 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-DETrack: Identity-Preserving Branch Tracking in Entangled Plant Canopies via Dual Spatiotemporal Evidence
Dec 17, 2025


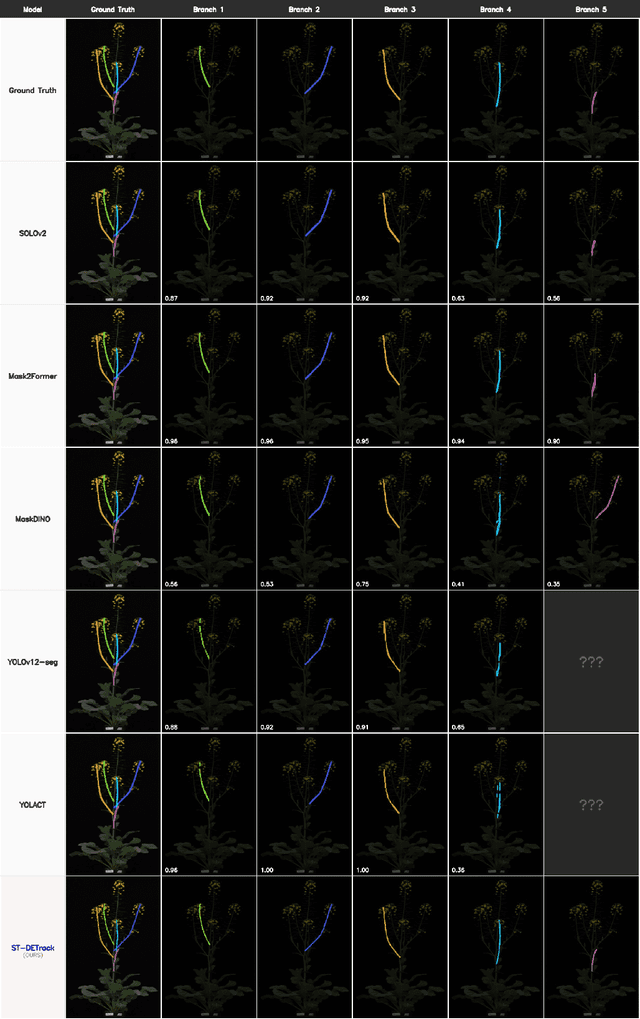
Automated extraction of individual plant branches from time-series imagery is essential for high-throughput phenotyping, yet it remains computationally challenging due to non-rigid growth dynamics and severe identity fragmentation within entangled canopies. To overcome these stage-dependent ambiguities, we propose ST-DETrack, a spatiotemporal-fusion dual-decoder network designed to preserve branch identity from budding to flowering. Our architecture integrates a spatial decoder, which leverages geometric priors such as position and angle for early-stage tracking, with a temporal decoder that exploits motion consistency to resolve late-stage occlusions. Crucially, an adaptive gating mechanism dynamically shifts reliance between these spatial and temporal cues, while a biological constraint based on negative gravitropism mitigates vertical growth ambiguities. Validated on a Brassica napus dataset, ST-DETrack achieves a Branch Matching Accuracy (BMA) of 93.6%, significantly outperforming spatial and temporal baselines by 28.9 and 3.3 percentage points, respectively. These results demonstrate the method's robustness in maintaining long-term identity consistency amidst complex, dynamic plant architectures.
Botany Meets Robotics in Alpine Scree Monitoring
Nov 16, 2025According to the European Union's Habitat Directive, habitat monitoring plays a critical role in response to the escalating problems posed by biodiversity loss and environmental degradation. Scree habitats, hosting unique and often endangered species, face severe threats from climate change due to their high-altitude nature. Traditionally, their monitoring has required highly skilled scientists to conduct extensive fieldwork in remote, potentially hazardous locations, making the process resource-intensive and time-consuming. This paper presents a novel approach for scree habitat monitoring using a legged robot to assist botanists in data collection and species identification. Specifically, we deployed the ANYmal C robot in the Italian Alpine bio-region in two field campaigns spanning two years and leveraged deep learning to detect and classify key plant species of interest. Our results demonstrate that agile legged robots can navigate challenging terrains and increase the frequency and efficiency of scree monitoring. When paired with traditional phytosociological surveys performed by botanists, this robotics-assisted protocol not only streamlines field operations but also enhances data acquisition, storage, and usage. The outcomes of this research contribute to the evolving landscape of robotics in environmental science, paving the way for a more comprehensive and sustainable approach to habitat monitoring and preservation.
