 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational Models for Pathology and Endoscopy Images: Application for Gastric Inflammation
Jun 26, 2024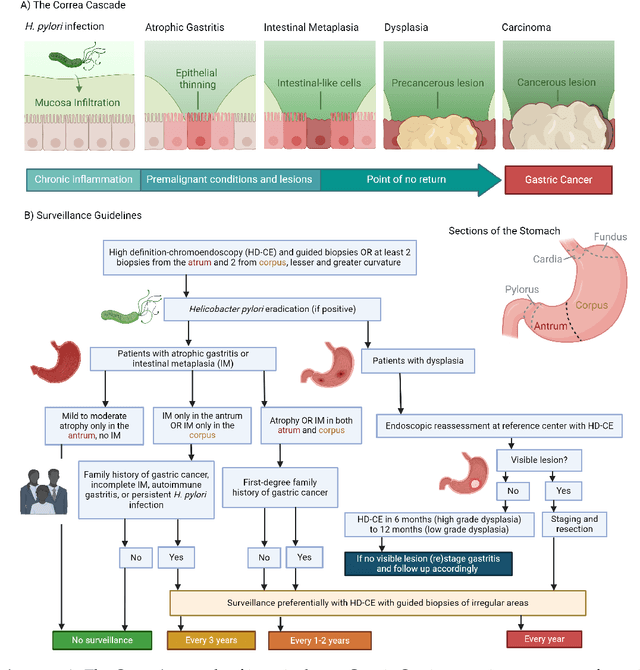
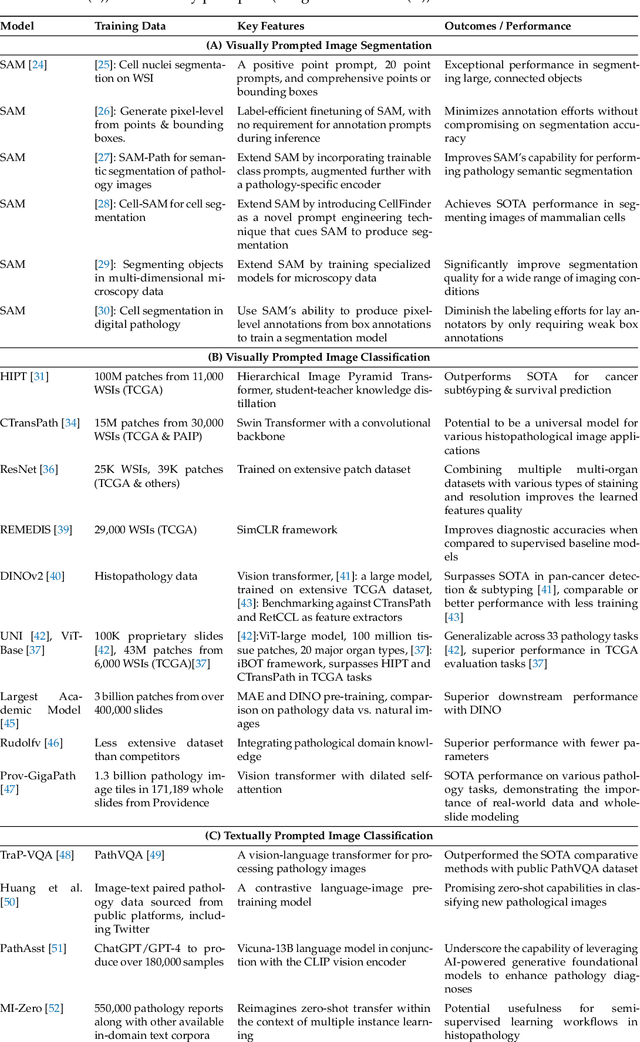
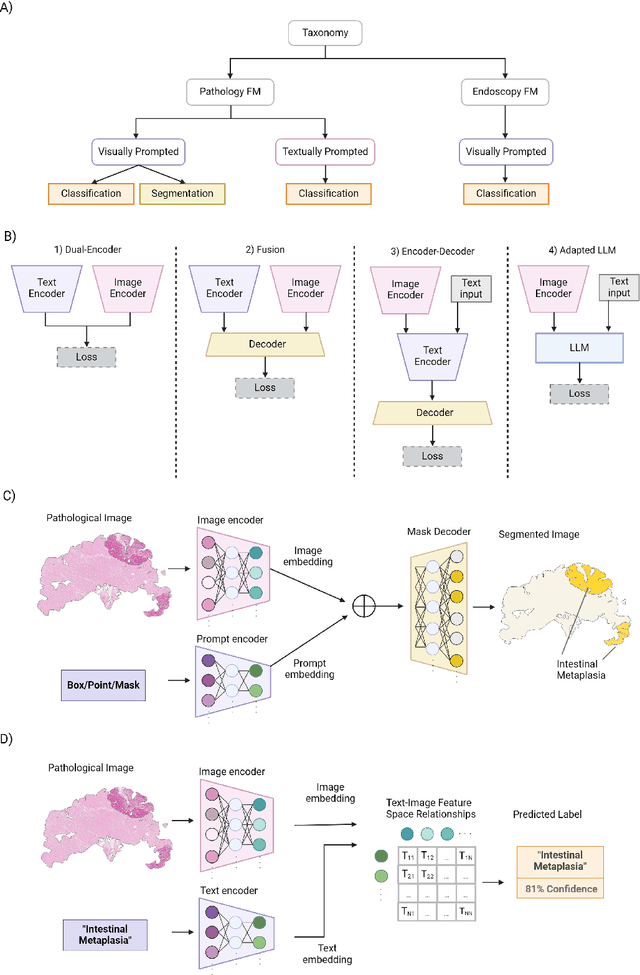
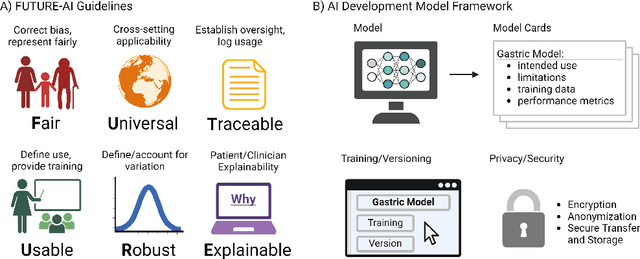
The integration of artificial intelligence (AI) in medical diagnostics represents a significant advancement in managing upper gastrointestinal (GI) cancer, a major cause of global cancer mortality. Specifically for gastric cancer (GC), chronic inflammation causes changes in the mucosa such as atrophy, intestinal metaplasia (IM), dysplasia and ultimately cancer. Early detection through endoscopic regular surveillance is essential for better outcomes. Foundation models (FM), which are machine or deep learning models trained on diverse data and applicable to broad use cases, offer a promising solution to enhance the accuracy of endoscopy and its subsequent pathology image analysis. This review explores the recent advancements, applications, and challenges associated with FM in endoscopy and pathology imaging. We started by elucidating the core principles and architectures underlying these models, including their training methodologies and the pivotal role of large-scale data in developing their predictive capabilities. Moreover, this work discusses emerging trends and future research directions, emphasizing the integration of multimodal data, the development of more robust and equitable models, and the potential for