 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisible and infrared self-supervised fusion trained on a single example
Jul 09, 2023



This paper addresses the problem of visible (RGB) to Near-Infrared (NIR) image fusion. Multispectral imaging is an important task relevant to image processing and computer vision, even more, since the development of the RGBT sensor. While the visible image sees color and suffers from noise, haze, and clouds, the NIR channel captures a clearer picture and it is significantly required by applications such as dehazing or object detection. The proposed approach fuses these two aligned channels by training a Convolutional-Neural-Network (CNN) by a Self-Supervised-Learning (SSL) on a single example. For each such pair, RGB and IR, the network is trained for seconds to deduce the final fusion. The SSL is based on Sturcture-of-Similarity (SSIM) loss combined with Edge-Preservation (EP) loss. The labels for the SSL are the input channels themselves. This fusion preserves the relevant detail of each spectral channel while not based on a heavy training process. In the experiments section, the proposed approach achieves better qualitative and quantitative multispectral fusion results with respect to other recent methods, that are not based on large dataset training.
Defect Detection Approaches Based on Simulated Reference Image
Mar 21, 2023



This work is addressing the problem of defect anomaly detection based on a clean reference image. Specifically, we focus on SEM semiconductor defects in addition to several natural image anomalies. There are well-known methods to create a simulation of an artificial reference image by its defect specimen. In this work, we introduce several applications for this capability, that the simulated reference is beneficial for improving their results. Among these defect detection methods are classic computer vision applied on difference-image, supervised deep-learning (DL) based on human labels, and unsupervised DL which is trained on feature-level patterns of normal reference images. We show in this study how to incorporate correctly the simulated reference image for these defect and anomaly detection applications. As our experiment demonstrates, simulated reference achieves higher performance than the real reference of an image of a defect and anomaly. This advantage of simulated reference occurs mainly due to the less noise and geometric variations together with better alignment and registration to the original defect background.
Automatic defect segmentation by unsupervised anomaly learning
Feb 07, 2022
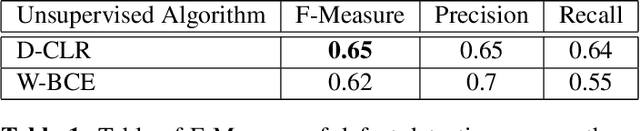
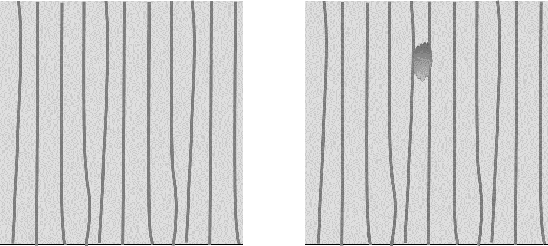
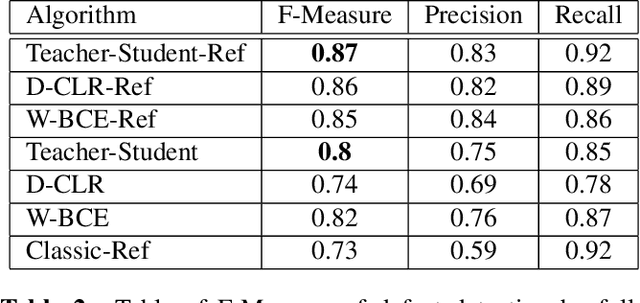
This paper addresses the problem of defect segmentation in semiconductor manufacturing. The input of our segmentation is a scanning-electron-microscopy (SEM) image of the candidate defect region. We train a U-net shape network to segment defects using a dataset of clean background images. The samples of the training phase are produced automatically such that no manual labeling is required. To enrich the dataset of clean background samples, we apply defect implant augmentation. To that end, we apply a copy-and-paste of a random image patch in the clean specimen. To improve robustness to the unlabeled data scenario, we train the features of the network with unsupervised learning methods and loss functions. Our experiments show that we succeed to segment real defects with high quality, even though our dataset contains no defect examples. Our approach performs accurately also on the problem of supervised and labeled defect segmentation.
