 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Object Detection in Autonomous Vehicles Based on Synthetic Virtual Environment Analysis
Dec 10, 2024



Autonomous Vehicles (AVs) use natural images and videos as input to understand the real world by overlaying and inferring digital elements, facilitating proactive detection in an effort to assure safety. A crucial aspect of this process is real-time, accurate object recognition through automatic scene analysis. While traditional methods primarily concentrate on 2D object detection, exploring 3D object detection, which involves projecting 3D bounding boxes into the three-dimensional environment, holds significance and can be notably enhanced using the AR ecosystem. This study examines an AI model's ability to deduce 3D bounding boxes in the context of real-time scene analysis while producing and evaluating the model's performance and processing time, in the virtual domain, which is then applied to AVs. This work also employs a synthetic dataset that includes artificially generated images mimicking various environmental, lighting, and spatiotemporal states. This evaluation is oriented in handling images featuring objects in diverse weather conditions, captured with varying camera settings. These variations pose more challenging detection and recognition scenarios, which the outcomes of this work can help achieve competitive results under most of the tested conditions.
Applied Federated Model Personalisation in the Industrial Domain: A Comparative Study
Sep 10, 2024



The time-consuming nature of training and deploying complicated Machine and Deep Learning (DL) models for a variety of applications continues to pose significant challenges in the field of Machine Learning (ML). These challenges are particularly pronounced in the federated domain, where optimizing models for individual nodes poses significant difficulty. Many methods have been developed to tackle this problem, aiming to reduce training expenses and time while maintaining efficient optimisation. Three suggested strategies to tackle this challenge include Active Learning, Knowledge Distillation, and Local Memorization. These methods enable the adoption of smaller models that require fewer computational resources and allow for model personalization with local insights, thereby improving the effectiveness of current models. The present study delves into the fundamental principles of these three approaches and proposes an advanced Federated Learning System that utilises different Personalisation methods towards improving the accuracy of AI models and enhancing user experience in real-time NG-IoT applications, investigating the efficacy of these techniques in the local and federated domain. The results of the original and optimised models are then compared in both local and federated contexts using a comparison analysis. The post-analysis shows encouraging outcomes when it comes to optimising and personalising the models with the suggested techniques.
A Closer Look at Data Augmentation Strategies for Finetuning-Based Low/Few-Shot Object Detection
Aug 20, 2024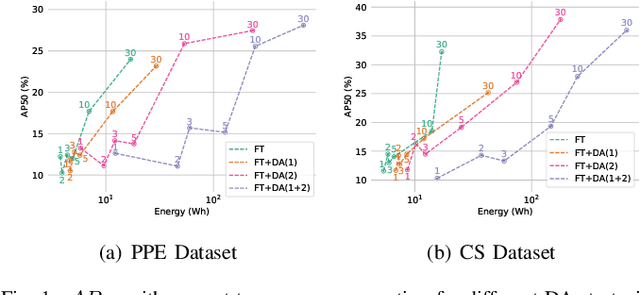
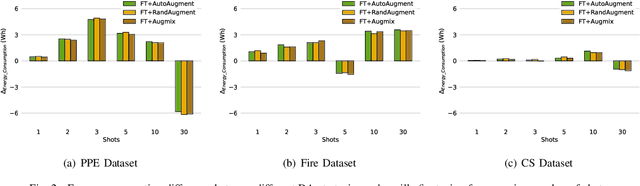
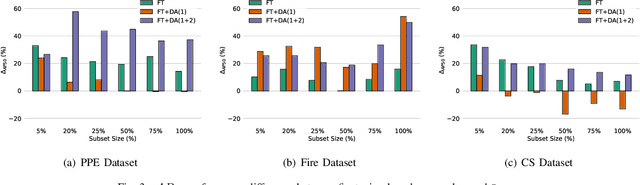

Current methods for low- and few-shot object detection have primarily focused on enhancing model performance for detecting objects. One common approach to achieve this is by combining model finetuning with data augmentation strategies. However, little attention has been given to the energy efficiency of these approaches in data-scarce regimes. This paper seeks to conduct a comprehensive empirical study that examines both model performance and energy efficiency of custom data augmentations and automated data augmentation selection strategies when combined with a lightweight object detector. The methods are evaluated in three different benchmark datasets in terms of their performance and energy consumption, and the Efficiency Factor is employed to gain insights into their effectiveness considering both performance and efficiency. Consequently, it is shown that in many cases, the performance gains of data augmentation strategies are overshadowed by their increased energy usage, necessitating the development of more energy efficient data augmentation strategies to address data scarcity.
Toward Green and Human-Like Artificial Intelligence: A Complete Survey on Contemporary Few-Shot Learning Approaches
Feb 05, 2024



