 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllicit object detection in X-ray imaging using deep learning techniques: A comparative evaluation
Jul 23, 2025Automated X-ray inspection is crucial for efficient and unobtrusive security screening in various public settings. However, challenges such as object occlusion, variations in the physical properties of items, diversity in X-ray scanning devices, and limited training data hinder accurate and reliable detection of illicit items. Despite the large body of research in the field, reported experimental evaluations are often incomplete, with frequently conflicting outcomes. To shed light on the research landscape and facilitate further research, a systematic, detailed, and thorough comparative evaluation of recent Deep Learning (DL)-based methods for X-ray object detection is conducted. For this, a comprehensive evaluation framework is developed, composed of: a) Six recent, large-scale, and widely used public datasets for X-ray illicit item detection (OPIXray, CLCXray, SIXray, EDS, HiXray, and PIDray), b) Ten different state-of-the-art object detection schemes covering all main categories in the literature, including generic Convolutional Neural Network (CNN), custom CNN, generic transformer, and hybrid CNN-transformer architectures, and c) Various detection (mAP50 and mAP50:95) and time/computational-complexity (inference time (ms), parameter size (M), and computational load (GFLOPS)) metrics. A thorough analysis of the results leads to critical observations and insights, emphasizing key aspects such as: a) Overall behavior of the object detection schemes, b) Object-level detection performance, c) Dataset-specific observations, and d) Time efficiency and computational complexity analysis. To support reproducibility of the reported experimental results, the evaluation code and model weights are made publicly available at https://github.com/jgenc/xray-comparative-evaluation.
X-ray illicit object detection using hybrid CNN-transformer neural network architectures
May 01, 2025In the field of X-ray security applications, even the smallest details can significantly impact outcomes. Objects that are heavily occluded or intentionally concealed pose a great challenge for detection, whether by human observation or through advanced technological applications. While certain Deep Learning (DL) architectures demonstrate strong performance in processing local information, such as Convolutional Neural Networks (CNNs), others excel in handling distant information, e.g., transformers. In X-ray security imaging the literature has been dominated by the use of CNN-based methods, while the integration of the two aforementioned leading architectures has not been sufficiently explored. In this paper, various hybrid CNN-transformer architectures are evaluated against a common CNN object detection baseline, namely YOLOv8. In particular, a CNN (HGNetV2) and a hybrid CNN-transformer (Next-ViT-S) backbone are combined with different CNN/transformer detection heads (YOLOv8 and RT-DETR). The resulting architectures are comparatively evaluated on three challenging public X-ray inspection datasets, namely EDS, HiXray, and PIDray. Interestingly, while the YOLOv8 detector with its default backbone (CSP-DarkNet53) is generally shown to be advantageous on the HiXray and PIDray datasets, when a domain distribution shift is incorporated in the X-ray images (as happens in the EDS datasets), hybrid CNN-transformer architectures exhibit increased robustness. Detailed comparative evaluation results, including object-level detection performance and object-size error analysis, demonstrate the strengths and weaknesses of each architectural combination and suggest guidelines for future research. The source code and network weights of the models employed in this study are available at https://github.com/jgenc/xray-comparative-evaluation.
Public space security management using digital twin technologies
Mar 10, 2025As the security of public spaces remains a critical issue in today's world, Digital Twin technologies have emerged in recent years as a promising solution for detecting and predicting potential future threats. The applied methodology leverages a Digital Twin of a metro station in Athens, Greece, using the FlexSim simulation software. The model encompasses points of interest and passenger flows, and sets their corresponding parameters. These elements influence and allow the model to provide reasonable predictions on the security management of the station under various scenarios. Experimental tests are conducted with different configurations of surveillance cameras and optimizations of camera angles to evaluate the effectiveness of the space surveillance setup. The results show that the strategic positioning of surveillance cameras and the adjustment of their angles significantly improves the detection of suspicious behaviors and with the use of the DT it is possible to evaluate different scenarios and find the optimal camera setup for each case. In summary, this study highlights the value of Digital Twins in real-time simulation and data-driven security management. The proposed approach contributes to the ongoing development of smart security solutions for public spaces and provides an innovative framework for threat detection and prevention.
