 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and refurbishing ground truth errors during training of deep learning-based echocardiography segmentation models
Apr 14, 2026Deep learning-based medical image segmentation typically relies on ground truth (GT) labels obtained through manual annotation, but these can be prone to random errors or systematic biases. This study examines the robustness of deep learning models to such errors in echocardiography (echo) segmentation and evaluates a novel strategy for detecting and refurbishing erroneous labels during model training. Using the CAMUS dataset, we simulate three error types, then compare a loss-based GT label error detection method with one based on Variance of Gradients (VOG). We also propose a pseudo-labelling approach to refurbish suspected erroneous GT labels. We assess the performance of our proposed approach under varying error levels. Results show that VOG proved highly effective in flagging erroneous GT labels during training. However, a standard U-Net maintained strong performance under random label errors and moderate levels of systematic errors (up to 50%). The detection and refurbishment approach improved performance, particularly under high-error conditions.
Right Regions, Wrong Labels: Semantic Label Flips in Segmentation under Correlation Shift
Apr 14, 2026The robustness of machine learning models can be compromised by spurious correlations between non-causal features in the input data and target labels. A common way to test for such correlations is to train on data where the label is strongly tied to some non-causal cue, then evaluate on examples where that tie no longer holds. This idea is well established for classification tasks, but for semantic segmentation the specific failure modes are not well understood. We show that a model may achieve reasonable overlap while assigning the wrong semantic label, swapping one plausible foreground class for another, even when object boundaries are largely correct. We focus on this semantic label-flip behaviour and quantify it with a simple diagnostic (Flip) that counts how often ground truth foreground pixels are assigned the wrong foreground identity while remaining predicted as foreground. In a setting where category and scene are correlated during training, increasing the correlation consistently widens the gap between common and rare test conditions and increases these within-object label swaps on counterfactual groups. Overall, our results motivate assessing segmentation robustness under distribution shift beyond overlap by decomposing foreground errors into correct pixels, flipped-identity pixels, and missed-to-background pixels. We also propose an entropy-based, ground truth label-free `flip-risk' score, which is computed from foreground identity uncertainty, and show that it can flag flip-prone cases at inference time. Code is available at https://github.com/acharaakshit/label-flips.
Confidence Matters: Uncertainty Quantification and Precision Assessment of Deep Learning-based CMR Biomarker Estimates Using Scan-rescan Data
Mar 25, 2026The performance of deep learning (DL) methods for the analysis of cine cardiovascular magnetic resonance (CMR) is typically assessed in terms of accuracy, overlooking precision. In this work, uncertainty estimation techniques, namely deep ensemble, test-time augmentation, and Monte Carlo dropout, are applied to a state-of-the-art DL pipeline for cardiac functional biomarker estimation, and new distribution-based metrics are proposed for the assessment of biomarker precision. The model achieved high accuracy (average Dice 87%) and point estimate precision on two external validation scan-rescan CMR datasets. However, distribution-based metrics showed that the overlap between scan/rescan confidence intervals was >50% in less than 45% of the cases. Statistical similarity tests between scan and rescan biomarkers also resulted in significant differences for over 65% of the cases. We conclude that, while point estimate metrics might suggest good performance, distributional analyses reveal lower precision, highlighting the need to use more representative metrics to assess scan-rescan agreement.
Localising Shortcut Learning in Pixel Space via Ordinal Scoring Correlations for Attribution Representations (OSCAR)
Dec 21, 2025

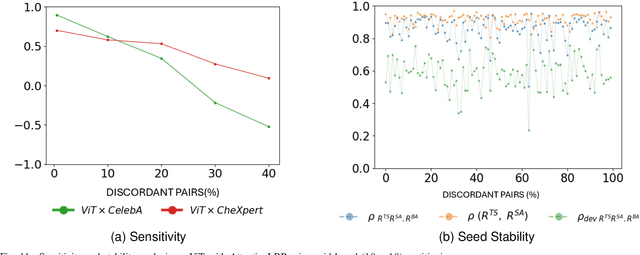

Deep neural networks often exploit shortcuts. These are spurious cues which are associated with output labels in the training data but are unrelated to task semantics. When the shortcut features are associated with sensitive attributes, shortcut learning can lead to biased model performance. Existing methods for localising and understanding shortcut learning are mostly based upon qualitative, image-level inspection and assume cues are human-visible, limiting their use in domains such as medical imaging. We introduce OSCAR (Ordinal Scoring Correlations for Attribution Representations), a model-agnostic framework for quantifying shortcut learning and localising shortcut features. OSCAR converts image-level task attribution maps into dataset-level rank profiles of image regions and compares them across three models: a balanced baseline model (BA), a test model (TS), and a sensitive attribute predictor (SA). By computing pairwise, partial, and deviation-based correlations on these rank profiles, we produce a set of quantitative metrics that characterise the degree of shortcut reliance for TS, together with a ranking of image-level regions that contribute most to it. Experiments on CelebA, CheXpert, and ADNI show that our correlations are (i) stable across seeds and partitions, (ii) sensitive to the level of association between shortcut features and output labels in the training data, and (iii) able to distinguish localised from diffuse shortcut features. As an illustration of the utility of our method, we show how worst-group performance disparities can be reduced using a simple test-time attenuation approach based on the identified shortcut regions. OSCAR provides a lightweight, pixel-space audit that yields statistical decision rules and spatial maps, enabling users to test, localise, and mitigate shortcut reliance. The code is available at https://github.com/acharaakshit/oscar
