 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank-Modulated Functa: Exploring the Latent Space of Implicit Neural Representations for Interpretable Ultrasound Video Analysis
Mar 26, 2026Implicit neural representations (INRs) have emerged as a powerful framework for continuous image representation learning. In Functa-based approaches, each image is encoded as a latent modulation vector that conditions a shared INR, enabling strong reconstruction performance. However, the structure and interpretability of the corresponding latent spaces remain largely unexplored. In this work, we investigate the latent space of Functa-based models for ultrasound videos and propose Low-Rank-Modulated Functa (LRM-Functa), a novel architecture that enforces a low-rank adaptation of modulation vectors in the time-resolved latent space. When applied to cardiac ultrasound, the resulting latent space exhibits clearly structured periodic trajectories, facilitating visualization and interpretability of temporal patterns. The latent space can be traversed to sample novel frames, revealing smooth transitions along the cardiac cycle, and enabling direct readout of end-diastolic (ED) and end-systolic (ES) frames without additional model training. We show that LRM-Functa outperforms prior methods in unsupervised ED and ES frame detection, while compressing each video frame to as low as rank k=2 without sacrificing competitive downstream performance on ejection fraction prediction. Evaluations on out-of-distribution frame selection in a cardiac point-of-care dataset, as well as on lung ultrasound for B-line classification, demonstrate the generalizability of our approach. Overall, LRM-Functa provides a compact, interpretable, and generalizable framework for ultrasound video analysis. The code is available at https://github.com/JuliaWolleb/LRM_Functa.
VidFuncta: Towards Generalizable Neural Representations for Ultrasound Videos
Jul 29, 2025Ultrasound is widely used in clinical care, yet standard deep learning methods often struggle with full video analysis due to non-standardized acquisition and operator bias. We offer a new perspective on ultrasound video analysis through implicit neural representations (INRs). We build on Functa, an INR framework in which each image is represented by a modulation vector that conditions a shared neural network. However, its extension to the temporal domain of medical videos remains unexplored. To address this gap, we propose VidFuncta, a novel framework that leverages Functa to encode variable-length ultrasound videos into compact, time-resolved representations. VidFuncta disentangles each video into a static video-specific vector and a sequence of time-dependent modulation vectors, capturing both temporal dynamics and dataset-level redundancies. Our method outperforms 2D and 3D baselines on video reconstruction and enables downstream tasks to directly operate on the learned 1D modulation vectors. We validate VidFuncta on three public ultrasound video datasets -- cardiac, lung, and breast -- and evaluate its downstream performance on ejection fraction prediction, B-line detection, and breast lesion classification. These results highlight the potential of VidFuncta as a generalizable and efficient representation framework for ultrasound videos. Our code is publicly available under https://github.com/JuliaWolleb/VidFuncta_public.
cWDM: Conditional Wavelet Diffusion Models for Cross-Modality 3D Medical Image Synthesis
Nov 26, 2024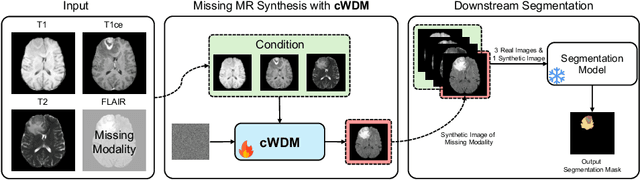

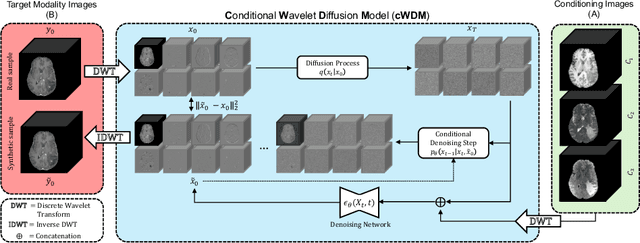

This paper contributes to the "BraTS 2024 Brain MR Image Synthesis Challenge" and presents a conditional Wavelet Diffusion Model (cWDM) for directly solving a paired image-to-image translation task on high-resolution volumes. While deep learning-based brain tumor segmentation models have demonstrated clear clinical utility, they typically require MR scans from various modalities (T1, T1ce, T2, FLAIR) as input. However, due to time constraints or imaging artifacts, some of these modalities may be missing, hindering the application of well-performing segmentation algorithms in clinical routine. To address this issue, we propose a method that synthesizes one missing modality image conditioned on three available images, enabling the application of downstream segmentation models. We treat this paired image-to-image translation task as a conditional generation problem and solve it by combining a Wavelet Diffusion Model for high-resolution 3D image synthesis with a simple conditioning strategy. This approach allows us to directly apply our model to full-resolution volumes, avoiding artifacts caused by slice- or patch-wise data processing. While this work focuses on a specific application, the presented method can be applied to all kinds of paired image-to-image translation problems, such as CT $\leftrightarrow$ MR and MR $\leftrightarrow$ PET translation, or mask-conditioned anatomically guided image generation.
