 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Object Detection in Autonomous Vehicles Based on Synthetic Virtual Environment Analysis
Dec 10, 2024



Autonomous Vehicles (AVs) use natural images and videos as input to understand the real world by overlaying and inferring digital elements, facilitating proactive detection in an effort to assure safety. A crucial aspect of this process is real-time, accurate object recognition through automatic scene analysis. While traditional methods primarily concentrate on 2D object detection, exploring 3D object detection, which involves projecting 3D bounding boxes into the three-dimensional environment, holds significance and can be notably enhanced using the AR ecosystem. This study examines an AI model's ability to deduce 3D bounding boxes in the context of real-time scene analysis while producing and evaluating the model's performance and processing time, in the virtual domain, which is then applied to AVs. This work also employs a synthetic dataset that includes artificially generated images mimicking various environmental, lighting, and spatiotemporal states. This evaluation is oriented in handling images featuring objects in diverse weather conditions, captured with varying camera settings. These variations pose more challenging detection and recognition scenarios, which the outcomes of this work can help achieve competitive results under most of the tested conditions.
Enhancing Performance for Highly Imbalanced Medical Data via Data Regularization in a Federated Learning Setting
May 30, 2024The increased availability of medical data has significantly impacted healthcare by enabling the application of machine / deep learning approaches in various instances. However, medical datasets are usually small and scattered across multiple providers, suffer from high class-imbalance, and are subject to stringent data privacy constraints. In this paper, the application of a data regularization algorithm, suitable for learning under high class-imbalance, in a federated learning setting is proposed. Specifically, the goal of the proposed method is to enhance model performance for cardiovascular disease prediction by tackling the class-imbalance that typically characterizes datasets used for this purpose, as well as by leveraging patient data available in different nodes of a federated ecosystem without compromising their privacy and enabling more resource sensitive allocation. The method is evaluated across four datasets for cardiovascular disease prediction, which are scattered across different clients, achieving improved performance. Meanwhile, its robustness under various hyperparameter settings, as well as its ability to adapt to different resource allocation scenarios, is verified.
Benchmarking Advanced Text Anonymisation Methods: A Comparative Study on Novel and Traditional Approaches
Apr 22, 2024In the realm of data privacy, the ability to effectively anonymise text is paramount. With the proliferation of deep learning and, in particular, transformer architectures, there is a burgeoning interest in leveraging these advanced models for text anonymisation tasks. This paper presents a comprehensive benchmarking study comparing the performance of transformer-based models and Large Language Models(LLM) against traditional architectures for text anonymisation. Utilising the CoNLL-2003 dataset, known for its robustness and diversity, we evaluate several models. Our results showcase the strengths and weaknesses of each approach, offering a clear perspective on the efficacy of modern versus traditional methods. Notably, while modern models exhibit advanced capabilities in capturing con textual nuances, certain traditional architectures still keep high performance. This work aims to guide researchers in selecting the most suitable model for their anonymisation needs, while also shedding light on potential paths for future advancements in the field.
Evaluating the Energy Efficiency of Few-Shot Learning for Object Detection in Industrial Settings
Mar 11, 2024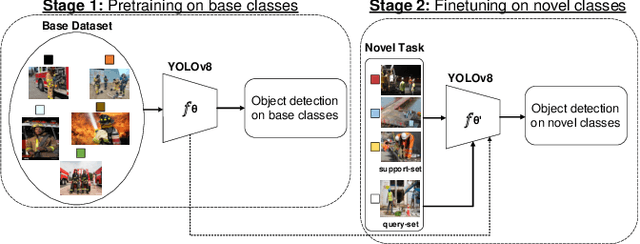

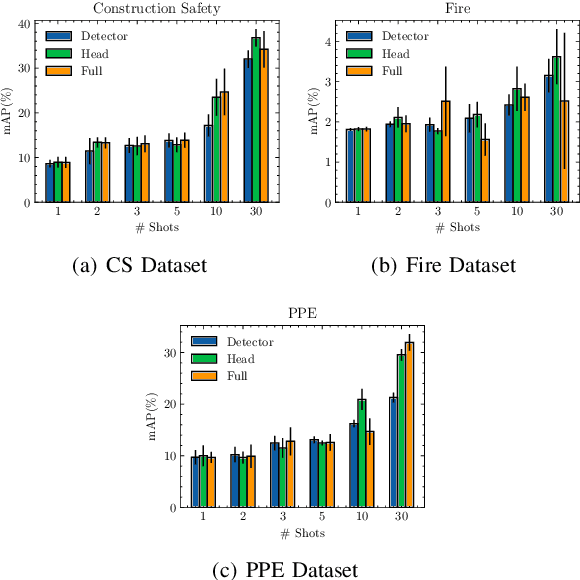

In the ever-evolving era of Artificial Intelligence (AI), model performance has constituted a key metric driving innovation, leading to an exponential growth in model size and complexity. However, sustainability and energy efficiency have been critical requirements during deployment in contemporary industrial settings, necessitating the use of data-efficient approaches such as few-shot learning. In this paper, to alleviate the burden of lengthy model training and minimize energy consumption, a finetuning approach to adapt standard object detection models to downstream tasks is examined. Subsequently, a thorough case study and evaluation of the energy demands of the developed models, applied in object detection benchmark datasets from volatile industrial environments is presented. Specifically, different finetuning strategies as well as utilization of ancillary evaluation data during training are examined, and the trade-off between performance and efficiency is highlighted in this low-data regime. Finally, this paper introduces a novel way to quantify this trade-off through a customized Efficiency Factor metric.
Toward Green and Human-Like Artificial Intelligence: A Complete Survey on Contemporary Few-Shot Learning Approaches
Feb 05, 2024



Despite deep learning's widespread success, its data-hungry and computationally expensive nature makes it impractical for many data-constrained real-world applications. Few-Shot Learning (FSL) aims to address these limitations by enabling rapid adaptation to novel learning tasks, seeing significant growth in recent years. This survey provides a comprehensive overview of the field's latest advancements. Initially, FSL is formally defined, and its relationship with different learning fields is presented. A novel taxonomy is introduced, extending previously proposed ones, and real-world applications in classic and novel fields are described. Finally, recent trends shaping the field, outstanding challenges, and promising future research directions are discussed.