 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Affect Analysis for Service-Oriented Systems: Advances, Challenges, and Future Visions
Jun 13, 2026Facial Affect Analysis (FAA) is evolving from a stand-alone recognition task into a reusable perception capability for Service-Oriented Software Ecosystems (SoSE). This paper preserves the FAA methodological core while reframing recent advances through systems-engineering requirements for composable and dependable services. We review representative progress in static and dynamic expression analysis, action-unit and micro-expression modeling, and modern CNN, Transformer, graph, and hybrid architectures, then interpret these advances by their operational fit in edge, cloud, and hybrid service pipelines. The synthesis emphasizes SoSE concerns that determine deployability: service contracts for uncertainty-aware outputs, latency and availability envelopes, lifecycle monitoring and recalibration, governance-aware integration, and interoperability across independently evolving components. Our analysis shows that benchmark gains alone are insufficient for SoSE readiness; robustness under shift, intervention stability, fairness, privacy posture, and runtime guarantees are equally critical. We conclude with a roadmap for treating FAA as an operational service component with explicit interfaces, measurable quality attributes, and accountable lifecycle management.
Facial Expression Recognition in the Deep Learning Era: A Systematic Multi-Criteria Review of Methods, Models, Datasets, Performance, Challenges, and Future Research Directions
Jun 07, 2026Facial Expression Recognition (FER) has advanced rapidly over the last decade, driven by the shift from handcrafted descriptors and shallow classifiers to deep convolutional, attention-based, vision-language, and foundation-model architectures, and by the parallel growth of large-scale in-the-wild benchmarks spanning categorical, dimensional, compound, micro-expression, Action Unit (AU), and intensity-estimation tasks. Yet the deep learning-based FER landscape has so far been reviewed only along narrow task-, architecture-, or application-specific axes, leaving a holistic, systematically organized account of its recent advances missing. This survey addresses that gap with a comprehensive review of recent deep learning-based FER, explicitly linked to the wider Facial Affect Recognition (FAR) domain. Its main contributions are: a) A description of FER's evolution into five distinct phases, from handcrafted features and classical machine learning to attention-based, vision-language, and foundation-model approaches, with the key milestone works of each, b) A multi-criteria taxonomy analyzing the literature along seven complementary axes: recognition task, input modality, face pre-processing pipeline, network architecture, learning strategy, acquisition setting, and application domain, c) A per-criterion comparative analysis, with critical insights into the strengths and limitations of each category under in-the-wild conditions, d) A task-organized review of public FER datasets, with their annotation schemes, modalities, and evaluation protocols, e) A compilation of performance metrics and a per-task quantitative comparison of representative state-of-the-art methods on widely adopted benchmarks, and f) A discussion of current challenges and promising future directions.
Malware Detection in Docker Containers: An Image is Worth a Thousand Logs
Apr 04, 2025



Malware detection is increasingly challenged by evolving techniques like obfuscation and polymorphism, limiting the effectiveness of traditional methods. Meanwhile, the widespread adoption of software containers has introduced new security challenges, including the growing threat of malicious software injection, where a container, once compromised, can serve as entry point for further cyberattacks. In this work, we address these security issues by introducing a method to identify compromised containers through machine learning analysis of their file systems. We cast the entire software containers into large RGB images via their tarball representations, and propose to use established Convolutional Neural Network architectures on a streaming, patch-based manner. To support our experiments, we release the COSOCO dataset--the first of its kind--containing 3364 large-scale RGB images of benign and compromised software containers at https://huggingface.co/datasets/k3ylabs/cosoco-image-dataset. Our method detects more malware and achieves higher F1 and Recall scores than all individual and ensembles of VirusTotal engines, demonstrating its effectiveness and setting a new standard for identifying malware-compromised software containers.
