 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Data Augmentation Strategies for Finetuning-Based Low/Few-Shot Object Detection
Aug 20, 2024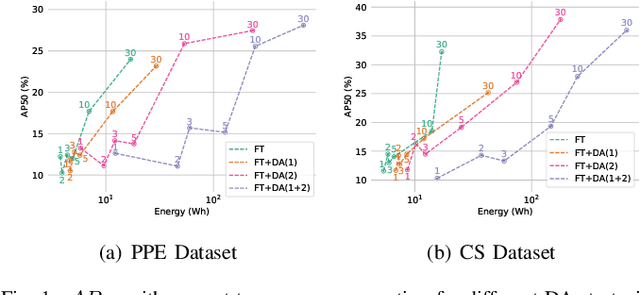
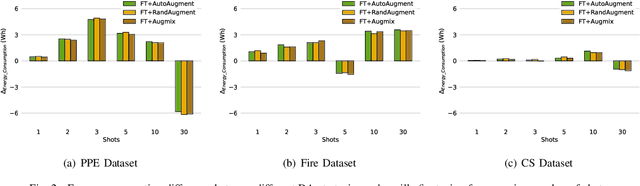
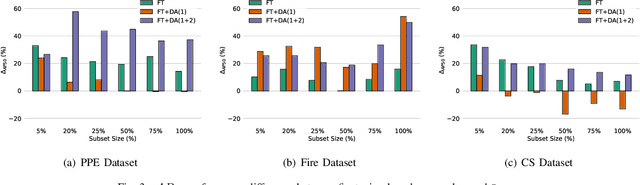

Current methods for low- and few-shot object detection have primarily focused on enhancing model performance for detecting objects. One common approach to achieve this is by combining model finetuning with data augmentation strategies. However, little attention has been given to the energy efficiency of these approaches in data-scarce regimes. This paper seeks to conduct a comprehensive empirical study that examines both model performance and energy efficiency of custom data augmentations and automated data augmentation selection strategies when combined with a lightweight object detector. The methods are evaluated in three different benchmark datasets in terms of their performance and energy consumption, and the Efficiency Factor is employed to gain insights into their effectiveness considering both performance and efficiency. Consequently, it is shown that in many cases, the performance gains of data augmentation strategies are overshadowed by their increased energy usage, necessitating the development of more energy efficient data augmentation strategies to address data scarcity.
Benchmarking Advanced Text Anonymisation Methods: A Comparative Study on Novel and Traditional Approaches
Apr 22, 2024In the realm of data privacy, the ability to effectively anonymise text is paramount. With the proliferation of deep learning and, in particular, transformer architectures, there is a burgeoning interest in leveraging these advanced models for text anonymisation tasks. This paper presents a comprehensive benchmarking study comparing the performance of transformer-based models and Large Language Models(LLM) against traditional architectures for text anonymisation. Utilising the CoNLL-2003 dataset, known for its robustness and diversity, we evaluate several models. Our results showcase the strengths and weaknesses of each approach, offering a clear perspective on the efficacy of modern versus traditional methods. Notably, while modern models exhibit advanced capabilities in capturing con textual nuances, certain traditional architectures still keep high performance. This work aims to guide researchers in selecting the most suitable model for their anonymisation needs, while also shedding light on potential paths for future advancements in the field.
Toward Green and Human-Like Artificial Intelligence: A Complete Survey on Contemporary Few-Shot Learning Approaches
Feb 05, 2024



Despite deep learning's widespread success, its data-hungry and computationally expensive nature makes it impractical for many data-constrained real-world applications. Few-Shot Learning (FSL) aims to address these limitations by enabling rapid adaptation to novel learning tasks, seeing significant growth in recent years. This survey provides a comprehensive overview of the field's latest advancements. Initially, FSL is formally defined, and its relationship with different learning fields is presented. A novel taxonomy is introduced, extending previously proposed ones, and real-world applications in classic and novel fields are described. Finally, recent trends shaping the field, outstanding challenges, and promising future research directions are discussed.