State of play and future directions in industrial computer vision AI standards
Mar 04, 2025The recent tremendous advancements in the areas of Artificial Intelligence (AI) and Deep Learning (DL) have also resulted into corresponding remarkable progress in the field of Computer Vision (CV), showcasing robust technological solutions in a wide range of application sectors of high industrial interest (e.g., healthcare, autonomous driving, automation, etc.). Despite the outstanding performance of CV systems in specific domains, their development and exploitation at industrial-scale necessitates, among other, the addressing of requirements related to the reliability, transparency, trustworthiness, security, safety, and robustness of the developed AI models. The latter raises the imperative need for the development of efficient, comprehensive and widely-adopted industrial standards. In this context, this study investigates the current state of play regarding the development of industrial computer vision AI standards, emphasizing on critical aspects, like model interpretability, data quality, and regulatory compliance. In particular, a systematic analysis of launched and currently developing CV standards, proposed by the main international standardization bodies (e.g. ISO/IEC, IEEE, DIN, etc.) is performed. The latter is complemented by a comprehensive discussion on the current challenges and future directions observed in this regularization endeavor.
Survey on Hand Gesture Recognition from Visual Input
Jan 21, 2025Hand gesture recognition has become an important research area, driven by the growing demand for human-computer interaction in fields such as sign language recognition, virtual and augmented reality, and robotics. Despite the rapid growth of the field, there are few surveys that comprehensively cover recent research developments, available solutions, and benchmark datasets. This survey addresses this gap by examining the latest advancements in hand gesture and 3D hand pose recognition from various types of camera input data including RGB images, depth images, and videos from monocular or multiview cameras, examining the differing methodological requirements of each approach. Furthermore, an overview of widely used datasets is provided, detailing their main characteristics and application domains. Finally, open challenges such as achieving robust recognition in real-world environments, handling occlusions, ensuring