real-time diagnostic support. This review aims to provide a roadmap for researchers and practitioners in navigating the complexities of incorporating FM into clinical practice for prevention/management of GC cases, thereby improving patient outcomes.
Automatic retrieval of corresponding US views in longitudinal examinations
Jun 07, 2023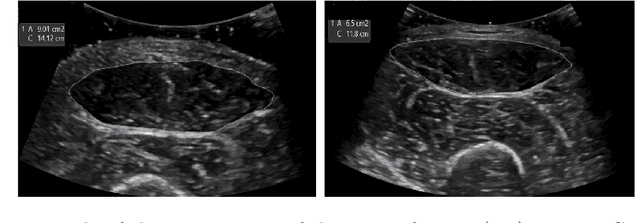

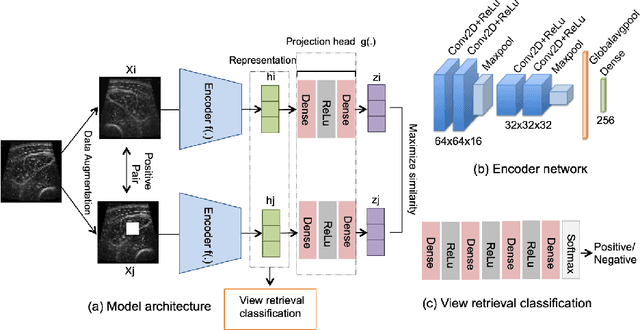
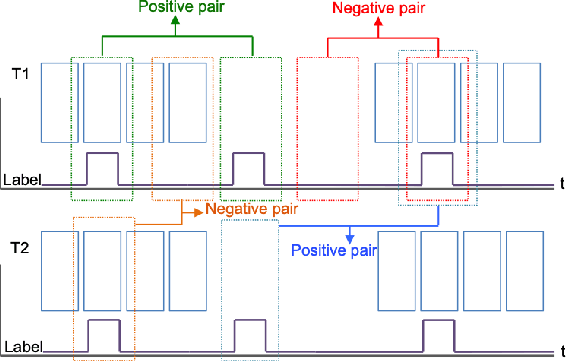
Skeletal muscle atrophy is a common occurrence in critically ill patients in the intensive care unit (ICU) who spend long periods in bed. Muscle mass must be recovered through physiotherapy before patient discharge and ultrasound imaging is frequently used to assess the recovery process by measuring the muscle size over time. However, these manual measurements are subject to large variability, particularly since the scans are typically acquired on different days and potentially by different operators. In this paper, we propose a self-supervised contrastive learning approach to automatically retrieve similar ultrasound muscle views at different scan times. Three different models were compared using data from 67 patients acquired in the ICU. Results indicate that our contrastive model outperformed a supervised baseline model in the task of view retrieval with an AUC of 73.52% and when combined with an automatic segmentation model achieved 5.7%+/-0.24% error in cross-sectional area. Furthermore, a user study survey confirmed the efficacy of our model for muscle view retrieval.
