 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Object Detection in Autonomous Vehicles Based on Synthetic Virtual Environment Analysis
Dec 10, 2024



Autonomous Vehicles (AVs) use natural images and videos as input to understand the real world by overlaying and inferring digital elements, facilitating proactive detection in an effort to assure safety. A crucial aspect of this process is real-time, accurate object recognition through automatic scene analysis. While traditional methods primarily concentrate on 2D object detection, exploring 3D object detection, which involves projecting 3D bounding boxes into the three-dimensional environment, holds significance and can be notably enhanced using the AR ecosystem. This study examines an AI model's ability to deduce 3D bounding boxes in the context of real-time scene analysis while producing and evaluating the model's performance and processing time, in the virtual domain, which is then applied to AVs. This work also employs a synthetic dataset that includes artificially generated images mimicking various environmental, lighting, and spatiotemporal states. This evaluation is oriented in handling images featuring objects in diverse weather conditions, captured with varying camera settings. These variations pose more challenging detection and recognition scenarios, which the outcomes of this work can help achieve competitive results under most of the tested conditions.
A Closer Look at Data Augmentation Strategies for Finetuning-Based Low/Few-Shot Object Detection
Aug 20, 2024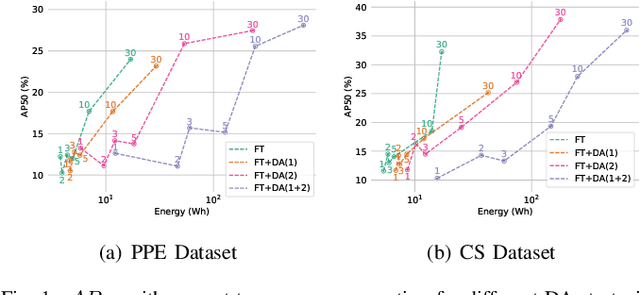
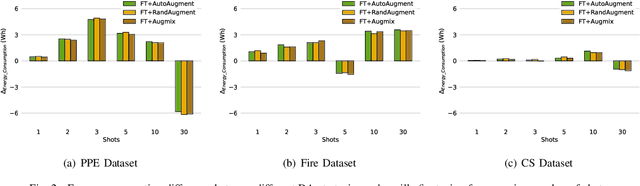
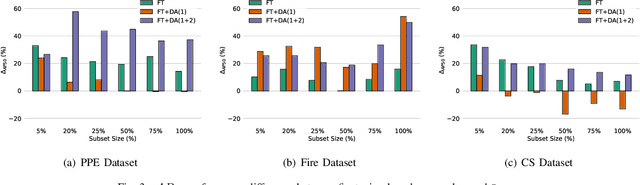

Current methods for low- and few-shot object detection have primarily focused on enhancing model performance for detecting objects. One common approach to achieve this is by combining model finetuning with data augmentation strategies. However, little attention has been given to the energy efficiency of these approaches in data-scarce regimes. This paper seeks to conduct a comprehensive empirical study that examines both model performance and energy efficiency of custom data augmentations and automated data augmentation selection strategies when combined with a lightweight object detector. The methods are evaluated in three different benchmark datasets in terms of their performance and energy consumption, and the Efficiency Factor is employed to gain insights into their effectiveness considering both performance and efficiency. Consequently, it is shown that in many cases, the performance gains of data augmentation strategies are overshadowed by their increased energy usage, necessitating the development of more energy efficient data augmentation strategies to address data scarcity.
Evaluating the Energy Efficiency of Few-Shot Learning for Object Detection in Industrial Settings
Mar 11, 2024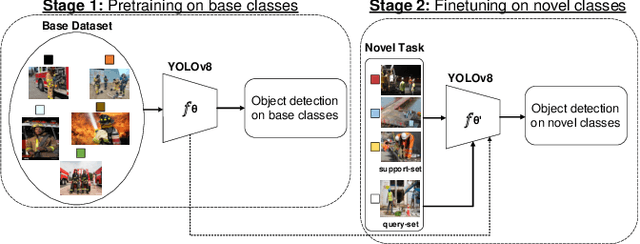