Denoising Diffusion Models for Anomaly Localization in Medical Images
Oct 31, 2024



This chapter explores anomaly localization in medical images using denoising diffusion models. After providing a brief methodological background of these models, including their application to image reconstruction and their conditioning using guidance mechanisms, we provide an overview of available datasets and evaluation metrics suitable for their application to anomaly localization in medical images. In this context, we discuss supervision schemes ranging from fully supervised segmentation to semi-supervised, weakly supervised, self-supervised, and unsupervised methods, and provide insights into the effectiveness and limitations of these approaches. Furthermore, we highlight open challenges in anomaly localization, including detection bias, domain shift, computational cost, and model interpretability. Our goal is to provide an overview of the current state of the art in the field, outline research gaps, and highlight the potential of diffusion models for robust anomaly localization in medical images.
Modeling the Neonatal Brain Development Using Implicit Neural Representations
Aug 16, 2024The human brain undergoes rapid development during the third trimester of pregnancy. In this work, we model the neonatal development of the infant brain in this age range. As a basis, we use MR images of preterm- and term-birth neonates from the developing human connectome project (dHCP). We propose a neural network, specifically an implicit neural representation (INR), to predict 2D- and 3D images of varying time points. In order to model a subject-specific development process, it is necessary to disentangle the age from the subjects' identity in the latent space of the INR. We propose two methods, Subject Specific Latent Vectors (SSL) and Stochastic Global Latent Augmentation (SGLA), enabling this disentanglement. We perform an analysis of the results and compare our proposed model to an age-conditioned denoising diffusion model as a baseline. We also show that our method can be applied in a memory-efficient way, which is especially important for 3D data.
Denoising Diffusion Models for 3D Healthy Brain Tissue Inpainting
Mar 21, 2024



Monitoring diseases that affect the brain's structural integrity requires automated analysis of magnetic resonance (MR) images, e.g., for the evaluation of volumetric changes. However, many of the evaluation tools are optimized for analyzing healthy tissue. To enable the evaluation of scans containing pathological tissue, it is therefore required to restore healthy tissue in the pathological areas. In this work, we explore and extend denoising diffusion models for consistent inpainting of healthy 3D brain tissue. We modify state-of-the-art 2D, pseudo-3D, and 3D methods working in the image space, as well as 3D latent and 3D wavelet diffusion models, and train them to synthesize healthy brain tissue. Our evaluation shows that the pseudo-3D model performs best regarding the structural-similarity index, peak signal-to-noise ratio, and mean squared error. To emphasize the clinical relevance, we fine-tune this model on data containing synthetic MS lesions and evaluate it on a downstream brain tissue segmentation task, whereby it outperforms the established FMRIB Software Library (FSL) lesion-filling method.