Multispectral image fusion by super pixel statistics
Dec 21, 2021
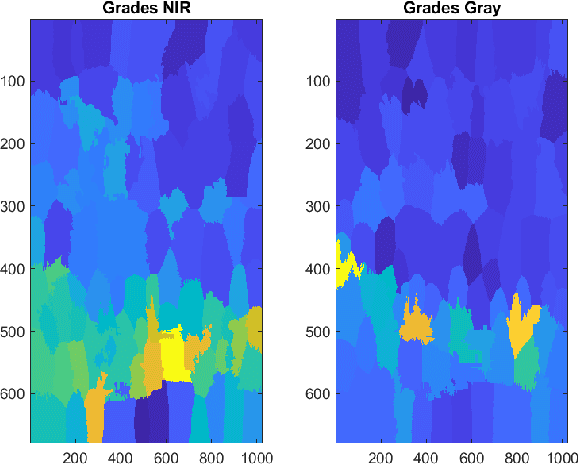

Multispectral image fusion is a fundamental problem of remote sensing and image processing. This problem is addressed by both classic and deep learning approaches. This paper is focused on the classic solutions and introduces a new novel approach to this family. The proposed method carries out multispectral image fusion based on the content of the fused images. It relies on analysis based on the level of information on segmented superpixels in the fused inputs. Specifically, I address the task of visible color RGB to Near-Infrared (NIR) fusion. The RGB image captures the color of the scene while the NIR captures details and sees beyond haze and clouds. Since each channel senses different information of the scene, their fusion is challenging and interesting. The proposed method is designed to produce a fusion that contains both advantages of each spectra. This manuscript experiments show that the proposed method is visually informative with respect to other classic fusion methods which can be run fastly on embedded devices with no need for heavy computation resources.
Classic versus deep approaches to address computer vision challenges
Jan 24, 2021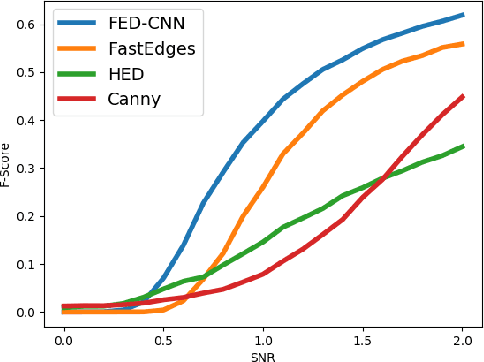

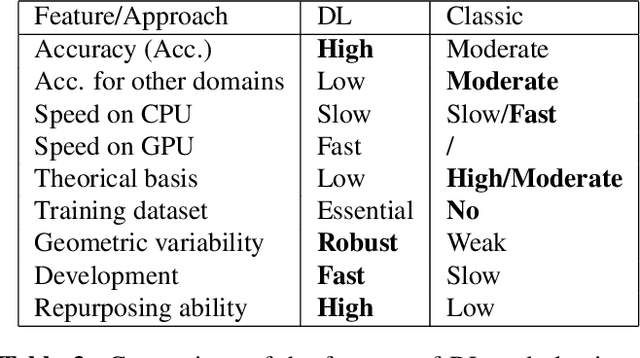
Computer vision and image processing address many challenging applications. While the last decade has seen deep neural network architectures revolutionizing those fields, early methods relied on 'classic', i.e., non-learned approaches. In this study, we explore the differences between classic and deep learning (DL) algorithms to gain new insight regarding which is more suitable for a given application. The focus is on two challenging ill-posed problems, namely faint edge detection and multispectral image registration, studying recent state-of-the-art DL and classic solutions. While those DL algorithms outperform classic methods in terms of accuracy and development time, they tend to have higher resource requirements and are unable to perform outside their training space. Moreover, classic algorithms are more transparent, which facilitates their adoption for real-life applications. As both classes of approaches have unique strengths and limitations, the choice of a solution is clearly application dependent.