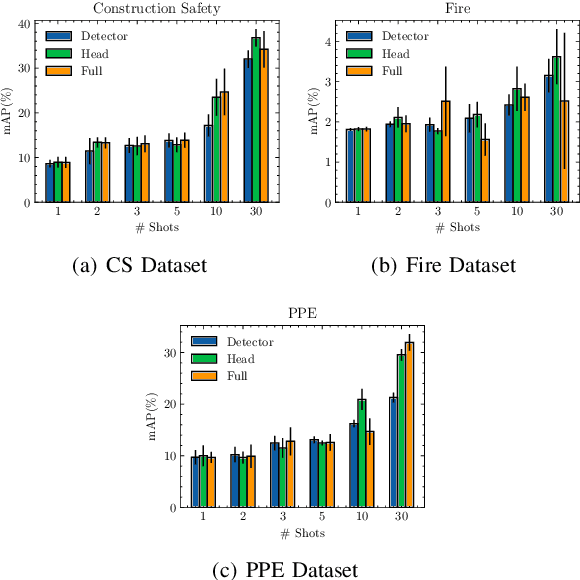

In the ever-evolving era of Artificial Intelligence (AI), model performance has constituted a key metric driving innovation, leading to an exponential growth in model size and complexity. However, sustainability and energy efficiency have been critical requirements during deployment in contemporary industrial settings, necessitating the use of data-efficient approaches such as few-shot learning. In this paper, to alleviate the burden of lengthy model training and minimize energy consumption, a finetuning approach to adapt standard object detection models to downstream tasks is examined. Subsequently, a thorough case study and evaluation of the energy demands of the developed models, applied in object detection benchmark datasets from volatile industrial environments is presented. Specifically, different finetuning strategies as well as utilization of ancillary evaluation data during training are examined, and the trade-off between performance and efficiency is highlighted in this low-data regime. Finally, this paper introduces a novel way to quantify this trade-off through a customized Efficiency Factor metric.
Toward Green and Human-Like Artificial Intelligence: A Complete Survey on Contemporary Few-Shot Learning Approaches
Feb 05, 2024



Despite deep learning's widespread success, its data-hungry and computationally expensive nature makes it impractical for many data-constrained real-world applications. Few-Shot Learning (FSL) aims to address these limitations by enabling rapid adaptation to novel learning tasks, seeing significant growth in recent years. This survey provides a comprehensive overview of the field's latest advancements. Initially, FSL is formally defined, and its relationship with different learning fields is presented. A novel taxonomy is introduced, extending previously proposed ones, and real-world applications in classic and novel fields are described. Finally, recent trends shaping the field, outstanding challenges, and promising future research directions are discussed.
Evaluation of Environmental Conditions on Object Detection using Oriented Bounding Boxes for AR Applications
Jun 29, 2023

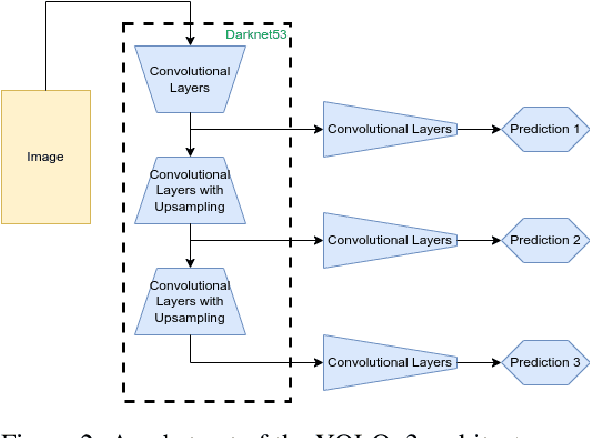

The objective of augmented reality (AR) is to add digital content to natural images and videos to create an interactive experience between the user and the environment. Scene analysis and object recognition play a crucial role in AR, as they must be performed quickly and accurately. In this study, a new approach is proposed that involves using oriented bounding boxes with a detection and recognition deep network to improve performance and processing time. The approach is evaluated using two datasets: a real image dataset (DOTA dataset) commonly used for computer vision tasks, and a synthetic dataset that simulates different environmental, lighting, and acquisition conditions. The focus of the evaluation is on small objects, which are difficult to detect and recognise. The results indicate that the proposed approach tends to produce better Average Precision and greater accuracy for small objects in most of the tested conditions.