StatAvg: Mitigating Data Heterogeneity in Federated Learning for Intrusion Detection Systems
May 20, 2024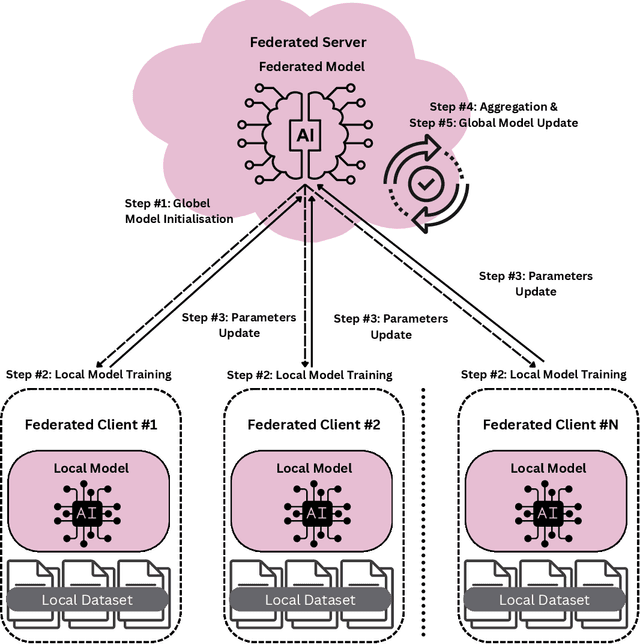
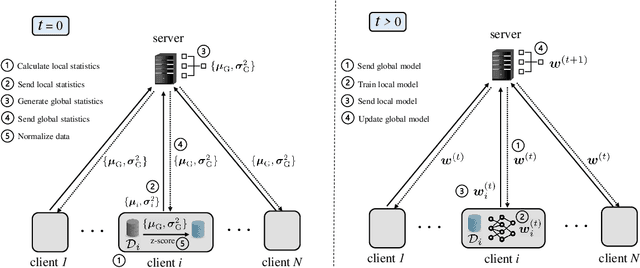
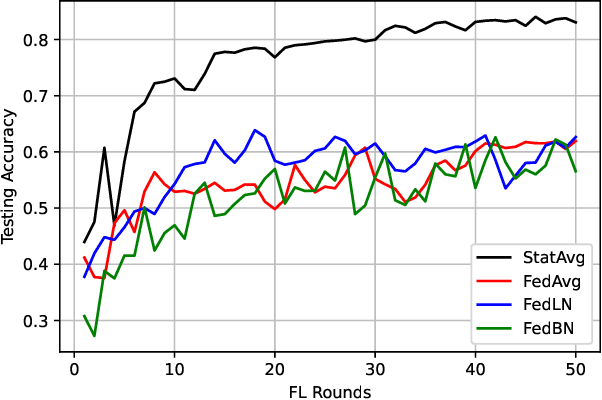
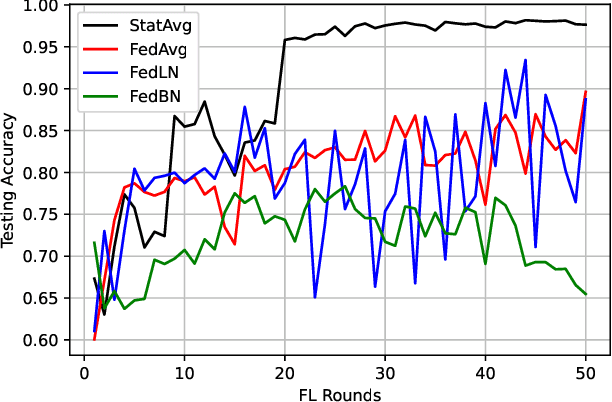
Federated learning (FL) is a decentralized learning technique that enables participating devices to collaboratively build a shared Machine Leaning (ML) or Deep Learning (DL) model without revealing their raw data to a third party. Due to its privacy-preserving nature, FL has sparked widespread attention for building Intrusion Detection Systems (IDS) within the realm of cybersecurity. However, the data heterogeneity across participating domains and entities presents significant challenges for the reliable implementation of an FL-based IDS. In this paper, we propose an effective method called Statistical Averaging (StatAvg) to alleviate non-independently and identically (non-iid) distributed features across local clients' data in FL. In particular, StatAvg allows the FL clients to share their individual data statistics with the server, which then aggregates this information to produce global statistics. The latter are shared with the clients and used for universal data normalisation. It is worth mentioning that StatAvg can seamlessly integrate with any FL aggregation strategy, as it occurs before the actual FL training process. The proposed method is evaluated against baseline approaches using datasets for network and host Artificial Intelligence (AI)-powered IDS. The experimental results demonstrate the efficiency of StatAvg in mitigating non-iid feature distributions across the FL clients compared to the baseline methods.
