 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Environmental Conditions on Object Detection using Oriented Bounding Boxes for AR Applications
Jun 29, 2023


The objective of augmented reality (AR) is to add digital content to natural images and videos to create an interactive experience between the user and the environment. Scene analysis and object recognition play a crucial role in AR, as they must be performed quickly and accurately. In this study, a new approach is proposed that involves using oriented bounding boxes with a detection and recognition deep network to improve performance and processing time. The approach is evaluated using two datasets: a real image dataset (DOTA dataset) commonly used for computer vision tasks, and a synthetic dataset that simulates different environmental, lighting, and acquisition conditions. The focus of the evaluation is on small objects, which are difficult to detect and recognise. The results indicate that the proposed approach tends to produce better Average Precision and greater accuracy for small objects in most of the tested conditions.
Classic versus deep approaches to address computer vision challenges
Jan 24, 2021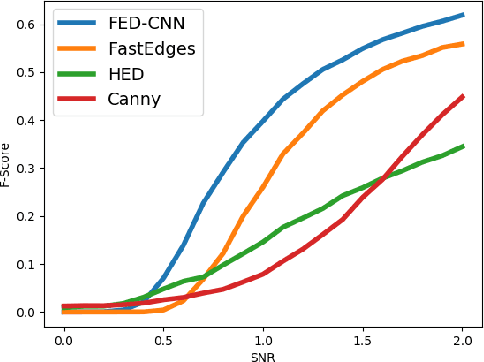
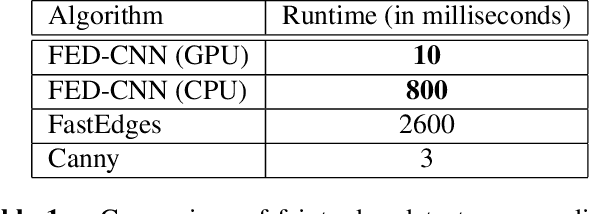

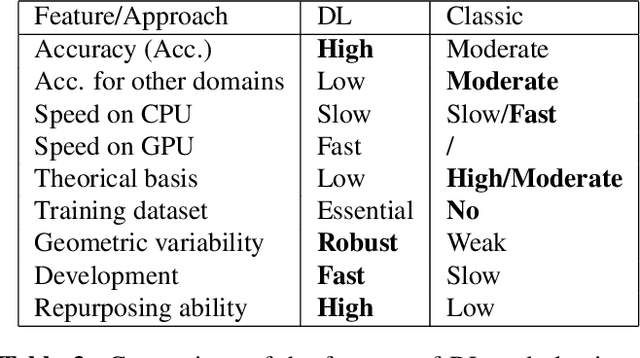
Computer vision and image processing address many challenging applications. While the last decade has seen deep neural network architectures revolutionizing those fields, early methods relied on 'classic', i.e., non-learned approaches. In this study, we explore the differences between classic and deep learning (DL) algorithms to gain new insight regarding which is more suitable for a given application. The focus is on two challenging ill-posed problems, namely faint edge detection and multispectral image registration, studying recent state-of-the-art DL and classic solutions. While those DL algorithms outperform classic methods in terms of accuracy and development time, they tend to have higher resource requirements and are unable to perform outside their training space. Moreover, classic algorithms are more transparent, which facilitates their adoption for real-life applications. As both classes of approaches have unique strengths and limitations, the choice of a solution is clearly application dependent.