 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllicit object detection in X-ray imaging using deep learning techniques: A comparative evaluation
Jul 23, 2025Automated X-ray inspection is crucial for efficient and unobtrusive security screening in various public settings. However, challenges such as object occlusion, variations in the physical properties of items, diversity in X-ray scanning devices, and limited training data hinder accurate and reliable detection of illicit items. Despite the large body of research in the field, reported experimental evaluations are often incomplete, with frequently conflicting outcomes. To shed light on the research landscape and facilitate further research, a systematic, detailed, and thorough comparative evaluation of recent Deep Learning (DL)-based methods for X-ray object detection is conducted. For this, a comprehensive evaluation framework is developed, composed of: a) Six recent, large-scale, and widely used public datasets for X-ray illicit item detection (OPIXray, CLCXray, SIXray, EDS, HiXray, and PIDray), b) Ten different state-of-the-art object detection schemes covering all main categories in the literature, including generic Convolutional Neural Network (CNN), custom CNN, generic transformer, and hybrid CNN-transformer architectures, and c) Various detection (mAP50 and mAP50:95) and time/computational-complexity (inference time (ms), parameter size (M), and computational load (GFLOPS)) metrics. A thorough analysis of the results leads to critical observations and insights, emphasizing key aspects such as: a) Overall behavior of the object detection schemes, b) Object-level detection performance, c) Dataset-specific observations, and d) Time efficiency and computational complexity analysis. To support reproducibility of the reported experimental results, the evaluation code and model weights are made publicly available at https://github.com/jgenc/xray-comparative-evaluation.
X-ray illicit object detection using hybrid CNN-transformer neural network architectures
May 01, 2025In the field of X-ray security applications, even the smallest details can significantly impact outcomes. Objects that are heavily occluded or intentionally concealed pose a great challenge for detection, whether by human observation or through advanced technological applications. While certain Deep Learning (DL) architectures demonstrate strong performance in processing local information, such as Convolutional Neural Networks (CNNs), others excel in handling distant information, e.g., transformers. In X-ray security imaging the literature has been dominated by the use of CNN-based methods, while the integration of the two aforementioned leading architectures has not been sufficiently explored. In this paper, various hybrid CNN-transformer architectures are evaluated against a common CNN object detection baseline, namely YOLOv8. In particular, a CNN (HGNetV2) and a hybrid CNN-transformer (Next-ViT-S) backbone are combined with different CNN/transformer detection heads (YOLOv8 and RT-DETR). The resulting architectures are comparatively evaluated on three challenging public X-ray inspection datasets, namely EDS, HiXray, and PIDray. Interestingly, while the YOLOv8 detector with its default backbone (CSP-DarkNet53) is generally shown to be advantageous on the HiXray and PIDray datasets, when a domain distribution shift is incorporated in the X-ray images (as happens in the EDS datasets), hybrid CNN-transformer architectures exhibit increased robustness. Detailed comparative evaluation results, including object-level detection performance and object-size error analysis, demonstrate the strengths and weaknesses of each architectural combination and suggest guidelines for future research. The source code and network weights of the models employed in this study are available at https://github.com/jgenc/xray-comparative-evaluation.
Malware Detection in Docker Containers: An Image is Worth a Thousand Logs
Apr 04, 2025



Malware detection is increasingly challenged by evolving techniques like obfuscation and polymorphism, limiting the effectiveness of traditional methods. Meanwhile, the widespread adoption of software containers has introduced new security challenges, including the growing threat of malicious software injection, where a container, once compromised, can serve as entry point for further cyberattacks. In this work, we address these security issues by introducing a method to identify compromised containers through machine learning analysis of their file systems. We cast the entire software containers into large RGB images via their tarball representations, and propose to use established Convolutional Neural Network architectures on a streaming, patch-based manner. To support our experiments, we release the COSOCO dataset--the first of its kind--containing 3364 large-scale RGB images of benign and compromised software containers at https://huggingface.co/datasets/k3ylabs/cosoco-image-dataset. Our method detects more malware and achieves higher F1 and Recall scores than all individual and ensembles of VirusTotal engines, demonstrating its effectiveness and setting a new standard for identifying malware-compromised software containers.
