 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Data Augmentation Strategies for Finetuning-Based Low/Few-Shot Object Detection
Aug 20, 2024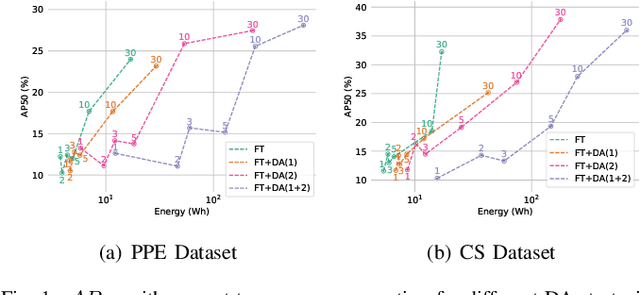
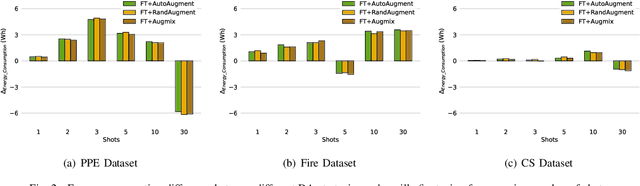
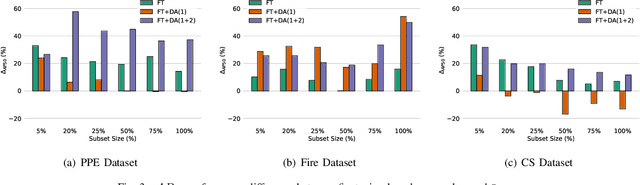

Current methods for low- and few-shot object detection have primarily focused on enhancing model performance for detecting objects. One common approach to achieve this is by combining model finetuning with data augmentation strategies. However, little attention has been given to the energy efficiency of these approaches in data-scarce regimes. This paper seeks to conduct a comprehensive empirical study that examines both model performance and energy efficiency of custom data augmentations and automated data augmentation selection strategies when combined with a lightweight object detector. The methods are evaluated in three different benchmark datasets in terms of their performance and energy consumption, and the Efficiency Factor is employed to gain insights into their effectiveness considering both performance and efficiency. Consequently, it is shown that in many cases, the performance gains of data augmentation strategies are overshadowed by their increased energy usage, necessitating the development of more energy efficient data augmentation strategies to address data scarcity.
Few-Shot Load Forecasting Under Data Scarcity in Smart Grids: A Meta-Learning Approach
Jun 09, 2024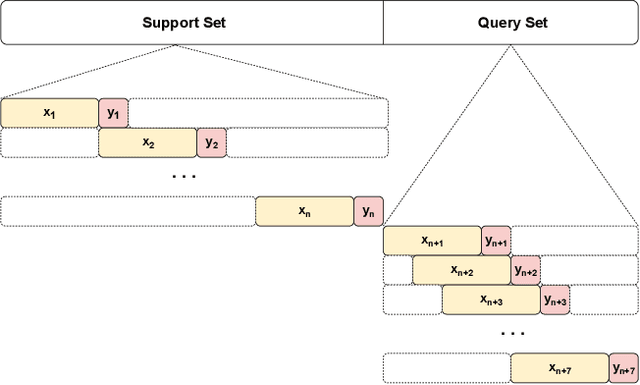
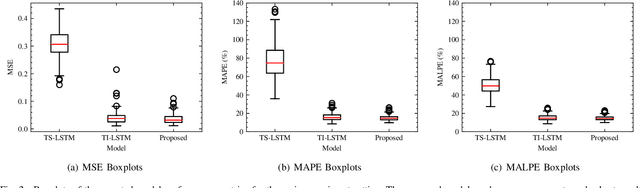
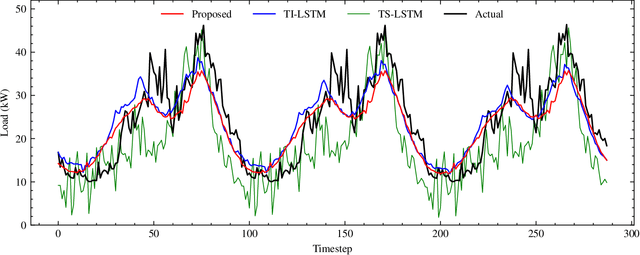
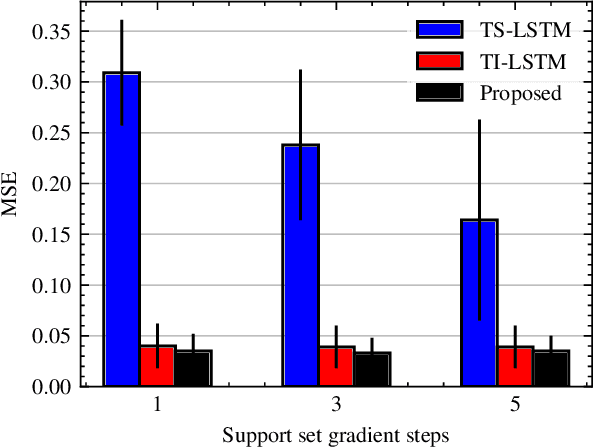
Despite the rapid expansion of smart grids and large volumes of data at the individual consumer level, there are still various cases where adequate data collection to train accurate load forecasting models is challenging or even impossible. This paper proposes adapting an established model-agnostic meta-learning algorithm for short-term load forecasting in the context of few-shot learning. Specifically, the proposed method can rapidly adapt and generalize within any unknown load time series of arbitrary length using only minimal training samples. In this context, the meta-learning model learns an optimal set of initial parameters for a base-level learner recurrent neural network. The proposed model is evaluated using a dataset of historical load consumption data from real-world consumers. Despite the examined load series' short length, it produces accurate forecasts outperforming transfer learning and task-specific machine learning methods by $12.5\%$. To enhance robustness and fairness during model evaluation, a novel metric, mean average log percentage error, is proposed that alleviates the bias introduced by the commonly used MAPE metric. Finally, a series of studies to evaluate the model's robustness under different hyperparameters and time series lengths is also conducted, demonstrating that the proposed approach consistently outperforms all other models.
Enhancing Performance for Highly Imbalanced Medical Data via Data Regularization in a Federated Learning Setting
May 30, 2024The increased availability of medical data has significantly impacted healthcare by enabling the application of machine / deep learning approaches in various instances. However, medical datasets are usually small and scattered across multiple providers, suffer from high class-imbalance, and are subject to stringent data privacy constraints. In this paper, the application of a data regularization algorithm, suitable for learning under high class-imbalance, in a federated learning setting is proposed. Specifically, the goal of the proposed method is to enhance model performance for cardiovascular disease prediction by tackling the class-imbalance that typically characterizes datasets used for this purpose, as well as by leveraging patient data available in different nodes of a federated ecosystem without compromising their privacy and enabling more resource sensitive allocation. The method is evaluated across four datasets for cardiovascular disease prediction, which are scattered across different clients, achieving improved performance. Meanwhile, its robustness under various hyperparameter settings, as well as its ability to adapt to different resource allocation scenarios, is verified.
Evaluating the Energy Efficiency of Few-Shot Learning for Object Detection in Industrial Settings
Mar 11, 2024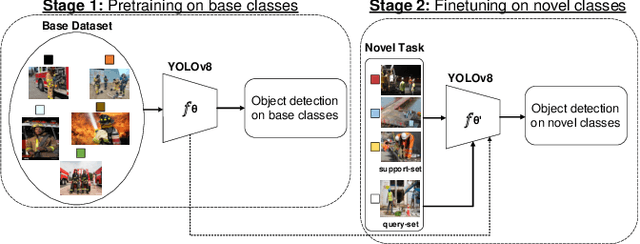