Towards Realistic Ultrasound Fetal Brain Imaging Synthesis
Apr 08, 2023
Prenatal ultrasound imaging is the first-choice modality to assess fetal health. Medical image datasets for AI and ML methods must be diverse (i.e. diagnoses, diseases, pathologies, scanners, demographics, etc), however there are few public ultrasound fetal imaging datasets due to insufficient amounts of clinical data, patient privacy, rare occurrence of abnormalities in general practice, and limited experts for data collection and validation. To address such data scarcity, we proposed generative adversarial networks (GAN)-based models, diffusion-super-resolution-GAN and transformer-based-GAN, to synthesise images of fetal ultrasound brain planes from one public dataset. We reported that GAN-based methods can generate 256x256 pixel size of fetal ultrasound trans-cerebellum brain image plane with stable training losses, resulting in lower FID values for diffusion-super-resolution-GAN (average 7.04 and lower FID 5.09 at epoch 10) than the FID values of transformer-based-GAN (average 36.02 and lower 28.93 at epoch 60). The results of this work illustrate the potential of GAN-based methods to synthesise realistic high-resolution ultrasound images, leading to future work with other fetal brain planes, anatomies, devices and the need of a pool of experts to evaluate synthesised images. Code, data and other resources to reproduce this work are available at \url{https://github.com/budai4medtech/midl2023}.
Empirical Study of Quality Image Assessment for Synthesis of Fetal Head Ultrasound Imaging with DCGANs
Jun 01, 2022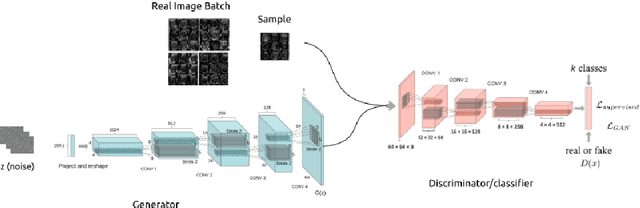
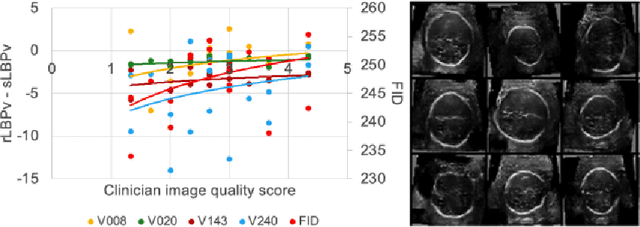
In this work, we present an empirical study of DCGANs for synthetic generation of fetal head ultrasound, consisting of hyperparameter heuristics and image quality assessment. We present experiments to show the impact of different image sizes, epochs, data size input, and learning rates for quality image assessment on four metrics: mutual information (MI), fr\'echet inception distance (FID), peak-signal-to-noise ratio (PSNR), and local binary pattern vector (LBPv). The results show that FID and LBPv have stronger relationship with clinical image quality scores. The resources to reproduce this work are available at \url{https://github.com/xfetus/miua2022}.