Public space security management using digital twin technologies
Mar 10, 2025As the security of public spaces remains a critical issue in today's world, Digital Twin technologies have emerged in recent years as a promising solution for detecting and predicting potential future threats. The applied methodology leverages a Digital Twin of a metro station in Athens, Greece, using the FlexSim simulation software. The model encompasses points of interest and passenger flows, and sets their corresponding parameters. These elements influence and allow the model to provide reasonable predictions on the security management of the station under various scenarios. Experimental tests are conducted with different configurations of surveillance cameras and optimizations of camera angles to evaluate the effectiveness of the space surveillance setup. The results show that the strategic positioning of surveillance cameras and the adjustment of their angles significantly improves the detection of suspicious behaviors and with the use of the DT it is possible to evaluate different scenarios and find the optimal camera setup for each case. In summary, this study highlights the value of Digital Twins in real-time simulation and data-driven security management. The proposed approach contributes to the ongoing development of smart security solutions for public spaces and provides an innovative framework for threat detection and prevention.
State of play and future directions in industrial computer vision AI standards
Mar 04, 2025The recent tremendous advancements in the areas of Artificial Intelligence (AI) and Deep Learning (DL) have also resulted into corresponding remarkable progress in the field of Computer Vision (CV), showcasing robust technological solutions in a wide range of application sectors of high industrial interest (e.g., healthcare, autonomous driving, automation, etc.). Despite the outstanding performance of CV systems in specific domains, their development and exploitation at industrial-scale necessitates, among other, the addressing of requirements related to the reliability, transparency, trustworthiness, security, safety, and robustness of the developed AI models. The latter raises the imperative need for the development of efficient, comprehensive and widely-adopted industrial standards. In this context, this study investigates the current state of play regarding the development of industrial computer vision AI standards, emphasizing on critical aspects, like model interpretability, data quality, and regulatory compliance. In particular, a systematic analysis of launched and currently developing CV standards, proposed by the main international standardization bodies (e.g. ISO/IEC, IEEE, DIN, etc.) is performed. The latter is complemented by a comprehensive discussion on the current challenges and future directions observed in this regularization endeavor.
Leveraging Digital Twin Technologies for Public Space Protection and Vulnerability Assessment
Aug 30, 2024



Over the recent years, the protection of the so-called `soft-targets', i.e. locations easily accessible by the general public with relatively low, though, security measures, has emerged as a rather challenging and increasingly important issue. The complexity and seriousness of this security threat growths nowadays exponentially, due to the emergence of new advanced technologies (e.g. Artificial Intelligence (AI), Autonomous Vehicles (AVs), 3D printing, etc.); especially when it comes to large-scale, popular and diverse public spaces. In this paper, a novel Digital Twin-as-a-Security-Service (DTaaSS) architecture is introduced for holistically and significantly enhancing the protection of public spaces (e.g. metro stations, leisure sites, urban squares, etc.). The proposed framework combines a Digital Twin (DT) conceptualization with additional cutting-edge technologies, including Internet of Things (IoT), cloud computing, Big Data analytics and AI. In particular, DTaaSS comprises a holistic, real-time, large-scale, comprehensive and data-driven security solution for the efficient/robust protection of public spaces, supporting: a) data collection and analytics, b) area monitoring/control and proactive threat detection, c) incident/attack prediction, and d) quantitative and data-driven vulnerability assessment. Overall, the designed architecture exhibits increased potential in handling complex, hybrid and combined threats over large, critical and popular soft-targets. The applicability and robustness of DTaaSS is discussed in detail against representative and diverse real-world application scenarios, including complex attacks to: a) a metro station, b) a leisure site, and c) a cathedral square.
Advances in Diffusion Models for Image Data Augmentation: A Review of Methods, Models, Evaluation Metrics and Future Research Directions
Jul 04, 2024Image data augmentation constitutes a critical methodology in modern computer vision tasks, since it can facilitate towards enhancing the diversity and quality of training datasets; thereby, improving the performance and robustness of machine learning models in downstream tasks. In parallel, augmentation approaches can also be used for editing/modifying a given image in a context- and semantics-aware way. Diffusion Models (DMs), which comprise one of the most recent and highly promising classes of methods in the field of generative Artificial Intelligence (AI), have emerged as a powerful tool for image data augmentation, capable of generating realistic and diverse images by learning the underlying data distribution. The current study realizes a systematic, comprehensive and in-depth review of DM-based approaches for image augmentation, covering a wide range of strategies, tasks and applications. In particular, a comprehensive analysis of the fundamental principles, model architectures and training strategies of DMs is initially performed. Subsequently, a taxonomy of the relevant image augmentation methods is introduced, focusing on techniques regarding semantic manipulation, personalization and adaptation, and application-specific augmentation tasks. Then, performance assessment methodologies and respective evaluation metrics are analyzed. Finally, current challenges and future research directions in the field are discussed.
