 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoMotion: A Graph-Based Approach to Video Dataset Distillation for Echocardiography
Dec 13, 2025


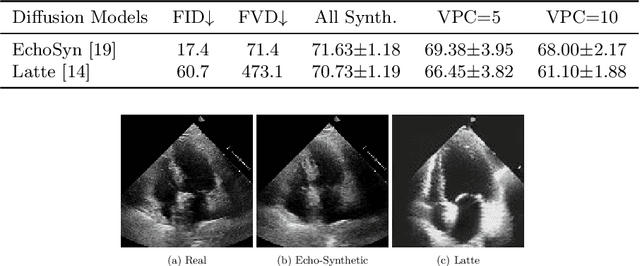
Echocardiography plays a critical role in the diagnosis and monitoring of cardiovascular diseases as a non-invasive real-time assessment of cardiac structure and function. However, the growing scale of echocardiographic video data presents significant challenges in terms of storage, computation, and model training efficiency. Dataset distillation offers a promising solution by synthesizing a compact, informative subset of data that retains the key clinical features of the original dataset. In this work, we propose a novel approach for distilling a compact synthetic echocardiographic video dataset. Our method leverages motion feature extraction to capture temporal dynamics, followed by class-wise graph construction and representative sample selection using the Infomap algorithm. This enables us to select a diverse and informative subset of synthetic videos that preserves the essential characteristics of the original dataset. We evaluate our approach on the EchoNet-Dynamic datasets and achieve a test accuracy of \(69.38\%\) using only \(25\) synthetic videos. These results demonstrate the effectiveness and scalability of our method for medical video dataset distillation.
Self-Supervised Ultrasound Screen Detection
Nov 17, 2025

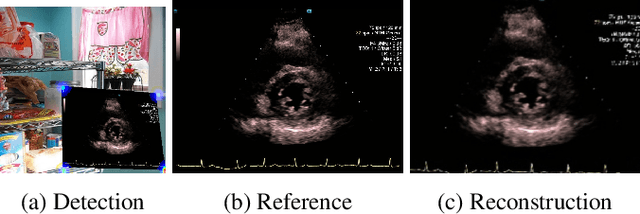

Ultrasound (US) machines display images on a built-in monitor, but routine transfer to hospital systems relies on DICOM. We propose a self-supervised pipeline to extract the US image from a photograph of the monitor. This removes the DICOM bottleneck and enables rapid testing and prototyping of new algorithms. In a proof-of-concept study, the rectified images retained enough visual fidelity to classify cardiac views with a balanced accuracy of 0.79 with respect to the native DICOMs.
EchoFlow: A Foundation Model for Cardiac Ultrasound Image and Video Generation
Mar 28, 2025



Advances in deep learning have significantly enhanced medical image analysis, yet the availability of large-scale medical datasets remains constrained by patient privacy concerns. We present EchoFlow, a novel framework designed to generate high-quality, privacy-preserving synthetic echocardiogram images and videos. EchoFlow comprises four key components: an adversarial variational autoencoder for defining an efficient latent representation of cardiac ultrasound images, a latent image flow matching model for generating accurate latent echocardiogram images, a latent re-identification model to ensure privacy by filtering images anatomically, and a latent video flow matching model for animating latent images into realistic echocardiogram videos conditioned on ejection fraction. We rigorously evaluate our synthetic datasets on the clinically relevant task of ejection fraction regression and demonstrate, for the first time, that downstream models trained exclusively on EchoFlow-generated synthetic datasets achieve performance parity with models trained on real datasets. We release our models and synthetic datasets, enabling broader, privacy-compliant research in medical ultrasound imaging at https://huggingface.co/spaces/HReynaud/EchoFlow.
Uncertainty Propagation for Echocardiography Clinical Metric Estimation via Contour Sampling
Feb 18, 2025Echocardiography plays a fundamental role in the extraction of important clinical parameters (e.g. left ventricular volume and ejection fraction) required to determine the presence and severity of heart-related conditions. When deploying automated techniques for computing these parameters, uncertainty estimation is crucial for assessing their utility. Since clinical parameters are usually derived from segmentation maps, there is no clear path for converting pixel-wise uncertainty values into uncertainty estimates in the downstream clinical metric calculation. In this work, we propose a novel uncertainty estimation method based on contouring rather than segmentation. Our method explicitly predicts contour location uncertainty from which contour samples can be drawn. Finally, the sampled contours can be used to propagate uncertainty to clinical metrics. Our proposed method not only provides accurate uncertainty estimations for the task of contouring but also for the downstream clinical metrics on two cardiac ultrasound datasets. Code is available at: https://github.com/ThierryJudge/contouring-uncertainty.
DeepSPV: An Interpretable Deep Learning Pipeline for 3D Spleen Volume Estimation from 2D Ultrasound Images
Nov 17, 2024