B-line Detection in Lung Ultrasound Videos: Cartesian vs Polar Representation
Jul 26, 2021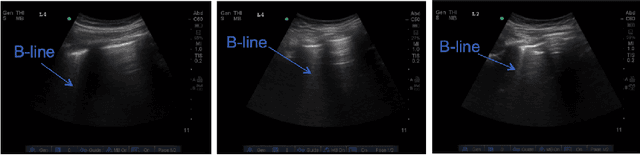

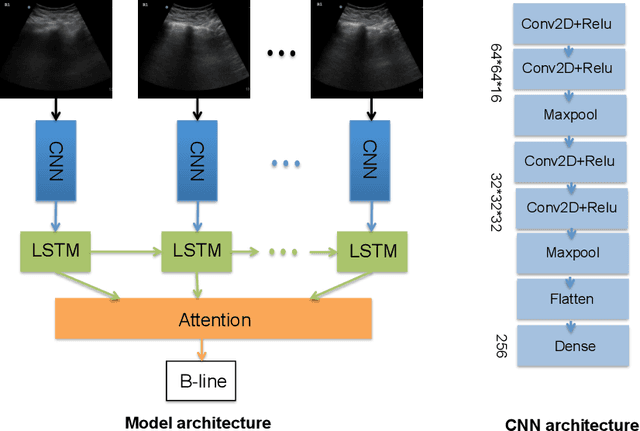
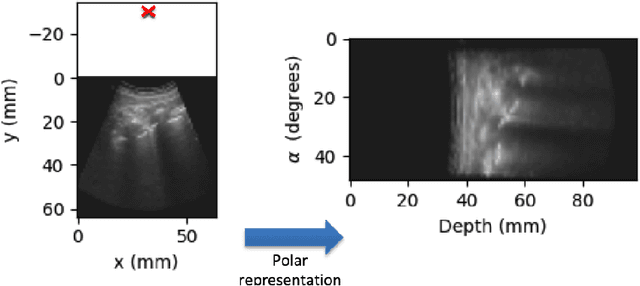
Lung ultrasound (LUS) imaging is becoming popular in the intensive care units (ICU) for assessing lung abnormalities such as the appearance of B-line artefacts as a result of severe dengue. These artefacts appear in the LUS images and disappear quickly, making their manual detection very challenging. They also extend radially following the propagation of the sound waves. As a result, we hypothesize that a polar representation may be more adequate for automatic image analysis of these images. This paper presents an attention-based Convolutional+LSTM model to automatically detect B-lines in LUS videos, comparing performance when image data is taken in Cartesian and polar representations. Results indicate that the proposed framework with polar representation achieves competitive performance compared to the Cartesian representation for B-line classification and that attention mechanism can provide better localization.
Automatic Detection of B-lines in Lung Ultrasound Videos From Severe Dengue Patients
Feb 01, 2021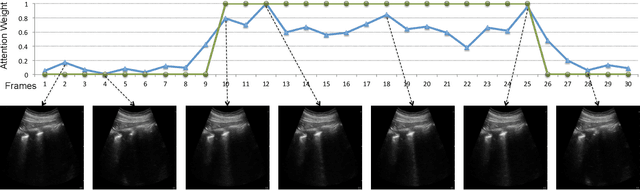
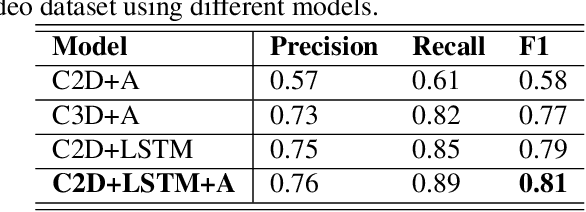
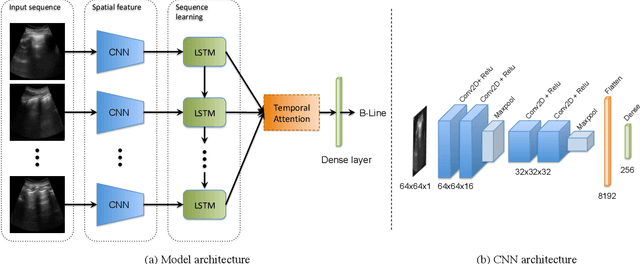
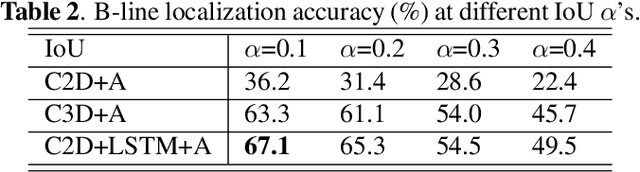
Lung ultrasound (LUS) imaging is used to assess lung abnormalities, including the presence of B-line artefacts due to fluid leakage into the lungs caused by a variety of diseases. However, manual detection of these artefacts is challenging. In this paper, we propose a novel methodology to automatically detect and localize B-lines in LUS videos using deep neural networks trained with weak labels. To this end, we combine a convolutional neural network (CNN) with a long short-term memory (LSTM) network and a temporal attention mechanism. Four different models are compared using data from 60 patients. Results show that our best model can determine whether one-second clips contain B-lines or not with an F1 score of 0.81, and extracts a representative frame with B-lines with an accuracy of 87.5%.