StatAvg: Mitigating Data Heterogeneity in Federated Learning for Intrusion Detection Systems
May 20, 2024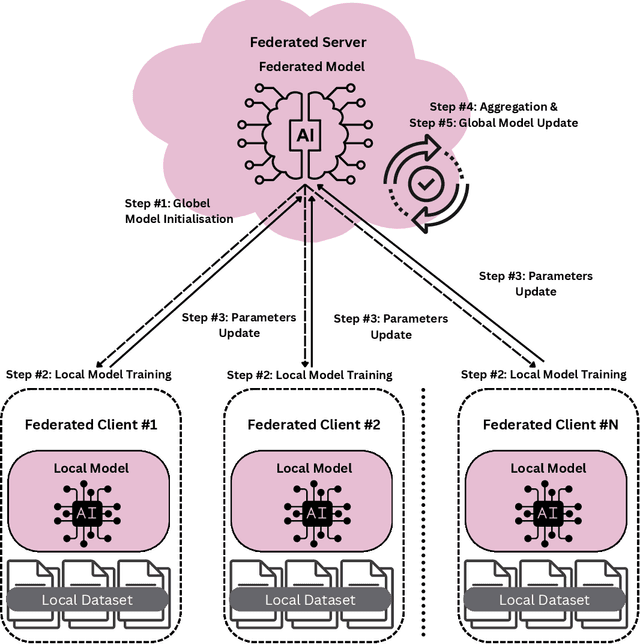
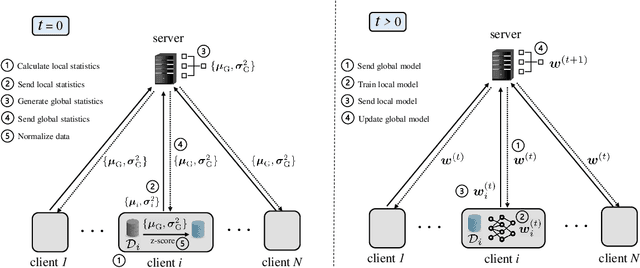
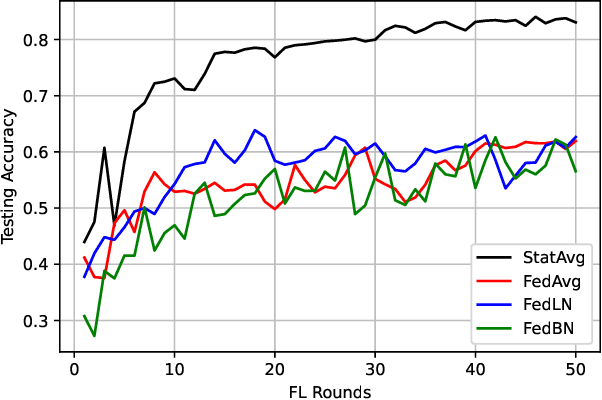
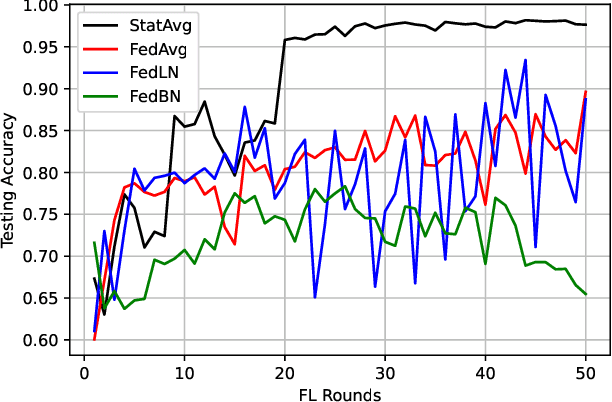
Federated learning (FL) is a decentralized learning technique that enables participating devices to collaboratively build a shared Machine Leaning (ML) or Deep Learning (DL) model without revealing their raw data to a third party. Due to its privacy-preserving nature, FL has sparked widespread attention for building Intrusion Detection Systems (IDS) within the realm of cybersecurity. However, the data heterogeneity across participating domains and entities presents significant challenges for the reliable implementation of an FL-based IDS. In this paper, we propose an effective method called Statistical Averaging (StatAvg) to alleviate non-independently and identically (non-iid) distributed features across local clients' data in FL. In particular, StatAvg allows the FL clients to share their individual data statistics with the server, which then aggregates this information to produce global statistics. The latter are shared with the clients and used for universal data normalisation. It is worth mentioning that StatAvg can seamlessly integrate with any FL aggregation strategy, as it occurs before the actual FL training process. The proposed method is evaluated against baseline approaches using datasets for network and host Artificial Intelligence (AI)-powered IDS. The experimental results demonstrate the efficiency of StatAvg in mitigating non-iid feature distributions across the FL clients compared to the baseline methods.