Binary Noise for Binary Tasks: Masked Bernoulli Diffusion for Unsupervised Anomaly Detection
Mar 18, 2024

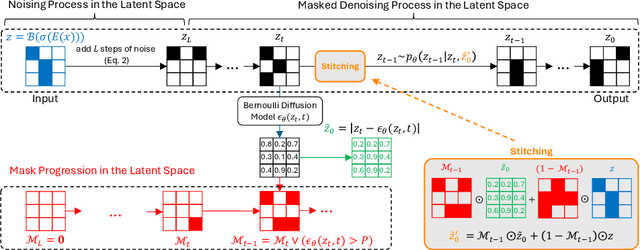

The high performance of denoising diffusion models for image generation has paved the way for their application in unsupervised medical anomaly detection. As diffusion-based methods require a lot of GPU memory and have long sampling times, we present a novel and fast unsupervised anomaly detection approach based on latent Bernoulli diffusion models. We first apply an autoencoder to compress the input images into a binary latent representation. Next, a diffusion model that follows a Bernoulli noise schedule is employed to this latent space and trained to restore binary latent representations from perturbed ones. The binary nature of this diffusion model allows us to identify entries in the latent space that have a high probability of flipping their binary code during the denoising process, which indicates out-of-distribution data. We propose a masking algorithm based on these probabilities, which improves the anomaly detection scores. We achieve state-of-the-art performance compared to other diffusion-based unsupervised anomaly detection algorithms while significantly reducing sampling time and memory consumption. The code is available at https://github.com/JuliaWolleb/Anomaly_berdiff.
WDM: 3D Wavelet Diffusion Models for High-Resolution Medical Image Synthesis
Feb 29, 2024Due to the three-dimensional nature of CT- or MR-scans, generative modeling of medical images is a particularly challenging task. Existing approaches mostly apply patch-wise, slice-wise, or cascaded generation techniques to fit the high-dimensional data into the limited GPU memory. However, these approaches may introduce artifacts and potentially restrict the model's applicability for certain downstream tasks. This work presents WDM, a wavelet-based medical image synthesis framework that applies a diffusion model on wavelet decomposed images. The presented approach is a simple yet effective way of scaling diffusion models to high resolutions and can be trained on a single 40 GB GPU. Experimental results on BraTS and LIDC-IDRI unconditional image generation at a resolution of $128 \times 128 \times 128$ show state-of-the-art image fidelity (FID) and sample diversity (MS-SSIM) scores compared to GANs, Diffusion Models, and Latent Diffusion Models. Our proposed method is the only one capable of generating high-quality images at a resolution of $256 \times 256 \times 256$.
Denoising Diffusion Models for Inpainting of Healthy Brain Tissue
Feb 27, 2024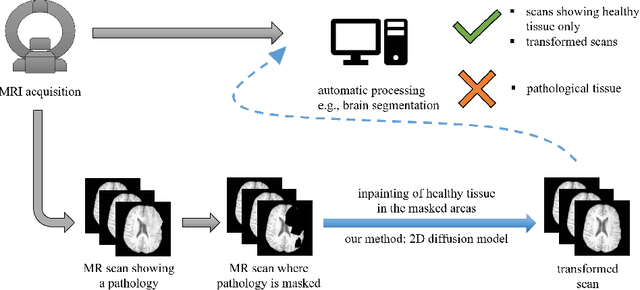
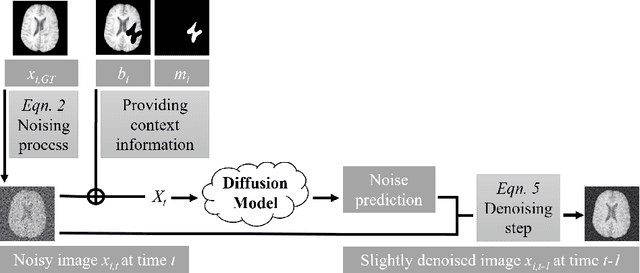
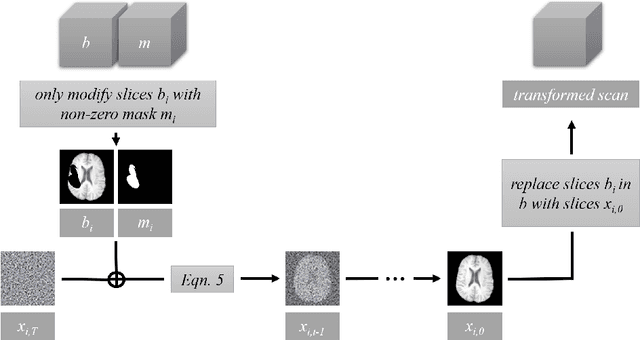
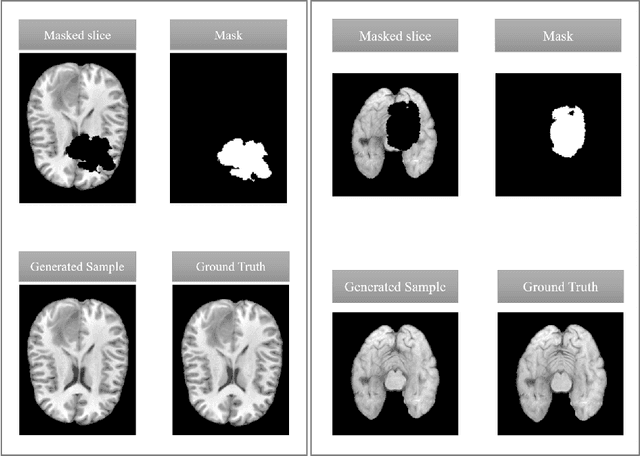