generalization across diverse users, and addressing computational efficiency for real-time applications are highlighted to guide future research directions. By synthesizing the objectives, methodologies, and applications of recent studies, this survey offers valuable insights into current trends, challenges, and opportunities for future research in human hand gesture recognition.
Applications of Knowledge Distillation in Remote Sensing: A Survey
Sep 18, 2024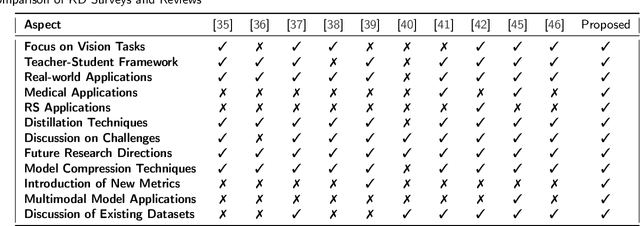
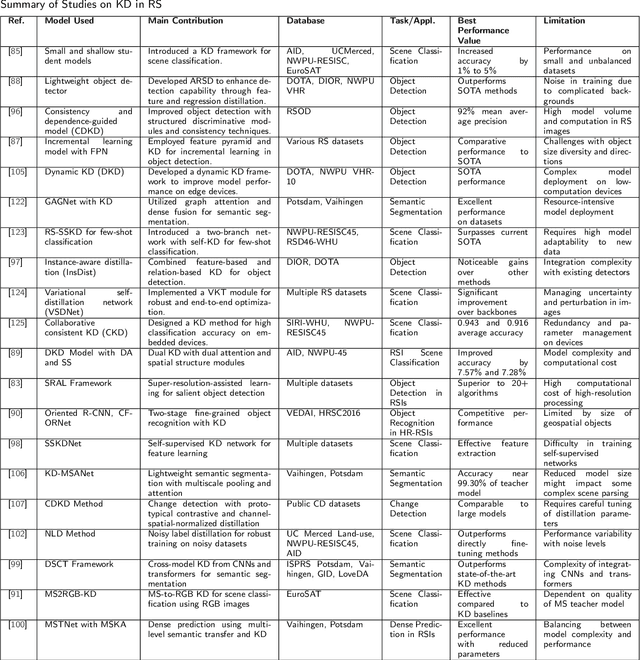
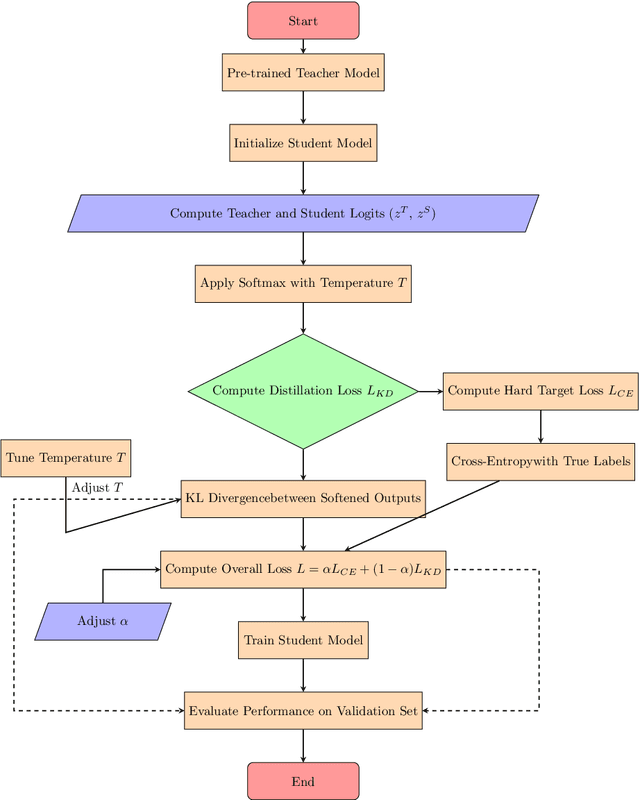
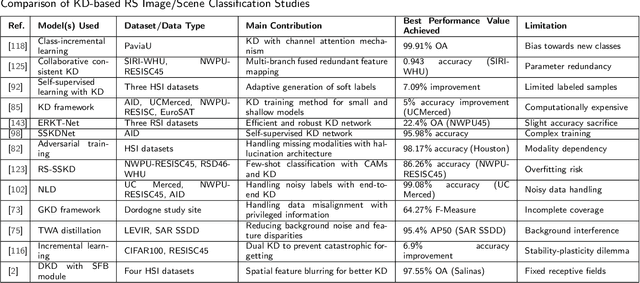
With the ever-growing complexity of models in the field of remote sensing (RS), there is an increasing demand for solutions that balance model accuracy with computational efficiency. Knowledge distillation (KD) has emerged as a powerful tool to meet this need, enabling the transfer of knowledge from large, complex models to smaller, more efficient ones without significant loss in performance. This review article provides an extensive examination of KD and its innovative applications in RS. KD, a technique developed to transfer knowledge from a complex, often cumbersome model (teacher) to a more compact and efficient model (student), has seen significant evolution and application across various domains. Initially, we introduce the fundamental concepts and historical progression of KD methods. The advantages of employing KD are highlighted, particularly in terms of model compression, enhanced computational efficiency, and improved performance, which are pivotal for practical deployments in RS scenarios. The article provides a comprehensive taxonomy of KD techniques, where each category is critically analyzed to demonstrate the breadth and depth of the alternative options, and illustrates specific case studies that showcase the practical implementation of KD methods in RS tasks, such as instance segmentation and object detection. Further, the review discusses the challenges and limitations of KD in RS, including practical constraints and prospective future directions, providing a comprehensive overview for researchers and practitioners in the field of RS. Through this organization, the paper not only elucidates the current state of research in KD but also sets the stage for future research opportunities, thereby contributing significantly to both academic research and real-world applications.
