 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Representation Learning of Longitudinal Medical Imaging Trajectories for Treatment Response Prediction
Jul 06, 2026In patients with breast cancer, pathological complete response (pCR) has been established as a clinically meaningful surrogate marker for long-term outcomes. While commonly treated with neoadjuvant chemotherapy (NACT), effective treatment decision-making remains challenging, as therapeutic response can vary substantially across patients, calling for predictive models capable of accurately estimating individualized treatment response. To address this, we propose an imaging-based 3D spatio-temporal framework for treatment response prediction that integrates a state-of-the-art graph neural network with relational modeling of temporal interactions across timepoints alongside three novel complementary self-supervised treatment trajectory representation learning objectives. Experiments across a cohort of 585 patients from the public ISPY-2 dataset demonstrate that our method substantially outperforms both vision and self-supervised learning baselines across several classification metrics. Alongside establishing a breast cancer pCR prediction benchmark, we include a principled ablation of our method and further introduce and empirically assess the impact of the available number of DCE-MRI timepoints per patient trajectory and the inclusion of inter-scan time-differences. Overall, our study substantiates the utility of clinically meaningful longitudinal medical imagaging modeling for predicting NACT-induced pCR. We will publicly share our code repository and a user-friendly PyPI library for dataset curation upon publication, effectively promoting reproducible open-source research.
Entropy Minimization without Model Collapse: Mitigating Prediction Bias in Medical Imaging
Jun 01, 2026Entropy minimization (EM) is the dominant objective for test-time adaptation, yet its failure mode, model collapse, remains poorly understood. In this work, we show that distribution shifts can cause feature clusters corresponding to distinct classes in the model's representation space to merge, while the decision boundary remains fixed. This induces a systematic skew in the predicted class distribution, referred to as prediction bias. Prediction bias refers to a shift in the predicted class distribution, with some classes overrepresented and others suppressed. We show that entropy minimization amplifies this prediction bias by tightening the existing clusters, reinforcing the incorrect groupings until all predictions collapse to a trivial solution. Next, to demonstrate the significance of prediction bias and mitigate it, we further propose Distribution Shift Bias Reduction (DSBR), a bias-correcting objective that specifically targets this failure mode by equalizing the contribution of each predicted class to the unsupervised entropy minimization loss. To study this failure mode, we design suitable adaptation settings using four medical-imaging datasets and additionally evaluate on ImageNet-C. We find that DSBR consistently stabilizes test-time adaptation, prevents model collapse, and matches or outperforms state-of-the-art methods. Moreover, DSBR operates solely at test-time.
Dynamic Decision Learning: Test-Time Evolution for Abnormality Grounding in Rare Diseases
Apr 27, 2026Clinical abnormality grounding for rare diseases is often hindered by data scarcity, making supervised fine-tuning impractical and single-pass inference highly unstable. We propose Dynamic Decision Learning (DDL), a framework that enables frozen large vision-language models (LVLMs) to refine their decisions across both language and visual spaces by optimizing instructions and consolidating predictions under visual perturbations. This process improves localization quality and produces a consensus-based reliability score that quantifies model confidence. Results on brain imaging benchmarks, including a rare-disease dataset with 281 pathology types across models ranging from 3B to 72B parameters, show that DDL improves mAP@75 by up to 105% on rare-disease cases and outperforms adaptation baselines and supervised fine-tuning. Furthermore, DDL demonstrates stronger calibration between reliability scores and localization accuracy under severe distribution shifts and increasing task difficulty. Code is available at: https://lijunrio.github.io/DDL/
The Mean is the Mirage: Entropy-Adaptive Model Merging under Heterogeneous Domain Shifts in Medical Imaging
Feb 24, 2026Model merging under unseen test-time distribution shifts often renders naive strategies, such as mean averaging unreliable. This challenge is especially acute in medical imaging, where models are fine-tuned locally at clinics on private data, producing domain-specific models that differ by scanner, protocol, and population. When deployed at an unseen clinical site, test cases arrive in unlabeled, non-i.i.d. batches, and the model must adapt immediately without labels. In this work, we introduce an entropy-adaptive, fully online model-merging method that yields a batch-specific merged model via only forward passes, effectively leveraging target information. We further demonstrate why mean merging is prone to failure and misaligned under heterogeneous domain shifts. Next, we mitigate encoder classifier mismatch by decoupling the encoder and classification head, merging with separate merging coefficients. We extensively evaluate our method with state-of-the-art baselines using two backbones across nine medical and natural-domain generalization image classification datasets, showing consistent gains across standard evaluation and challenging scenarios. These performance gains are achieved while retaining single-model inference at test-time, thereby demonstrating the effectiveness of our method.
