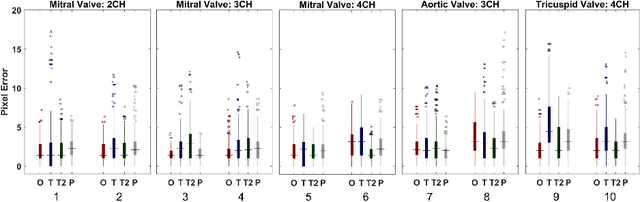
Valve annuli motion and morphology, measured from non-invasive imaging, can be used to gain a better understanding of healthy and pathological heart function. Measurements such as long-axis strain as well as peak strain rates provide markers of systolic function. Likewise, early and late-diastolic filling velocities are used as indicators of diastolic function. Quantifying global strains, however, requires a fast and precise method of tracking long-axis motion throughout the cardiac cycle. Valve landmarks such as the insertion of leaflets into the myocardial wall provide features that can be tracked to measure global long-axis motion. Feature tracking methods require initialisation, which can be time-consuming in studies with large cohorts. Therefore, this study developed and trained a neural network to identify ten features from unlabeled long-axis MR images: six mitral valve points from three long-axis views, two aortic valve points and two tricuspid valve points. This study used manual annotations of valve landmarks in standard 2-, 3- and 4-chamber long-axis images collected in clinical scans to train the network. The accuracy in the identification of these ten features, in pixel distance, was compared with the accuracy of two commonly used feature tracking methods as well as the inter-observer variability of manual annotations. Clinical measures, such as valve landmark strain and motion between end-diastole and end-systole, are also presented to illustrate the utility and robustness of the method.
Quality-aware semi-supervised learning for CMR segmentation
Sep 01, 2020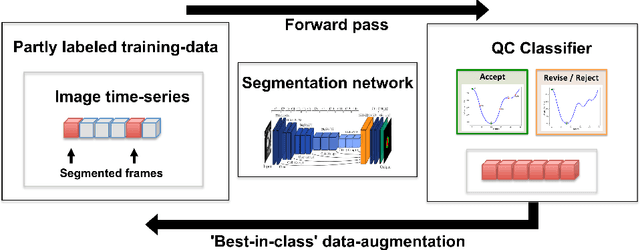
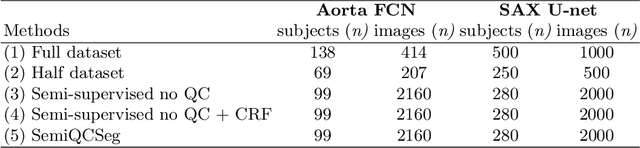
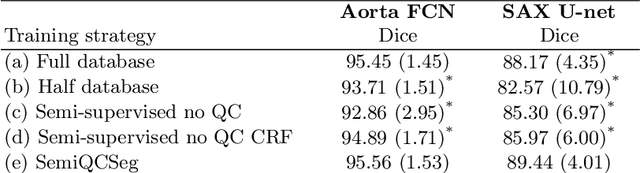
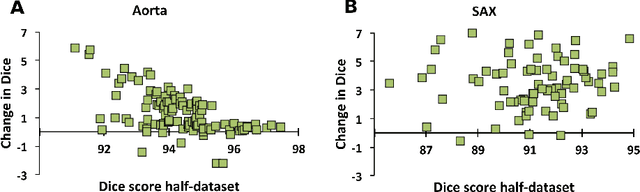
One of the challenges in developing deep learning algorithms for medical image segmentation is the scarcity of annotated training data. To overcome this limitation, data augmentation and semi-supervised learning (SSL) methods have been developed. However, these methods have limited effectiveness as they either exploit the existing data set only (data augmentation) or risk negative impact by adding poor training examples (SSL). Segmentations are rarely the final product of medical image analysis - they are typically used in downstream tasks to infer higher-order patterns to evaluate diseases. Clinicians take into account a wealth of prior knowledge on biophysics and physiology when evaluating image analysis results. We have used these clinical assessments in previous works to create robust quality-control (QC) classifiers for automated cardiac magnetic resonance (CMR) analysis. In this paper, we propose a novel scheme that uses QC of the downstream task to identify high quality outputs of CMR segmentation networks, that are subsequently utilised for further network training. In essence, this provides quality-aware augmentation of training data in a variant of SSL for segmentation networks (semiQCSeg). We evaluate our approach in two CMR segmentation tasks (aortic and short axis cardiac volume segmentation) using UK Biobank data and two commonly used network architectures (U-net and a Fully Convolutional Network) and compare against supervised and SSL strategies. We show that semiQCSeg improves training of the segmentation networks. It decreases the need for labelled data, while outperforming the other methods in terms of Dice and clinical metrics. SemiQCSeg can be an efficient approach for training segmentation networks for medical image data when labelled datasets are scarce.