Registration and Fusion of Multi-Spectral Images Using a Novel Edge Descriptor
May 28, 2018
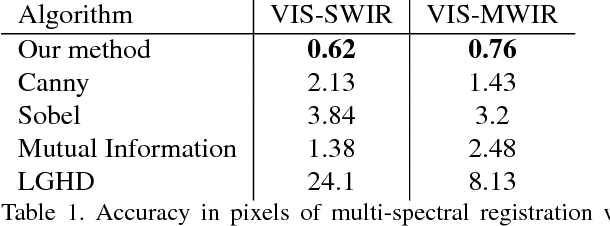
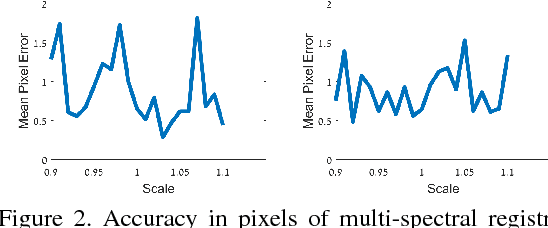

In this paper we introduce a fully end-to-end approach for multi-spectral image registration and fusion. Our method for fusion combines images from different spectral channels into a single fused image by different approaches for low and high frequency signals. A prerequisite of fusion is a stage of geometric alignment between the spectral bands, commonly referred to as registration. Unfortunately, common methods for image registration of a single spectral channel do not yield reasonable results on images from different modalities. For that end, we introduce a new algorithm for multi-spectral image registration, based on a novel edge descriptor of feature points. Our method achieves an accurate alignment of a level that allows us to further fuse the images. As our experiments show, we produce a high quality of multi-spectral image registration and fusion under many challenging scenarios.
Deep Multi-Spectral Registration Using Invariant Descriptor Learning
May 23, 2018
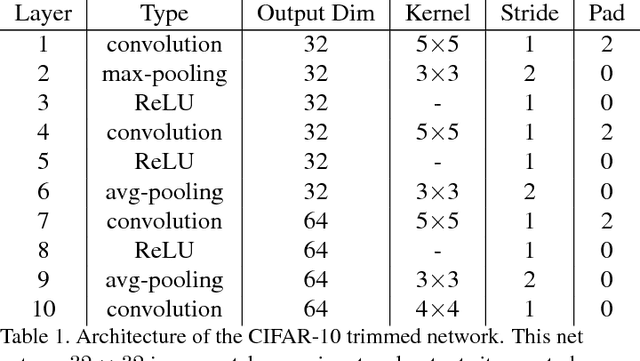
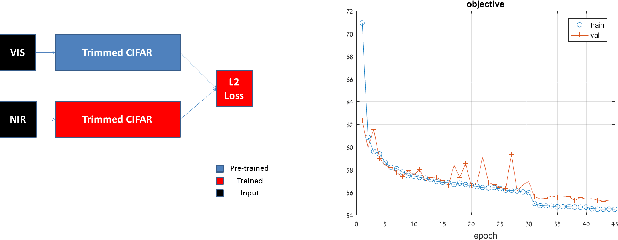

In this paper, we introduce a novel deep-learning method to align cross-spectral images. Our approach relies on a learned descriptor which is invariant to different spectra. Multi-modal images of the same scene capture different signals and therefore their registration is challenging and it is not