Content-aware Density Map for Crowd Counting and Density Estimation
Jun 17, 2019
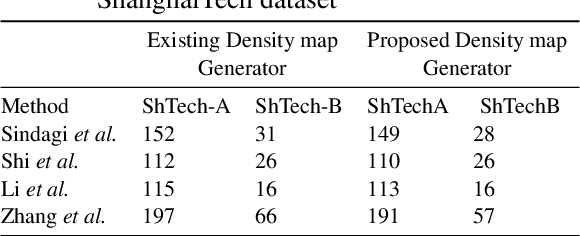
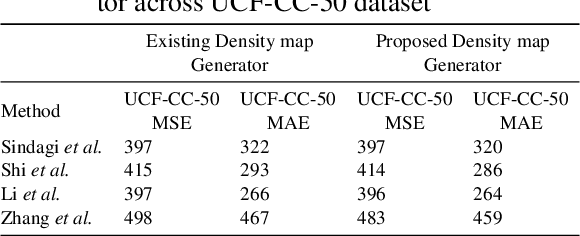

Precise knowledge about the size of a crowd, its density and flow can provide valuable information for safety and security applications, event planning, architectural design and to analyze consumer behavior. Creating a powerful machine learning model, to employ for such applications requires a large and highly accurate and reliable dataset. Unfortunately the existing crowd counting and density estimation benchmark datasets are not only limited in terms of their size, but also lack annotation, in general too time consuming to implement. This paper attempts to address this very issue through a content aware technique, uses combinations of Chan-Vese segmentation algorithm, two-dimensional Gaussian filter and brute-force nearest neighbor search. The results shows that by simply replacing the commonly used density map generators with the proposed method, higher level of accuracy can be achieved using the existing state of the art models.
Scene and Environment Monitoring Using Aerial Imagery and Deep Learning
Jun 06, 2019



Unmanned Aerial vehicles (UAV) are a promising technology for smart farming related applications. Aerial monitoring of agriculture farms with UAV enables key decision-making pertaining to crop monitoring. Advancements in deep learning techniques have further enhanced the precision and reliability of aerial imagery based analysis. The capabilities to mount various kinds of sensors (RGB, spectral cameras) on UAV allows remote crop analysis applications such as vegetation classification and segmentation, crop counting, yield monitoring and prediction, crop mapping, weed detection, disease and nutrient deficiency detection and others. A significant amount of studies are found in the literature that explores UAV for smart farming applications. In this paper, a review of studies applying deep learning on UAV imagery for smart farming is presented. Based on the application, we have classified these studies into five major groups including: vegetation identification, classification and segmentation, crop counting and yield predictions, crop mapping, weed detection and crop disease and nutrient deficiency detection. An in depth critical analysis of each study is provided.
* 8
Smart IoT Cameras for Crowd Analysis based on augmentation for automatic pedestrian detection, simulation and annotation
Jun 06, 2019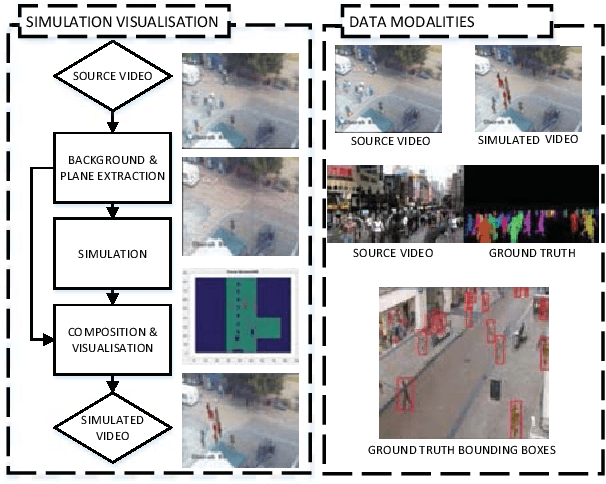


Smart video sensors for applications related to surveillance and security are IOT-based as they use Internet for various purposes. Such applications include crowd behaviour monitoring and advanced decision support systems operating and transmitting information over internet. The analysis of crowd and pedestrian behaviour is an important task for smart IoT cameras and in particular video processing. In order to provide related behavioural models, simulation and tracking approaches have been considered in the literature. In both cases ground truth is essential to train deep models and provide a meaningful quantitative evaluation. We propose a framework for crowd simulation and automatic data generation and annotation that supports multiple cameras and multiple targets. The proposed approach is based on synthetically generated human agents, augmented frames and compositing techniques combined with path finding and planning methods. A number of popular crowd and pedestrian data sets were used to validate the model, and scenarios related to annotation and simulation were considered.