Leveraging Digital Twin Technologies for Public Space Protection and Vulnerability Assessment
Aug 30, 2024



Over the recent years, the protection of the so-called `soft-targets', i.e. locations easily accessible by the general public with relatively low, though, security measures, has emerged as a rather challenging and increasingly important issue. The complexity and seriousness of this security threat growths nowadays exponentially, due to the emergence of new advanced technologies (e.g. Artificial Intelligence (AI), Autonomous Vehicles (AVs), 3D printing, etc.); especially when it comes to large-scale, popular and diverse public spaces. In this paper, a novel Digital Twin-as-a-Security-Service (DTaaSS) architecture is introduced for holistically and significantly enhancing the protection of public spaces (e.g. metro stations, leisure sites, urban squares, etc.). The proposed framework combines a Digital Twin (DT) conceptualization with additional cutting-edge technologies, including Internet of Things (IoT), cloud computing, Big Data analytics and AI. In particular, DTaaSS comprises a holistic, real-time, large-scale, comprehensive and data-driven security solution for the efficient/robust protection of public spaces, supporting: a) data collection and analytics, b) area monitoring/control and proactive threat detection, c) incident/attack prediction, and d) quantitative and data-driven vulnerability assessment. Overall, the designed architecture exhibits increased potential in handling complex, hybrid and combined threats over large, critical and popular soft-targets. The applicability and robustness of DTaaSS is discussed in detail against representative and diverse real-world application scenarios, including complex attacks to: a) a metro station, b) a leisure site, and c) a cathedral square.
Sampling Strategies for Mitigating Bias in Face Synthesis Methods
May 18, 2024



Synthetically generated images can be used to create media content or to complement datasets for training image analysis models. Several methods have recently been proposed for the synthesis of high-fidelity face images; however, the potential biases introduced by such methods have not been sufficiently addressed. This paper examines the bias introduced by the widely popular StyleGAN2 generative model trained on the Flickr Faces HQ dataset and proposes two sampling strategies to balance the representation of selected attributes in the generated face images. We focus on two protected attributes, gender and age, and reveal that biases arise in the distribution of randomly sampled images against very young and very old age groups, as well as against female faces. These biases are also assessed for different image quality levels based on the GIQA score. To mitigate bias, we propose two alternative methods for sampling on selected lines or spheres of the latent space to increase the number of generated samples from the under-represented classes. The experimental results show a decrease in bias against underrepresented groups and a more uniform distribution of the protected features at different levels of image quality.
Exploring Machine Learning Algorithms for Infection Detection Using GC-IMS Data: A Preliminary Study
Apr 24, 2024



The developing field of enhanced diagnostic techniques in the diagnosis of infectious diseases, constitutes a crucial domain in modern healthcare. By utilizing Gas Chromatography-Ion Mobility Spectrometry (GC-IMS) data and incorporating machine learning algorithms into one platform, our research aims to tackle the ongoing issue of precise infection identification. Inspired by these difficulties, our goals consist of creating a strong data analytics process, enhancing machine learning (ML) models, and performing thorough validation for clinical applications. Our research contributes to the emerging field of advanced diagnostic technologies by integrating Gas Chromatography-Ion Mobility Spectrometry (GC-IMS) data and machine learning algorithms within a unified Laboratory Information Management System (LIMS) platform. Preliminary trials demonstrate encouraging levels of accuracy when employing various ML algorithms to differentiate between infected and non-infected samples. Continuing endeavors are currently concentrated on enhancing the effectiveness of the model, investigating techniques to clarify its functioning, and incorporating many types of data to further support the early detection of diseases.
Federated Learning for Computer Vision
Aug 24, 2023



Computer Vision (CV) is playing a significant role in transforming society by utilizing machine learning (ML) tools for a wide range of tasks. However, the need for large-scale datasets to train ML models creates challenges for centralized ML algorithms. The massive computation loads required for processing and the potential privacy risks associated with storing and processing data on central cloud servers put these algorithms under severe strain. To address these issues, federated learning (FL) has emerged as a promising solution, allowing privacy preservation by training models locally and exchanging them to improve overall performance. Additionally, the computational load is distributed across multiple clients, reducing the burden on central servers. This paper presents, to the best of the authors' knowledge, the first review discussing recent advancements of FL in CV applications, comparing them to conventional centralized training paradigms. It provides an overview of current FL applications in various CV tasks, emphasizing the advantages of FL and the challenges of implementing it in CV. To facilitate this, the paper proposes a taxonomy of FL techniques in CV, outlining their applications and security threats. It also discusses privacy concerns related to implementing blockchain in FL schemes for CV tasks and summarizes existing privacy preservation methods. Moving on, the paper identifies open research challenges and potential future research directions to further exploit the potential of FL and blockchain in CV applications.