Invisible Attributes, Visible Biases: Exploring Demographic Shortcuts in MRI-based Alzheimer's Disease Classification
Sep 11, 2025Magnetic resonance imaging (MRI) is the gold standard for brain imaging. Deep learning (DL) algorithms have been proposed to aid in the diagnosis of diseases such as Alzheimer's disease (AD) from MRI scans. However, DL algorithms can suffer from shortcut learning, in which spurious features, not directly related to the output label, are used for prediction. When these features are related to protected attributes, they can lead to performance bias against underrepresented protected groups, such as those defined by race and sex. In this work, we explore the potential for shortcut learning and demographic bias in DL based AD diagnosis from MRI. We first investigate if DL algorithms can identify race or sex from 3D brain MRI scans to establish the presence or otherwise of race and sex based distributional shifts. Next, we investigate whether training set imbalance by race or sex can cause a drop in model performance, indicating shortcut learning and bias. Finally, we conduct a quantitative and qualitative analysis of feature attributions in different brain regions for both the protected attribute and AD classification tasks. Through these experiments, and using multiple datasets and DL models (ResNet and SwinTransformer), we demonstrate the existence of both race and sex based shortcut learning and bias in DL based AD classification. Our work lays the foundation for fairer DL diagnostic tools in brain MRI. The code is provided at https://github.com/acharaakshit/ShortMR
Deep Learning-Based Fetal Lung Segmentation from Diffusion-weighted MRI Images and Lung Maturity Evaluation for Fetal Growth Restriction
Jul 17, 2025Fetal lung maturity is a critical indicator for predicting neonatal outcomes and the need for post-natal intervention, especially for pregnancies affected by fetal growth restriction. Intra-voxel incoherent motion analysis has shown promising results for non-invasive assessment of fetal lung development, but its reliance on manual segmentation is time-consuming, thus limiting its clinical applicability. In this work, we present an automated lung maturity evaluation pipeline for diffusion-weighted magnetic resonance images that consists of a deep learning-based fetal lung segmentation model and a model-fitting lung maturity assessment. A 3D nnU-Net model was trained on manually segmented images selected from the baseline frames of 4D diffusion-weighted MRI scans. The segmentation model demonstrated robust performance, yielding a mean Dice coefficient of 82.14%. Next, voxel-wise model fitting was performed based on both the nnU-Net-predicted and manual lung segmentations to quantify IVIM parameters reflecting tissue microstructure and perfusion. The results suggested no differences between the two. Our work shows that a fully automated pipeline is possible for supporting fetal lung maturity assessment and clinical decision-making.
Personalized MR-Informed Diffusion Models for 3D PET Image Reconstruction
Jun 04, 2025Recent work has shown improved lesion detectability and flexibility to reconstruction hyperparameters (e.g. scanner geometry or dose level) when PET images are reconstructed by leveraging pre-trained diffusion models. Such methods train a diffusion model (without sinogram data) on high-quality, but still noisy, PET images. In this work, we propose a simple method for generating subject-specific PET images from a dataset of multi-subject PET-MR scans, synthesizing "pseudo-PET" images by transforming between different patients' anatomy using image registration. The images we synthesize retain information from the subject's MR scan, leading to higher resolution and the retention of anatomical features compared to the original set of PET images. With simulated and real [$^{18}$F]FDG datasets, we show that pre-training a personalized diffusion model with subject-specific "pseudo-PET" images improves reconstruction accuracy with low-count data. In particular, the method shows promise in combining information from a guidance MR scan without overly imposing anatomical features, demonstrating an improved trade-off between reconstructing PET-unique image features versus features present in both PET and MR. We believe this approach for generating and utilizing synthetic data has further applications to medical imaging tasks, particularly because patient-specific PET images can be generated without resorting to generative deep learning or large training datasets.
Likelihood-Scheduled Score-Based Generative Modeling for Fully 3D PET Image Reconstruction
Dec 05, 2024Medical image reconstruction with pre-trained score-based generative models (SGMs) has advantages over other existing state-of-the-art deep-learned reconstruction methods, including improved resilience to different scanner setups and advanced image distribution modeling. SGM-based reconstruction has recently been applied to simulated positron emission tomography (PET) datasets, showing improved contrast recovery for out-of-distribution lesions relative to the state-of-the-art. However, existing methods for SGM-based reconstruction from PET data suffer from slow reconstruction, burdensome hyperparameter tuning and slice inconsistency effects (in 3D). In this work, we propose a practical methodology for fully 3D reconstruction that accelerates reconstruction and reduces the number of critical hyperparameters by matching the likelihood of an SGM's reverse diffusion process to a current iterate of the maximum-likelihood expectation maximization algorithm. Using the example of low-count reconstruction from simulated $[^{18}$F]DPA-714 datasets, we show our methodology can match or improve on the NRMSE and SSIM of existing state-of-the-art SGM-based PET reconstruction while reducing reconstruction time and the need for hyperparameter tuning. We evaluate our methodology against state-of-the-art supervised and conventional reconstruction algorithms. Finally, we demonstrate a first-ever implementation of SGM-based reconstruction for real 3D PET data, specifically $[^{18}$F]DPA-714 data, where we integrate perpendicular pre-trained SGMs to eliminate slice inconsistency issues.