Semi-supervised GAN for Classification of Multispectral Imagery Acquired by UAVs
May 24, 2019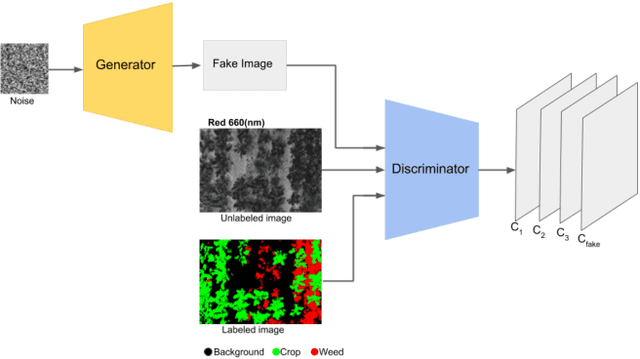
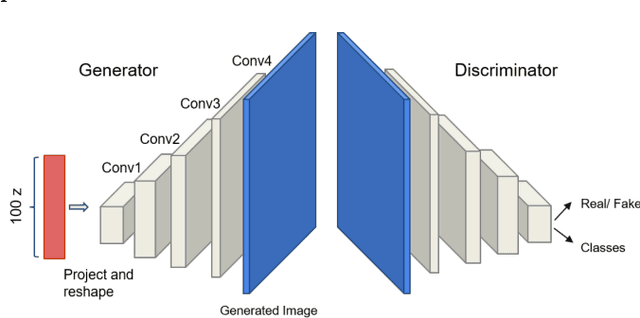
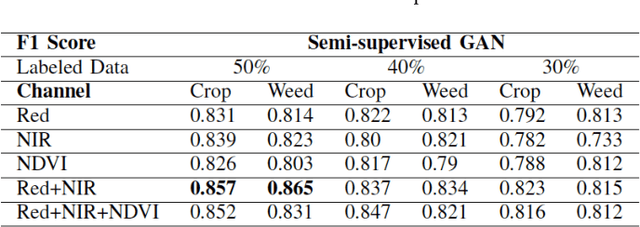
Unmanned aerial vehicles (UAV) are used in precision agriculture (PA) to enable aerial monitoring of farmlands. Intelligent methods are required to pinpoint weed infestations and make optimal choice of pesticide. UAV can fly a multispectral camera and collect data. However, the classification of multispectral images using supervised machine learning algorithms such as convolutional neural networks (CNN) requires large amount of training data. This is a common drawback in deep learning we try to circumvent making use of a semi-supervised generative adversarial networks (GAN), providing a pixel-wise classification for all the acquired multispectral images. Our algorithm consists of a generator network that provides photo-realistic images as extra training data to a multi-class classifier, acting as a discriminator and trained on small amounts of labeled data. The performance of the proposed method is evaluated on the weedNet dataset consisting of multispectral crop and weed images collected by a micro aerial vehicle (MAV). The results by the proposed semi-supervised GAN achieves high classification accuracy and demonstrates the potential of GAN-based methods for the challenging task of multispectral image classification.