Evaluation of Environmental Conditions on Object Detection using Oriented Bounding Boxes for AR Applications
Jun 29, 2023


The objective of augmented reality (AR) is to add digital content to natural images and videos to create an interactive experience between the user and the environment. Scene analysis and object recognition play a crucial role in AR, as they must be performed quickly and accurately. In this study, a new approach is proposed that involves using oriented bounding boxes with a detection and recognition deep network to improve performance and processing time. The approach is evaluated using two datasets: a real image dataset (DOTA dataset) commonly used for computer vision tasks, and a synthetic dataset that simulates different environmental, lighting, and acquisition conditions. The focus of the evaluation is on small objects, which are difficult to detect and recognise. The results indicate that the proposed approach tends to produce better Average Precision and greater accuracy for small objects in most of the tested conditions.
The evolution of argumentation mining: From models to social media and emerging tools
Jul 04, 2019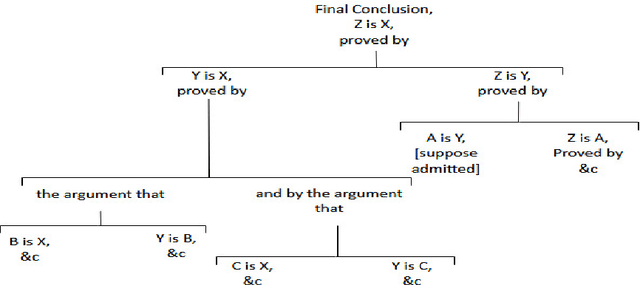
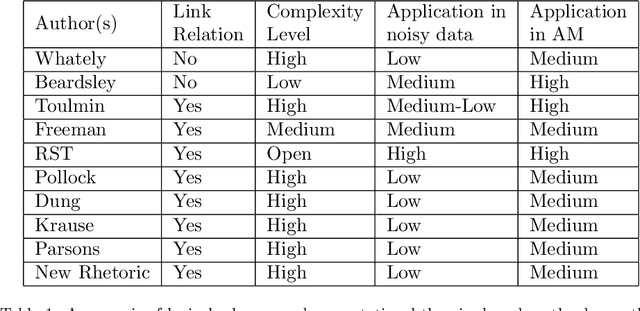
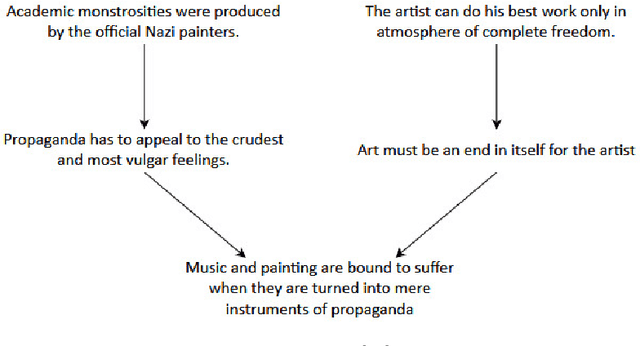
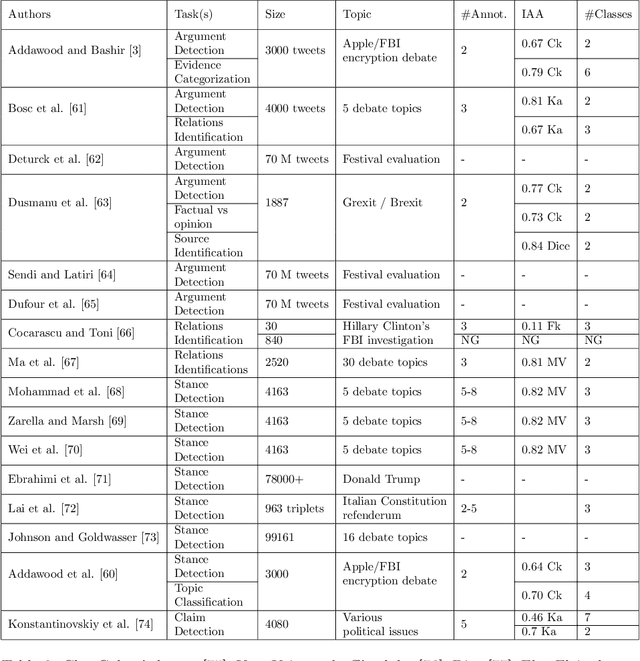
Argumentation mining is a rising subject in the computational linguistics domain focusing on extracting structured arguments from natural text, often from unstructured or noisy text. The initial approaches on modeling arguments was aiming to identify a flawless argument on specific fields (Law, Scientific Papers) serving specific needs (completeness, effectiveness). With the emerge of Web 2.0 and the explosion in the use of social media both the diffusion of the data and the argument structure have changed. In this survey article, we bridge the gap between theoretical approaches of argumentation mining and pragmatic schemes that satisfy the needs of social media generated data, recognizing the need for adapting more flexible and expandable schemes, capable to adjust to the argumentation conditions that exist in social media. We review, compare, and classify existing approaches, techniques and tools, identifying the positive outcome of combining tasks and features, and eventually propose a conceptual architecture framework. The proposed theoretical framework is an argumentation mining scheme able to identify the distinct sub-tasks and capture the needs of social media text, revealing the need for adopting more flexible and extensible frameworks.