Scene and Environment Monitoring Using Aerial Imagery and Deep Learning
Jun 06, 2019



Unmanned Aerial vehicles (UAV) are a promising technology for smart farming related applications. Aerial monitoring of agriculture farms with UAV enables key decision-making pertaining to crop monitoring. Advancements in deep learning techniques have further enhanced the precision and reliability of aerial imagery based analysis. The capabilities to mount various kinds of sensors (RGB, spectral cameras) on UAV allows remote crop analysis applications such as vegetation classification and segmentation, crop counting, yield monitoring and prediction, crop mapping, weed detection, disease and nutrient deficiency detection and others. A significant amount of studies are found in the literature that explores UAV for smart farming applications. In this paper, a review of studies applying deep learning on UAV imagery for smart farming is presented. Based on the application, we have classified these studies into five major groups including: vegetation identification, classification and segmentation, crop counting and yield predictions, crop mapping, weed detection and crop disease and nutrient deficiency detection. An in depth critical analysis of each study is provided.
* 8
Semi-supervised GAN for Classification of Multispectral Imagery Acquired by UAVs
May 24, 2019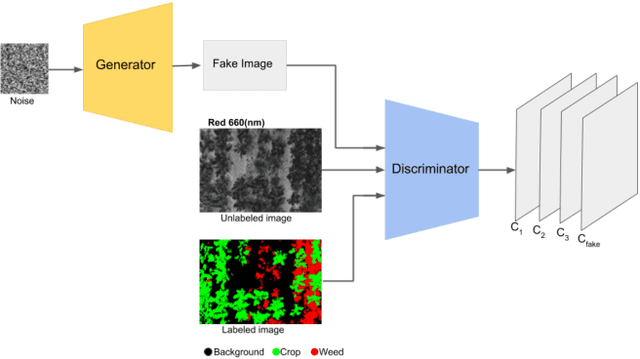
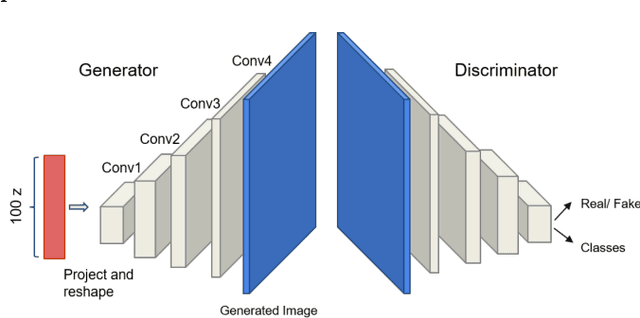
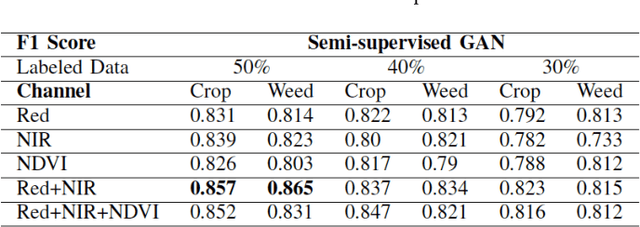
Unmanned aerial vehicles (UAV) are used in precision agriculture (PA) to enable aerial monitoring of farmlands. Intelligent methods are required to pinpoint weed infestations and make optimal choice of pesticide. UAV can fly a multispectral camera and collect data. However, the classification of multispectral images using supervised machine learning algorithms such as convolutional neural networks (CNN) requires large amount of training data. This is a common drawback in deep learning we try to circumvent making use of a semi-supervised generative adversarial networks (GAN), providing a pixel-wise classification for all the acquired multispectral images. Our algorithm consists of a generator network that provides photo-realistic images as extra training data to a multi-class classifier, acting as a discriminator and trained on small amounts of labeled data. The performance of the proposed method is evaluated on the weedNet dataset consisting of multispectral crop and weed images collected by a micro aerial vehicle (MAV). The results by the proposed semi-supervised GAN achieves high classification accuracy and demonstrates the potential of GAN-based methods for the challenging task of multispectral image classification.