Splenomegaly, the enlargement of the spleen, is an important clinical indicator for various associated medical conditions, such as sickle cell disease (SCD). Spleen length measured from 2D ultrasound is the most widely used metric for characterising spleen size. However, it is still considered a surrogate measure, and spleen volume remains the gold standard for assessing spleen size. Accurate spleen volume measurement typically requires 3D imaging modalities, such as computed tomography or magnetic resonance imaging, but these are not widely available, especially in the Global South which has a high prevalence of SCD. In this work, we introduce a deep learning pipeline, DeepSPV, for precise spleen volume estimation from single or dual 2D ultrasound images. The pipeline involves a segmentation network and a variational autoencoder for learning low-dimensional representations from the estimated segmentations. We investigate three approaches for spleen volume estimation and our best model achieves 86.62%/92.5% mean relative volume accuracy (MRVA) under single-view/dual-view settings, surpassing the performance of human experts. In addition, the pipeline can provide confidence intervals for the volume estimates as well as offering benefits in terms of interpretability, which further support clinicians in decision-making when identifying splenomegaly. We evaluate the full pipeline using a highly realistic synthetic dataset generated by a diffusion model, achieving an overall MRVA of 83.0% from a single 2D ultrasound image. Our proposed DeepSPV is the first work to use deep learning to estimate 3D spleen volume from 2D ultrasound images and can be seamlessly integrated into the current clinical workflow for spleen assessment.
Efficient Semantic Diffusion Architectures for Model Training on Synthetic Echocardiograms
Sep 28, 2024We investigate the utility of diffusion generative models to efficiently synthesise datasets that effectively train deep learning models for image analysis. Specifically, we propose novel $\Gamma$-distribution Latent Denoising Diffusion Models (LDMs) designed to generate semantically guided synthetic cardiac ultrasound images with improved computational efficiency. We also investigate the potential of using these synthetic images as a replacement for real data in training deep networks for left-ventricular segmentation and binary echocardiogram view classification tasks. We compared six diffusion models in terms of the computational cost of generating synthetic 2D echo data, the visual realism of the resulting images, and the performance, on real data, of downstream tasks (segmentation and classification) trained using these synthetic echoes. We compare various diffusion strategies and ODE solvers for their impact on segmentation and classification performance. The results show that our propose architectures significantly reduce computational costs while maintaining or improving downstream task performance compared to state-of-the-art methods. While other diffusion models generated more realistic-looking echo images at higher computational cost, our research suggests that for model training, visual realism is not necessarily related to model performance, and considerable compute costs can be saved by using more efficient models.
Multi-Site Class-Incremental Learning with Weighted Experts in Echocardiography
Jul 31, 2024Building an echocardiography view classifier that maintains performance in real-life cases requires diverse multi-site data, and frequent updates with newly available data to mitigate model drift. Simply fine-tuning on new datasets results in "catastrophic forgetting", and cannot adapt to variations of view labels between sites. Alternatively, collecting all data on a single server and re-training may not be feasible as data sharing agreements may restrict image transfer, or datasets may only become available at different times. Furthermore, time and cost associated with re-training grows with every new dataset. We propose a class-incremental learning method which learns an expert network for each dataset, and combines all expert networks with a score fusion model. The influence of ``unqualified experts'' is minimised by weighting each contribution with a learnt in-distribution score. These weights promote transparency as the contribution of each expert is known during inference. Instead of using the original images, we use learned features from each dataset, which are easier to share and raise fewer licensing and privacy concerns. We validate our work on six datasets from multiple sites, demonstrating significant reductions in training time while improving view classification performance.