* Journal of Information Processing & Management, Elsevier - Accepted Version
Smart IoT Cameras for Crowd Analysis based on augmentation for automatic pedestrian detection, simulation and annotation
Jun 06, 2019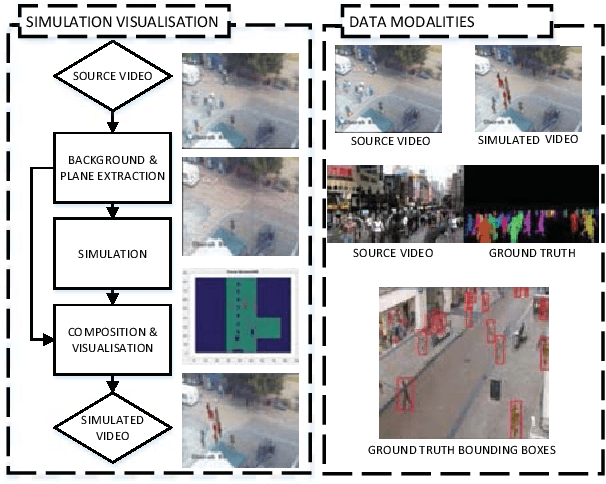
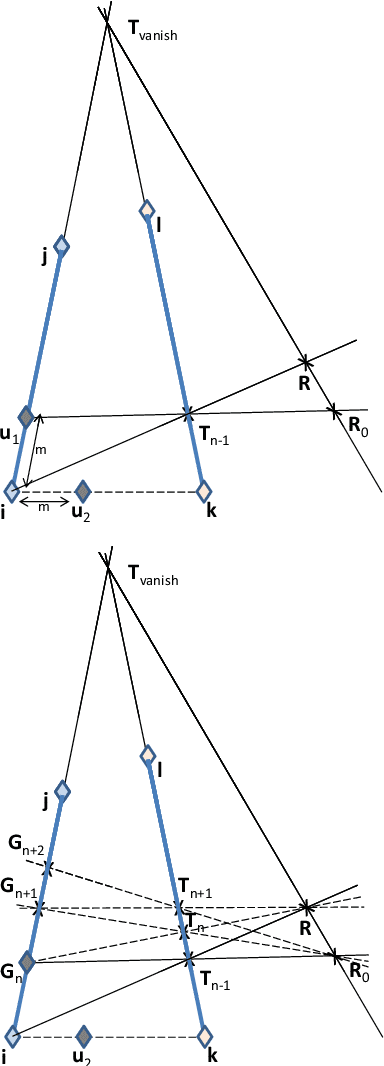


Smart video sensors for applications related to surveillance and security are IOT-based as they use Internet for various purposes. Such applications include crowd behaviour monitoring and advanced decision support systems operating and transmitting information over internet. The analysis of crowd and pedestrian behaviour is an important task for smart IoT cameras and in particular video processing. In order to provide related behavioural models, simulation and tracking approaches have been considered in the literature. In both cases ground truth is essential to train deep models and provide a meaningful quantitative evaluation. We propose a framework for crowd simulation and automatic data generation and annotation that supports multiple cameras and multiple targets. The proposed approach is based on synthetically generated human agents, augmented frames and compositing techniques combined with path finding and planning methods. A number of popular crowd and pedestrian data sets were used to validate the model, and scenarios related to annotation and simulation were considered.