A Comparison of Embedded Deep Learning Methods for Person Detection
Jan 08, 2019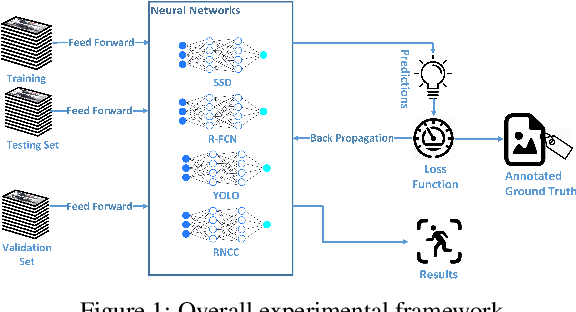
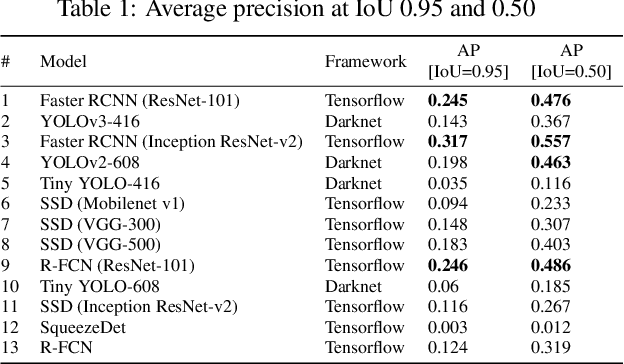


Recent advancements in parallel computing, GPU technology and deep learning provide a new platform for complex image processing tasks such as person detection to flourish. Person detection is fundamental preliminary operation for several high level computer vision tasks. One industry that can significantly benefit from person detection is retail. In recent years, various studies attempt to find an optimal solution for person detection using neural networks and deep learning. This study conducts a comparison among the state of the art deep learning base object detector with the focus on person detection performance in indoor environments. Performance of various implementations of YOLO, SSD, RCNN, R-FCN and SqueezeDet have been assessed using our in-house proprietary dataset which consists of over 10 thousands indoor images captured form shopping malls, retails and stores. Experimental results indicate that, Tiny YOLO-416 and SSD (VGG-300) are the fastest and Faster-RCNN (Inception ResNet-v2) and R-FCN (ResNet-101) are the most accurate detectors investigated in this study. Further analysis shows that YOLO v3-416 delivers relatively accurate result in a reasonable amount of time, which makes it an ideal model for person detection in embedded platforms.
Summarizing Videos with Attention
Dec 05, 2018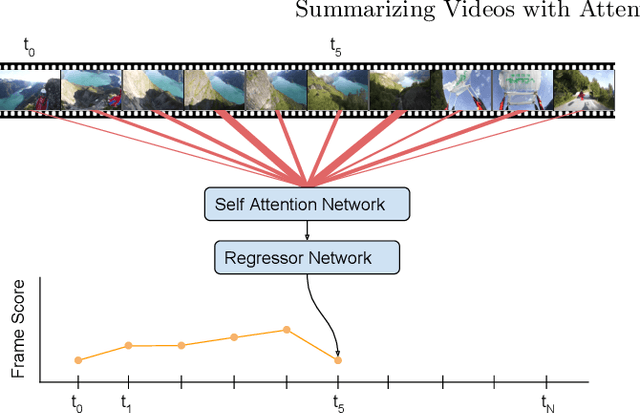

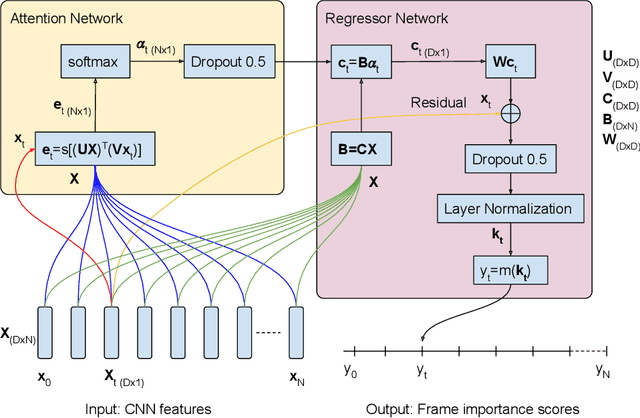
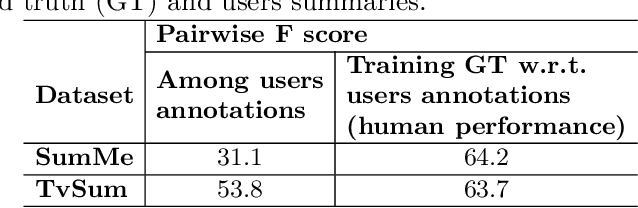
In this work we propose a novel method for supervised, keyshots based video summarization by applying a conceptually simple and computationally efficient soft, self-attention mechanism. Current state of the art methods leverage bi-directional recurrent networks such as BiLSTM combined with attention. These networks are complex to implement and computationally demanding compared to fully connected networks. To that end we propose a simple, self-attention based network for video summarization which performs the entire sequence to sequence transformation in a single feed forward pass and single backward pass during training. Our method sets a new state of the art results on two benchmarks TvSum and SumMe, commonly used in this domain.