Evaluating the Energy Efficiency of Few-Shot Learning for Object Detection in Industrial Settings
Mar 11, 2024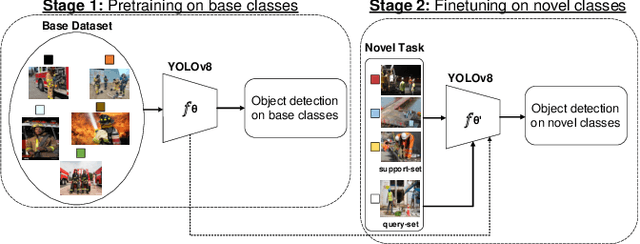

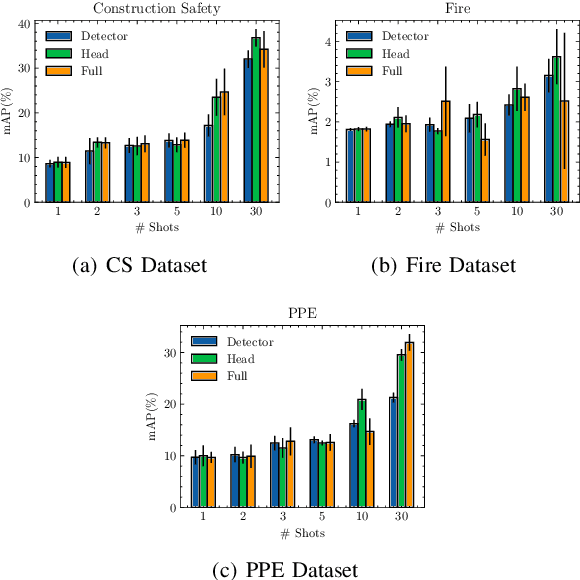

In the ever-evolving era of Artificial Intelligence (AI), model performance has constituted a key metric driving innovation, leading to an exponential growth in model size and complexity. However, sustainability and energy efficiency have been critical requirements during deployment in contemporary industrial settings, necessitating the use of data-efficient approaches such as few-shot learning. In this paper, to alleviate the burden of lengthy model training and minimize energy consumption, a finetuning approach to adapt standard object detection models to downstream tasks is examined. Subsequently, a thorough case study and evaluation of the energy demands of the developed models, applied in object detection benchmark datasets from volatile industrial environments is presented. Specifically, different finetuning strategies as well as utilization of ancillary evaluation data during training are examined, and the trade-off between performance and efficiency is highlighted in this low-data regime. Finally, this paper introduces a novel way to quantify this trade-off through a customized Efficiency Factor metric.
Multimodal Explainable Artificial Intelligence: A Comprehensive Review of Methodological Advances and Future Research Directions
Jun 09, 2023



The current study focuses on systematically analyzing the recent advances in the field of Multimodal eXplainable Artificial Intelligence (MXAI). In particular, the relevant primary prediction tasks and publicly available datasets are initially described. Subsequently, a structured presentation of the MXAI methods of the literature is provided, taking into account the following criteria: a) The number of the involved modalities, b) The stage at which explanations are produced, and c) The type of the adopted methodology (i.e. mathematical formalism). Then, the metrics used for MXAI evaluation are discussed. Finally, a comprehensive analysis of current challenges and future research directions is provided.