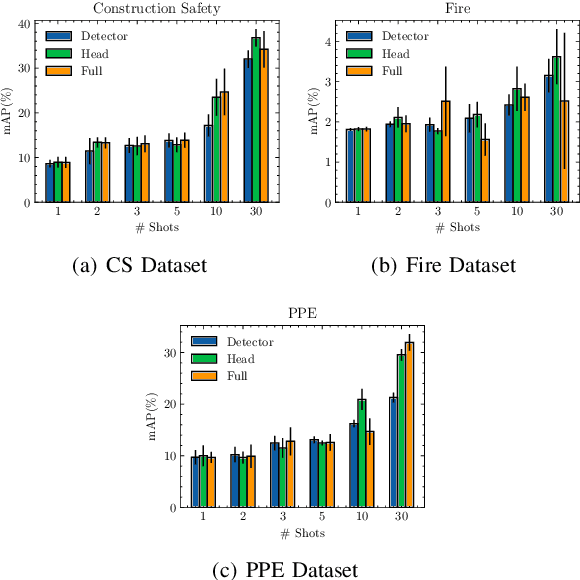

In the ever-evolving era of Artificial Intelligence (AI), model performance has constituted a key metric driving innovation, leading to an exponential growth in model size and complexity. However, sustainability and energy efficiency have been critical requirements during deployment in contemporary industrial settings, necessitating the use of data-efficient approaches such as few-shot learning. In this paper, to alleviate the burden of lengthy model training and minimize energy consumption, a finetuning approach to adapt standard object detection models to downstream tasks is examined. Subsequently, a thorough case study and evaluation of the energy demands of the developed models, applied in object detection benchmark datasets from volatile industrial environments is presented. Specifically, different finetuning strategies as well as utilization of ancillary evaluation data during training are examined, and the trade-off between performance and efficiency is highlighted in this low-data regime. Finally, this paper introduces a novel way to quantify this trade-off through a customized Efficiency Factor metric.
Toward Green and Human-Like Artificial Intelligence: A Complete Survey on Contemporary Few-Shot Learning Approaches
Feb 05, 2024



Despite deep learning's widespread success, its data-hungry and computationally expensive nature makes it impractical for many data-constrained real-world applications. Few-Shot Learning (FSL) aims to address these limitations by enabling rapid adaptation to novel learning tasks, seeing significant growth in recent years. This survey provides a comprehensive overview of the field's latest advancements. Initially, FSL is formally defined, and its relationship with different learning fields is presented. A novel taxonomy is introduced, extending previously proposed ones, and real-world applications in classic and novel fields are described. Finally, recent trends shaping the field, outstanding challenges, and promising future research directions are discussed.