BackMix: Mitigating Shortcut Learning in Echocardiography with Minimal Supervision
Jun 27, 2024
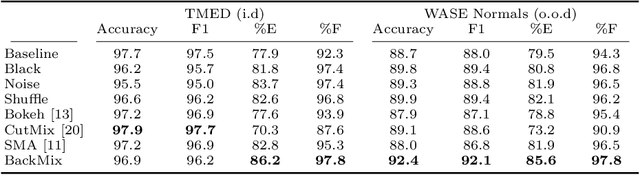
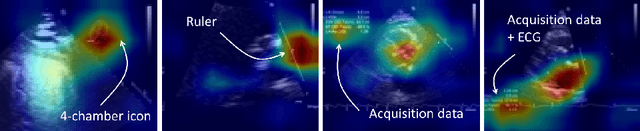
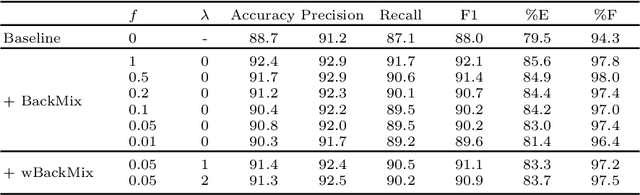
Neural networks can learn spurious correlations that lead to the correct prediction in a validation set, but generalise poorly because the predictions are right for the wrong reason. This undesired learning of naive shortcuts (Clever Hans effect) can happen for example in echocardiogram view classification when background cues (e.g. metadata) are biased towards a class and the model learns to focus on those background features instead of on the image content. We propose a simple, yet effective random background augmentation method called BackMix, which samples random backgrounds from other examples in the training set. By enforcing the background to be uncorrelated with the outcome, the model learns to focus on the data within the ultrasound sector and becomes invariant to the regions outside this. We extend our method in a semi-supervised setting, finding that the positive effects of BackMix are maintained with as few as 5% of segmentation labels. A loss weighting mechanism, wBackMix, is also proposed to increase the contribution of the augmented examples. We validate our method on both in-distribution and out-of-distribution datasets, demonstrating significant improvements in classification accuracy, region focus and generalisability. Our source code is available at: https://github.com/kitbransby/BackMix
EchoNet-Synthetic: Privacy-preserving Video Generation for Safe Medical Data Sharing
Jun 02, 2024To make medical datasets accessible without sharing sensitive patient information, we introduce a novel end-to-end approach for generative de-identification of dynamic medical imaging data. Until now, generative methods have faced constraints in terms of fidelity, spatio-temporal coherence, and the length of generation, failing to capture the complete details of dataset distributions. We present a model designed to produce high-fidelity, long and complete data samples with near-real-time efficiency and explore our approach on a challenging task: generating echocardiogram videos. We develop our generation method based on diffusion models and introduce a protocol for medical video dataset anonymization. As an exemplar, we present EchoNet-Synthetic, a fully synthetic, privacy-compliant echocardiogram dataset with paired ejection fraction labels. As part of our de-identification protocol, we evaluate the quality of the generated dataset and propose to use clinical downstream tasks as a measurement on top of widely used but potentially biased image quality metrics. Experimental outcomes demonstrate that EchoNet-Synthetic achieves comparable dataset fidelity to the actual dataset, effectively supporting the ejection fraction regression task. Code, weights and dataset are available at https://github.com/HReynaud/EchoNet-Synthetic.
Fourier-Net+: Leveraging Band-Limited Representation for Efficient 3D Medical Image Registration
Jul 06, 2023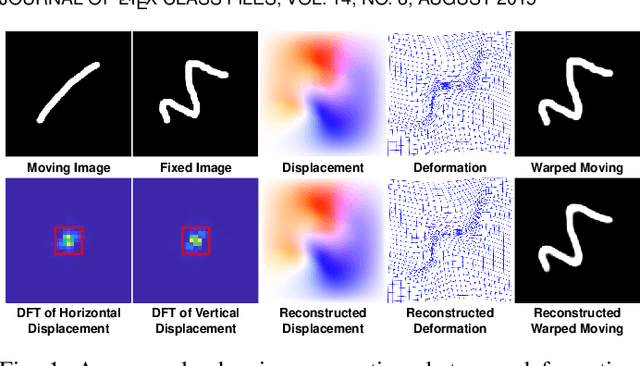
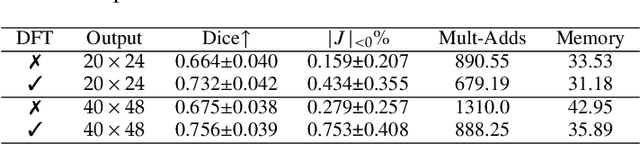
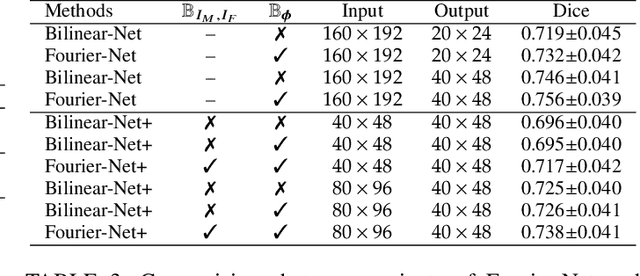
U-Net style networks are commonly utilized in unsupervised image registration to predict dense displacement fields, which for high-resolution volumetric image data is a resource-intensive and time-consuming task. To tackle this challenge, we first propose Fourier-Net, which replaces the costly U-Net style expansive path with a parameter-free model-driven decoder. Instead of directly predicting a full-resolution displacement field, our Fourier-Net learns a low-dimensional representation of the displacement field in the band-limited Fourier domain which our model-driven decoder converts to a full-resolution displacement field in the spatial domain. Expanding upon Fourier-Net, we then introduce Fourier-Net+, which additionally takes the band-limited spatial representation of the images as input and further reduces the number of convolutional layers in the U-Net style network's contracting path. Finally, to enhance the registration performance, we propose a cascaded version of Fourier-Net+. We evaluate our proposed methods on three datasets, on which our proposed Fourier-Net and its variants achieve comparable results with current state-of-the art methods, while exhibiting faster inference speeds, lower memory footprint, and fewer multiply-add operations. With such small computational cost, our Fourier-Net+ enables the efficient training of large-scale 3D registration on low-VRAM GPUs. Our code is publicly available at \url{https://github.com/xi-jia/Fourier-Net}.