 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Functions in Deep Learning: A Comprehensive Review
Apr 05, 2025Loss functions are at the heart of deep learning, shaping how models learn and perform across diverse tasks. They are used to quantify the difference between predicted outputs and ground truth labels, guiding the optimization process to minimize errors. Selecting the right loss function is critical, as it directly impacts model convergence, generalization, and overall performance across various applications, from computer vision to time series forecasting. This paper presents a comprehensive review of loss functions, covering fundamental metrics like Mean Squared Error and Cross-Entropy to advanced functions such as Adversarial and Diffusion losses. We explore their mathematical foundations, impact on model training, and strategic selection for various applications, including computer vision (Discriminative and generative), tabular data prediction, and time series forecasting. For each of these categories, we discuss the most used loss functions in the recent advancements of deep learning techniques. Also, this review explore the historical evolution, computational efficiency, and ongoing challenges in loss function design, underlining the need for more adaptive and robust solutions. Emphasis is placed on complex scenarios involving multi-modal data, class imbalances, and real-world constraints. Finally, we identify key future directions, advocating for loss functions that enhance interpretability, scalability, and generalization, leading to more effective and resilient deep learning models.
PDC-ViT : Source Camera Identification using Pixel Difference Convolution and Vision Transformer
Jan 27, 2025Source camera identification has emerged as a vital solution to unlock incidents involving critical cases like terrorism, violence, and other criminal activities. The ability to trace the origin of an image/video can aid law enforcement agencies in gathering evidence and constructing the timeline of events. Moreover, identifying the owner of a certain device narrows down the area of search in a criminal investigation where smartphone devices are involved. This paper proposes a new pixel-based method for source camera identification, integrating Pixel Difference Convolution (PDC) with a Vision Transformer network (ViT), and named PDC-ViT. While the PDC acts as the backbone for feature extraction by exploiting Angular PDC (APDC) and Radial PDC (RPDC). These techniques enhance the capability to capture subtle variations in pixel information, which are crucial for distinguishing between different source cameras. The second part of the methodology focuses on classification, which is based on a Vision Transformer network. Unlike traditional methods that utilize image patches directly for training the classification network, the proposed approach uniquely inputs PDC features into the Vision Transformer network. To demonstrate the effectiveness of the PDC-ViT approach, it has been assessed on five different datasets, which include various image contents and video scenes. The method has also been compared with state-of-the-art source camera identification methods. Experimental results demonstrate the effectiveness and superiority of the proposed system in terms of accuracy and robustness when compared to its competitors. For example, our proposed PDC-ViT has achieved an accuracy of 94.30%, 84%, 94.22% and 92.29% using the Vision dataset, Daxing dataset, Socrates dataset and QUFVD dataset, respectively.
Applications of Knowledge Distillation in Remote Sensing: A Survey
Sep 18, 2024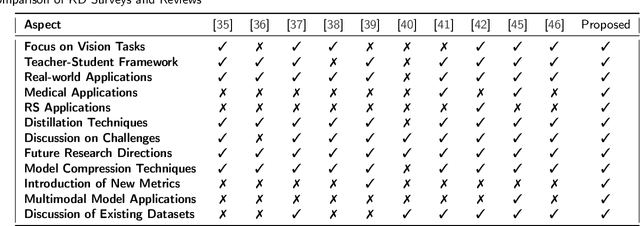
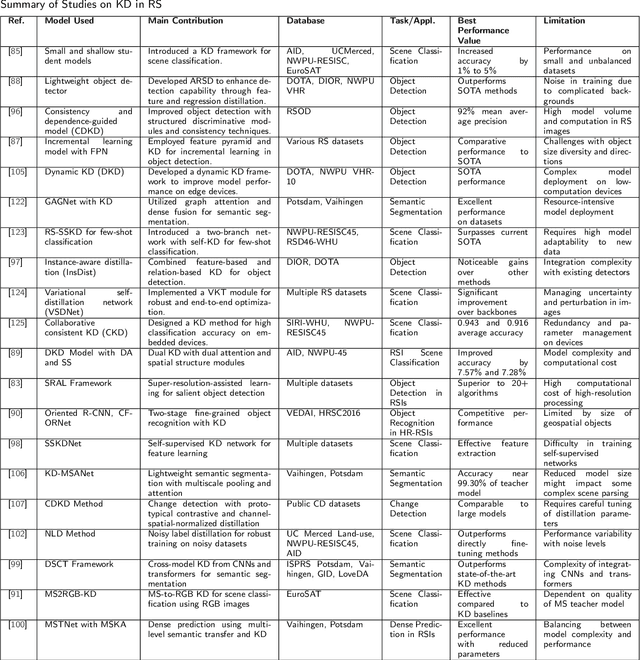
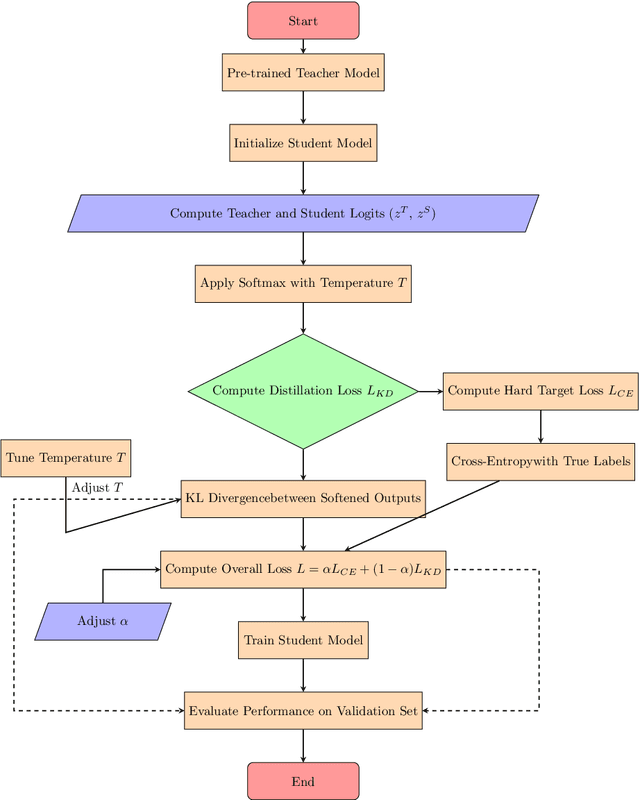
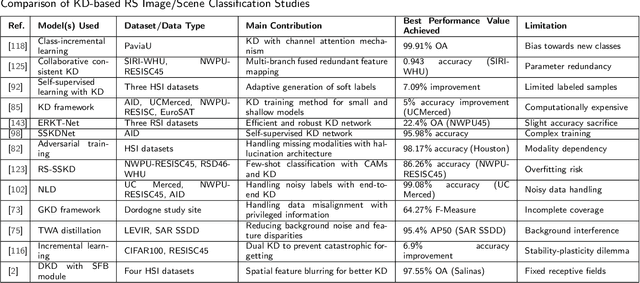