Generative-Model-Based Fully 3D PET Image Reconstruction by Conditional Diffusion Sampling
Dec 05, 2024Score-based generative models (SGMs) have recently shown promising results for image reconstruction on simulated positron emission tomography (PET) datasets. In this work we have developed and implemented practical methodology for 3D image reconstruction with SGMs, and perform (to our knowledge) the first SGM-based reconstruction of real fully 3D PET data. We train an SGM on full-count reference brain images, and extend methodology to allow SGM-based reconstructions at very low counts (1% of original, to simulate low-dose or short-duration scanning). We then perform reconstructions for multiple independent realisations of 1% count data, allowing us to analyse the bias and variance characteristics of the method. We sample from the learned posterior distribution of the generative algorithm to calculate uncertainty images for our reconstructions. We evaluate the method's performance on real full- and low-count PET data and compare with conventional OSEM and MAP-EM baselines, showing that our SGM-based low-count reconstructions match full-dose reconstructions more closely and in a bias-variance trade-off comparison, our SGM-reconstructed images have lower variance than existing baselines. Future work will compare to supervised deep-learned methods, with other avenues for investigation including how data conditioning affects the SGM's posterior distribution and the algorithm's performance with different tracers.
Multi-Subject Image Synthesis as a Generative Prior for Single-Subject PET Image Reconstruction
Dec 05, 2024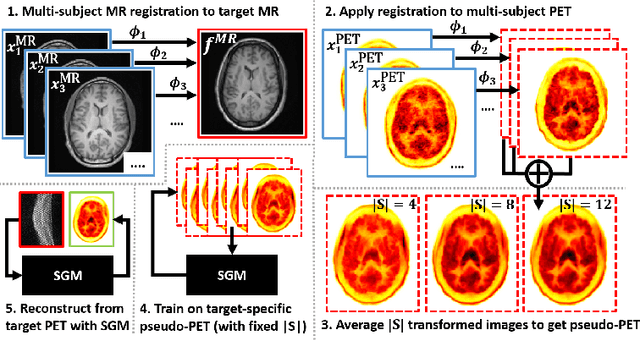
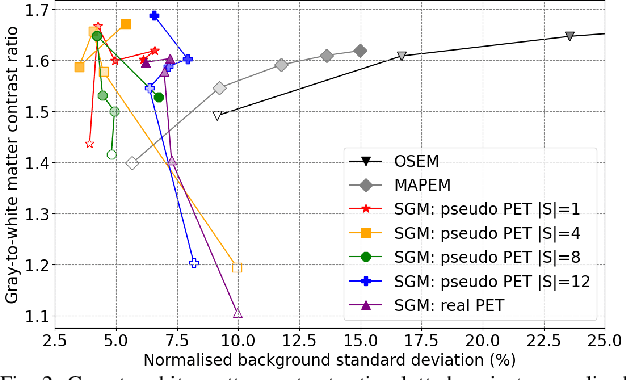
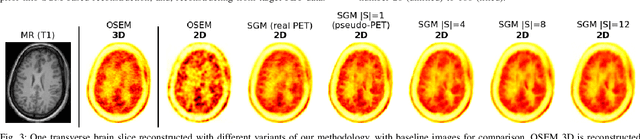
Large high-quality medical image datasets are difficult to acquire but necessary for many deep learning applications. For positron emission tomography (PET), reconstructed image quality is limited by inherent Poisson noise. We propose a novel method for synthesising diverse and realistic pseudo-PET images with improved signal-to-noise ratio. We also show how our pseudo-PET images may be exploited as a generative prior for single-subject PET image reconstruction. Firstly, we perform deep-learned deformable registration of multi-subject magnetic resonance (MR) images paired to multi-subject PET images. We then use the anatomically-learned deformation fields to transform multiple PET images to the same reference space, before averaging random subsets of the transformed multi-subject data to form a large number of varying pseudo-PET images. We observe that using MR information for registration imbues the resulting pseudo-PET images with improved anatomical detail compared to the originals. We consider applications to PET image reconstruction, by generating pseudo-PET images in the same space as the intended single-subject reconstruction and using them as training data for a diffusion model-based reconstruction method. We show visual improvement and reduced background noise in our 2D reconstructions as compared to OSEM, MAP-EM and an existing state-of-the-art diffusion model-based approach. Our method shows the potential for utilising highly subject-specific prior information within a generative reconstruction framework. Future work may compare the benefits of our approach to explicitly MR-guided reconstruction methodologies.