A Master Class on Reproducibility: A Student Hackathon on Advanced MRI Reconstruction Methods
Jan 26, 2026We report the design, protocol, and outcomes of a student reproducibility hackathon focused on replicating the results of three influential MRI reconstruction papers: (a) MoDL, an unrolled model-based network with learned denoising; (b) HUMUS-Net, a hybrid unrolled multiscale CNN+Transformer architecture; and (c) an untrained, physics-regularized dynamic MRI method that uses a quantitative MR model for early stopping. We describe the setup of the hackathon and present reproduction outcomes alongside additional experiments, and we detail fundamental practices for building reproducible codebases.
Measuring and Aligning Abstraction in Vision-Language Models with Medical Taxonomies
Jan 21, 2026Vision-Language Models show strong zero-shot performance for chest X-ray classification, but standard flat metrics fail to distinguish between clinically minor and severe errors. This work investigates how to quantify and mitigate abstraction errors by leveraging medical taxonomies. We benchmark several state-of-the-art VLMs using hierarchical metrics and introduce Catastrophic Abstraction Errors to capture cross-branch mistakes. Our results reveal substantial misalignment of VLMs with clinical taxonomies despite high flat performance. To address this, we propose risk-constrained thresholding and taxonomy-aware fine-tuning with radial embeddings, which reduce severe abstraction errors to below 2 per cent while maintaining competitive performance. These findings highlight the importance of hierarchical evaluation and representation-level alignment for safer and more clinically meaningful deployment of VLMs.
LocBAM: Advancing 3D Patch-Based Image Segmentation by Integrating Location Contex
Jan 21, 2026Patch-based methods are widely used in 3D medical image segmentation to address memory constraints in processing high-resolution volumetric data. However, these approaches often neglect the patch's location within the global volume, which can limit segmentation performance when anatomical context is important. In this paper, we investigate the role of location context in patch-based 3D segmentation and propose a novel attention mechanism, LocBAM, that explicitly processes spatial information. Experiments on BTCV, AMOS22, and KiTS23 demonstrate that incorporating location context stabilizes training and improves segmentation performance, particularly under low patch-to-volume coverage where global context is missing. Furthermore, LocBAM consistently outperforms classical coordinate encoding via CoordConv. Code is publicly available at https://github.com/compai-lab/2026-ISBI-hooft
TomoGraphView: 3D Medical Image Classification with Omnidirectional Slice Representations and Graph Neural Networks
Nov 12, 2025The growing number of medical tomography examinations has necessitated the development of automated methods capable of extracting comprehensive imaging features to facilitate downstream tasks such as tumor characterization, while assisting physicians in managing their growing workload. However, 3D medical image classification remains a challenging task due to the complex spatial relationships and long-range dependencies inherent in volumetric data. Training models from scratch suffers from low data regimes, and the absence of 3D large-scale multimodal datasets has limited the development of 3D medical imaging foundation models. Recent studies, however, have highlighted the potential of 2D vision foundation models, originally trained on natural images, as powerful feature extractors for medical image analysis. Despite these advances, existing approaches that apply 2D models to 3D volumes via slice-based decomposition remain suboptimal. Conventional volume slicing strategies, which rely on canonical planes such as axial, sagittal, or coronal, may inadequately capture the spatial extent of target structures when these are misaligned with standardized viewing planes. Furthermore, existing slice-wise aggregation strategies rarely account for preserving the volumetric structure, resulting in a loss of spatial coherence across slices. To overcome these limitations, we propose TomoGraphView, a novel framework that integrates omnidirectional volume slicing with spherical graph-based feature aggregation. We publicly share our accessible code base at http://github.com/compai-lab/2025-MedIA-kiechle and provide a user-friendly library for omnidirectional volume slicing at https://pypi.org/project/OmniSlicer.