solved by classic approaches. To that end, we developed a feature-based approach that solves the visible (VIS) to Near-Infra-Red (NIR) registration problem. Our algorithm detects corners by Harris and matches them by a patch-metric learned on top of CIFAR-10 network descriptor. As our experiments demonstrate we achieve a high-quality alignment of cross-spectral images with a sub-pixel accuracy. Comparing to other existing methods, our approach is more accurate in the task of VIS to NIR registration.
Deep Faster Detection of Faint Edges in Noisy Images
Mar 26, 2018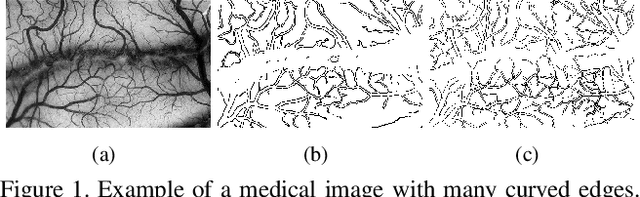
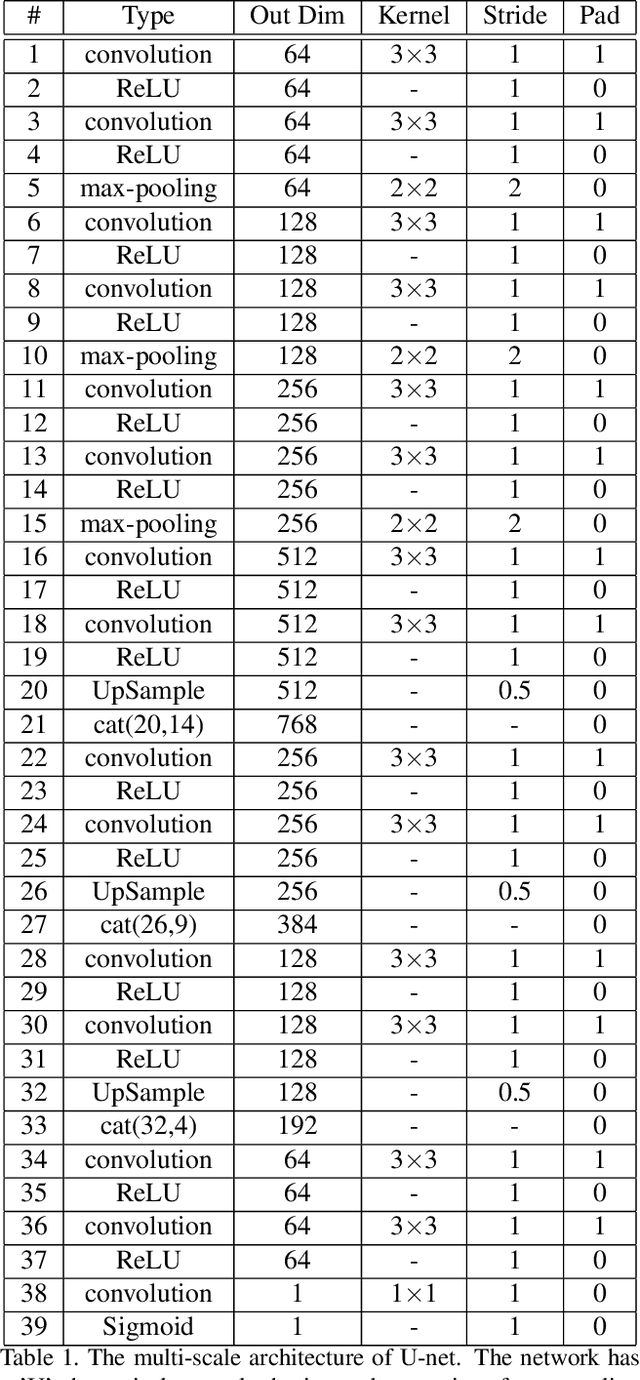

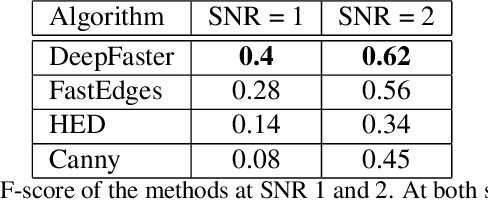
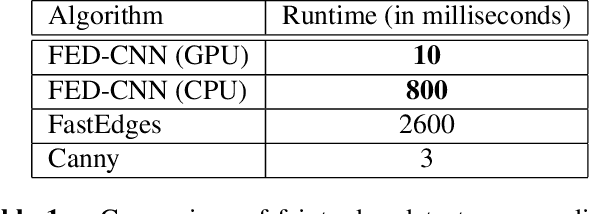
Detection of faint edges in noisy images is a challenging problem studied in the last decades. \cite{ofir2016fast} introduced a fast method to detect faint edges in the highest accuracy among all the existing approaches. Their complexity is nearly linear in the image's pixels and their runtime is seconds for a noisy image. By utilizing the U-net architecture \cite{unet}, we show in this paper that their method can be dramatically improved in both aspects of run time and accuracy. By training the network on a dataset of binary images, we develop a method for faint edge detection that works in a linear complexity. Our runtime on a noisy image is milliseconds on a GPU. Even though our method is orders of magnitude faster, we still achieve higher accuracy of detection under many challenging scenarios.