Object 3D Reconstruction based on Photometric Stereo and Inverted Rendering
Nov 06, 2018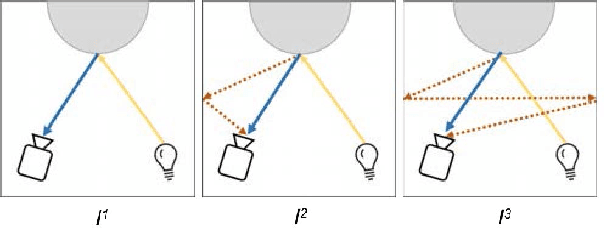



Methods for 3D reconstruction such as Photometric stereo recover the shape and reflectance properties using multiple images of an object taken with variable lighting conditions from a fixed viewpoint. Photometric stereo assumes that a scene is illuminated only directly by the illumination source. As result, indirect illumination effects due to inter-reflections introduce strong biases in the recovered shape. Our suggested approach is to recover scene properties in the presence of indirect illumination. To this end, we proposed an iterative PS method combined with a reverted Monte-Carlo ray tracing algorithm to overcome the inter-reflection effects aiming to separate the direct and indirect lighting. This approach iteratively reconstructs a surface considering both the environment around the object and its concavities. We demonstrate and evaluate our approach using three datasets and the overall results illustrate improvement over the classic PS approaches.
Superframes, A Temporal Video Segmentation
Apr 18, 2018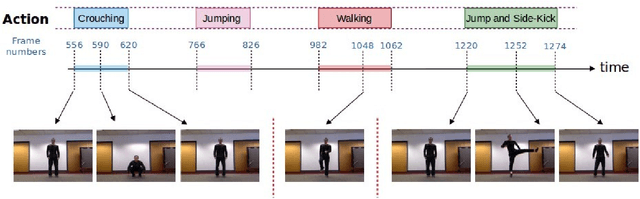

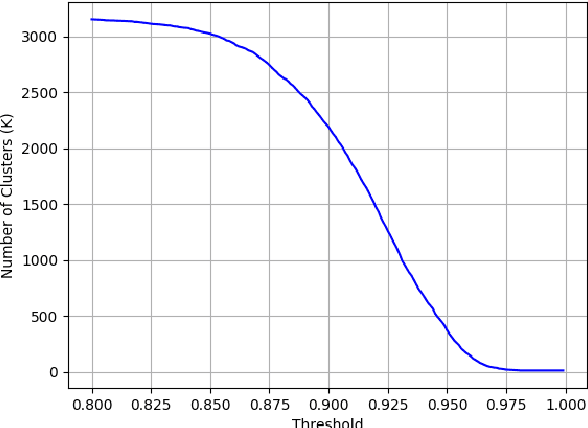
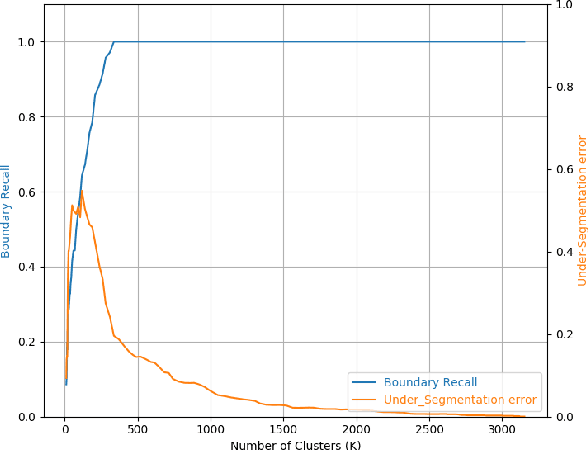
The goal of video segmentation is to turn video data into a set of concrete motion clusters that can be easily interpreted as building blocks of the video. There are some works on similar topics like detecting scene cuts in a video, but there is few specific research on clustering video data into the desired number of compact segments. It would be more intuitive, and more efficient, to work with perceptually meaningful entity obtained from a low-level grouping process which we call it superframe. This paper presents a new simple and efficient technique to detect superframes of similar content patterns in videos. We calculate the similarity of content-motion to obtain the strength of change between consecutive frames. With the help of existing optical flow technique using deep models, the proposed method is able to perform more accurate motion estimation efficiently. We also propose two criteria for measuring and comparing the performance of different algorithms on various databases. Experimental results on the videos from benchmark databases have demonstrated the effectiveness of the proposed method.