Covariance Descriptors Meet General Vision Encoders: Riemannian Deep Learning for Medical Image Classification
Nov 06, 2025
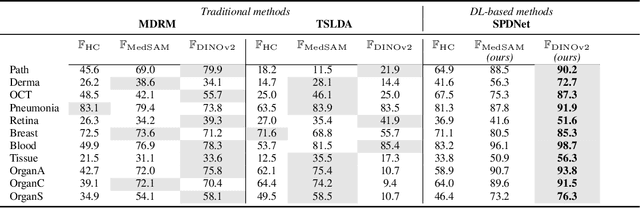
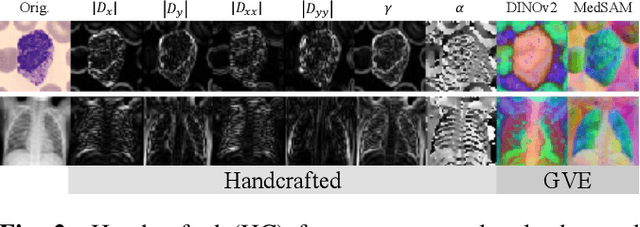
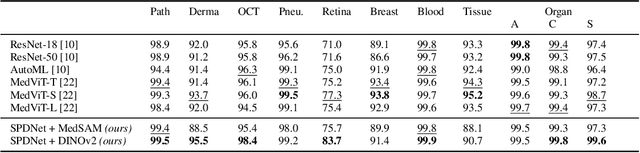
Covariance descriptors capture second-order statistics of image features. They have shown strong performance in general computer vision tasks, but remain underexplored in medical imaging. We investigate their effectiveness for both conventional and learning-based medical image classification, with a particular focus on SPDNet, a classification network specifically designed for symmetric positive definite (SPD) matrices. We propose constructing covariance descriptors from features extracted by pre-trained general vision encoders (GVEs) and comparing them with handcrafted descriptors. Two GVEs - DINOv2 and MedSAM - are evaluated across eleven binary and multi-class datasets from the MedMNSIT benchmark. Our results show that covariance descriptors derived from GVE features consistently outperform those derived from handcrafted features. Moreover, SPDNet yields superior performance to state-of-the-art methods when combined with DINOv2 features. Our findings highlight the potential of combining covariance descriptors with powerful pretrained vision encoders for medical image analysis.
Learning to reason about rare diseases through retrieval-augmented agents
Nov 06, 2025Rare diseases represent the long tail of medical imaging, where AI models often fail due to the scarcity of representative training data. In clinical workflows, radiologists frequently consult case reports and literature when confronted with unfamiliar findings. Following this line of reasoning, we introduce RADAR, Retrieval Augmented Diagnostic Reasoning Agents, an agentic system for rare disease detection in brain MRI. Our approach uses AI agents with access to external medical knowledge by embedding both case reports and literature using sentence transformers and indexing them with FAISS to enable efficient similarity search. The agent retrieves clinically relevant evidence to guide diagnostic decision making on unseen diseases, without the need of additional training. Designed as a model-agnostic reasoning module, RADAR can be seamlessly integrated with diverse large language models, consistently improving their rare pathology recognition and interpretability. On the NOVA dataset comprising 280 distinct rare diseases, RADAR achieves up to a 10.2% performance gain, with the strongest improvements observed for open source models such as DeepSeek. Beyond accuracy, the retrieved examples provide interpretable, literature grounded explanations, highlighting retrieval-augmented reasoning as a powerful paradigm for low-prevalence conditions in medical imaging.