This paper is a contribution to the "BraTS 2023 Local Synthesis of Healthy Brain Tissue via Inpainting Challenge". The task of this challenge is to transform tumor tissue into healthy tissue in brain magnetic resonance (MR) images. This idea originates from the problem that MR images can be evaluated using automatic processing tools, however, many of these tools are optimized for the analysis of healthy tissue. By solving the given inpainting task, we enable the automatic analysis of images featuring lesions, and further downstream tasks. Our approach builds on denoising diffusion probabilistic models. We use a 2D model that is trained using slices in which healthy tissue was cropped out and is learned to be inpainted again. This allows us to use the ground truth healthy tissue during training. In the sampling stage, we replace the slices containing diseased tissue in the original 3D volume with the slices containing the healthy tissue inpainting. With our approach, we achieve comparable results to the competing methods. On the validation set our model achieves a mean SSIM of 0.7804, a PSNR of 20.3525 and a MSE of 0.0113. In future we plan to extend our 2D model to a 3D model, allowing to inpaint the region of interest as a whole without losing context information of neighboring slices.
Generative AI for Medical Imaging: extending the MONAI Framework
Jul 27, 2023Recent advances in generative AI have brought incredible breakthroughs in several areas, including medical imaging. These generative models have tremendous potential not only to help safely share medical data via synthetic datasets but also to perform an array of diverse applications, such as anomaly detection, image-to-image translation, denoising, and MRI reconstruction. However, due to the complexity of these models, their implementation and reproducibility can be difficult. This complexity can hinder progress, act as a use barrier, and dissuade the comparison of new methods with existing works. In this study, we present MONAI Generative Models, a freely available open-source platform that allows researchers and developers to easily train, evaluate, and deploy generative models and related applications. Our platform reproduces state-of-art studies in a standardised way involving different architectures (such as diffusion models, autoregressive transformers, and GANs), and provides pre-trained models for the community. We have implemented these models in a generalisable fashion, illustrating that their results can be extended to 2D or 3D scenarios, including medical images with different modalities (like CT, MRI, and X-Ray data) and from different anatomical areas. Finally, we adopt a modular and extensible approach, ensuring long-term maintainability and the extension of current applications for future features.