Photometric Stereo by Hemispherical Metric Embedding
Jun 25, 2017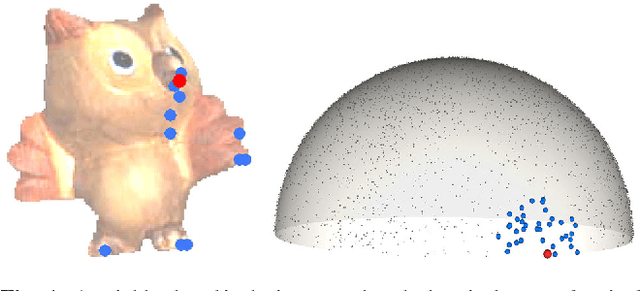
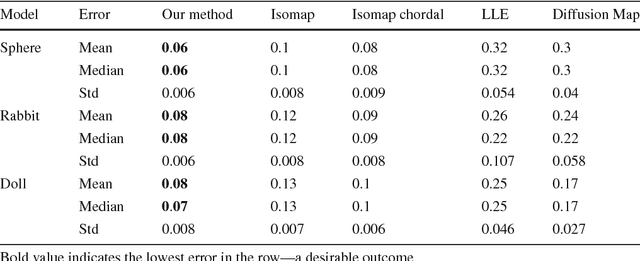
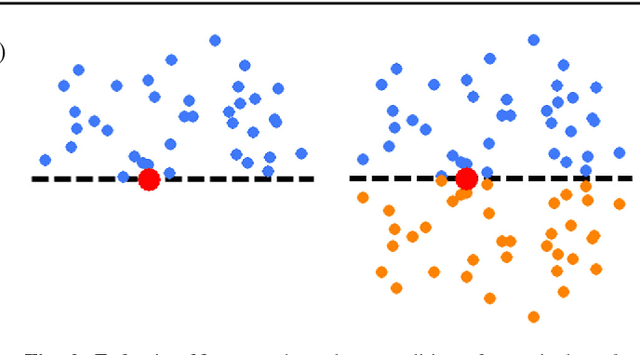
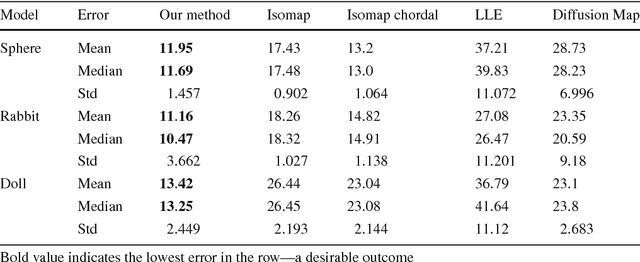
Photometric Stereo methods seek to reconstruct the 3d shape of an object from motionless images obtained with varying illumination. Most existing methods solve a restricted problem where the physical reflectance model, such as Lambertian reflectance, is known in advance. In contrast, we do not restrict ourselves to a specific reflectance model. Instead, we offer a method that works on a wide variety of reflectances. Our approach uses a simple yet uncommonly used property of the problem - the sought after normals are points on a unit hemisphere. We present a novel embedding method that maps pixels to normals on the unit hemisphere. Our experiments demonstrate that this approach outperforms existing manifold learning methods for the task of hemisphere embedding. We further show successful reconstructions of objects from a wide variety of reflectances including smooth, rough, diffuse and specular surfaces, even in the presence of significant attached shadows. Finally, we empirically prove that under these challenging settings we obtain more accurate shape reconstructions than existing methods.
On Detection of Faint Edges in Noisy Images
Jun 22, 2017
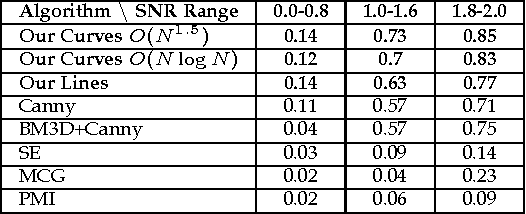
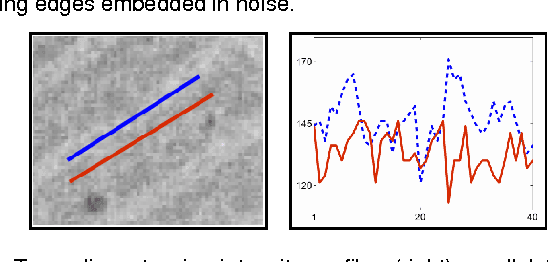
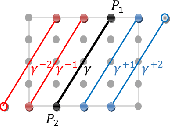
A fundamental question for edge detection in noisy images is how faint can an edge be and still be detected. In this paper we offer a formalism to study this question and subsequently introduce computationally efficient multiscale edge detection algorithms designed to detect faint edges in noisy images. In our formalism we view edge detection as a search in a discrete, though potentially large, set of feasible curves. First, we derive approximate expressions for the detection threshold as a function of curve length and the complexity of the search space. We then present two edge detection algorithms, one for straight edges, and the second for curved ones. Both algorithms efficiently search for edges in a large set of candidates by hierarchically constructing difference filters that match the curves traced by the sought edges. We demonstrate the utility of our algorithms in both simulations and applications involving challenging real images. Finally, based on these principles, we develop an algorithm for fiber detection and enhancement. We exemplify its utility to reveal and enhance nerve axons in light microscopy images.