Despite deep learning's widespread success, its data-hungry and computationally expensive nature makes it impractical for many data-constrained real-world applications. Few-Shot Learning (FSL) aims to address these limitations by enabling rapid adaptation to novel learning tasks, seeing significant growth in recent years. This survey provides a comprehensive overview of the field's latest advancements. Initially, FSL is formally defined, and its relationship with different learning fields is presented. A novel taxonomy is introduced, extending previously proposed ones, and real-world applications in classic and novel fields are described. Finally, recent trends shaping the field, outstanding challenges, and promising future research directions are discussed.
The evolution of argumentation mining: From models to social media and emerging tools
Jul 04, 2019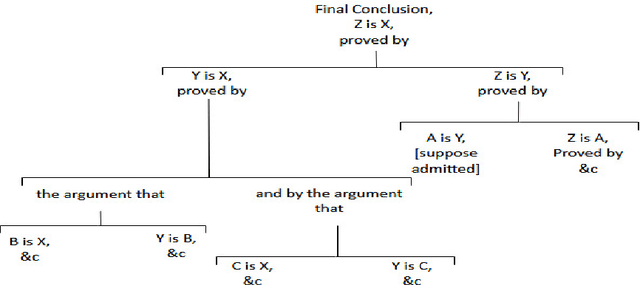
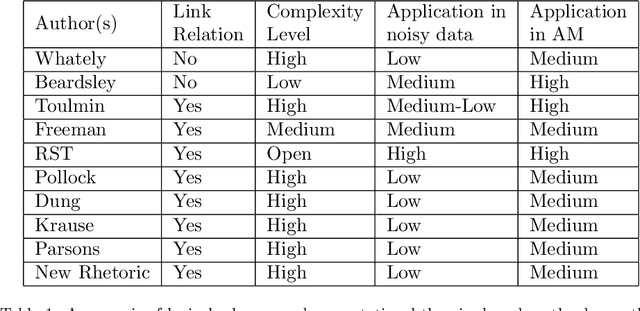
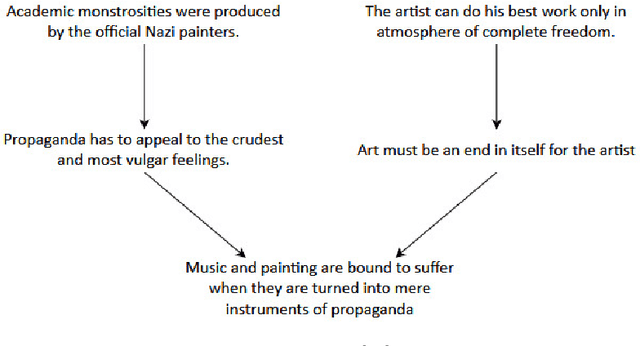
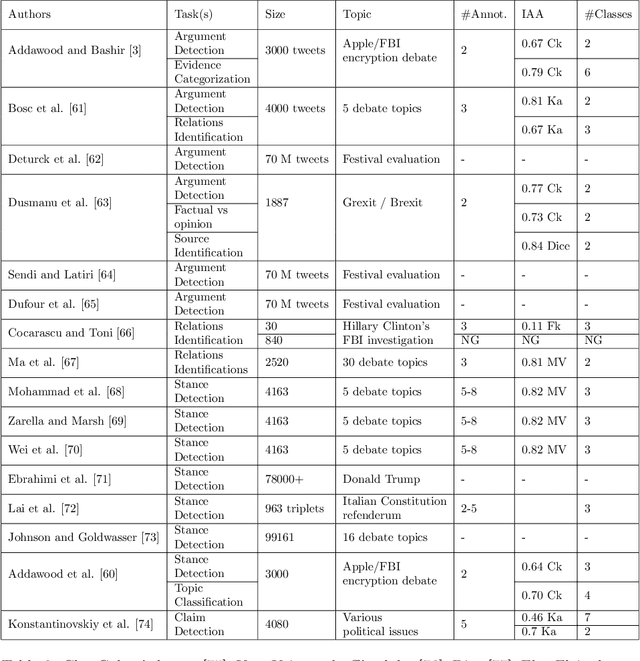
Argumentation mining is a rising subject in the computational linguistics domain focusing on extracting structured arguments from natural text, often from unstructured or noisy text. The initial approaches on modeling arguments was aiming to identify a flawless argument on specific fields (Law, Scientific Papers) serving specific needs (completeness, effectiveness). With the emerge of Web 2.0 and the explosion in the use of social media both the diffusion of the data and the argument structure have changed. In this survey article, we bridge the gap between theoretical approaches of argumentation mining and pragmatic schemes that satisfy the needs of social media generated data, recognizing the need for adapting more flexible and expandable schemes, capable to adjust to the argumentation conditions that exist in social media. We review, compare, and classify existing approaches, techniques and tools, identifying the positive outcome of combining tasks and features, and eventually propose a conceptual architecture framework. The proposed theoretical framework is an argumentation mining scheme able to identify the distinct sub-tasks and capture the needs of social media text, revealing the need for adopting more flexible and extensible frameworks.
* Journal of Information Processing & Management, Elsevier - Accepted Version