With the ever-growing complexity of models in the field of remote sensing (RS), there is an increasing demand for solutions that balance model accuracy with computational efficiency. Knowledge distillation (KD) has emerged as a powerful tool to meet this need, enabling the transfer of knowledge from large, complex models to smaller, more efficient ones without significant loss in performance. This review article provides an extensive examination of KD and its innovative applications in RS. KD, a technique developed to transfer knowledge from a complex, often cumbersome model (teacher) to a more compact and efficient model (student), has seen significant evolution and application across various domains. Initially, we introduce the fundamental concepts and historical progression of KD methods. The advantages of employing KD are highlighted, particularly in terms of model compression, enhanced computational efficiency, and improved performance, which are pivotal for practical deployments in RS scenarios. The article provides a comprehensive taxonomy of KD techniques, where each category is critically analyzed to demonstrate the breadth and depth of the alternative options, and illustrates specific case studies that showcase the practical implementation of KD methods in RS tasks, such as instance segmentation and object detection. Further, the review discusses the challenges and limitations of KD in RS, including practical constraints and prospective future directions, providing a comprehensive overview for researchers and practitioners in the field of RS. Through this organization, the paper not only elucidates the current state of research in KD but also sets the stage for future research opportunities, thereby contributing significantly to both academic research and real-world applications.
Transformer-based Image and Video Inpainting: Current Challenges and Future Directions
Jun 28, 2024



Image inpainting is currently a hot topic within the field of computer vision. It offers a viable solution for various applications, including photographic restoration, video editing, and medical imaging. Deep learning advancements, notably convolutional neural networks (CNNs) and generative adversarial networks (GANs), have significantly enhanced the inpainting task with an improved capability to fill missing or damaged regions in an image or video through the incorporation of contextually appropriate details. These advancements have improved other aspects, including efficiency, information preservation, and achieving both realistic textures and structures. Recently, visual transformers have been exploited and offer some improvements to image or video inpainting. The advent of transformer-based architectures, which were initially designed for natural language processing, has also been integrated into computer vision tasks. These methods utilize self-attention mechanisms that excel in capturing long-range dependencies within data; therefore, they are particularly effective for tasks requiring a comprehensive understanding of the global context of an image or video. In this paper, we provide a comprehensive review of the current image or video inpainting approaches, with a specific focus on transformer-based techniques, with the goal to highlight the significant improvements and provide a guideline for new researchers in the field of image or video inpainting using visual transformers. We categorized the transformer-based techniques by their architectural configurations, types of damage, and performance metrics. Furthermore, we present an organized synthesis of the current challenges, and suggest directions for future research in the field of image or video inpainting.
Drone-type-Set: Drone types detection benchmark for drone detection and tracking
May 16, 2024



The Unmanned Aerial Vehicles (UAVs) market has been significantly growing and Considering the availability of drones at low-cost prices the possibility of misusing them, for illegal purposes such as drug trafficking, spying, and terrorist attacks posing high risks to national security, is rising. Therefore, detecting and tracking unauthorized drones to prevent future attacks that threaten lives, facilities, and security, become a necessity. Drone detection can be performed using different sensors, while image-based detection is one of them due to the development of artificial intelligence techniques. However, knowing unauthorized drone types is one of the challenges due to the lack of drone types datasets. For that, in this paper, we provide a dataset of various drones as well as a comparison of recognized object detection models on the proposed dataset including YOLO algorithms with their different versions, like, v3, v4, and v5 along with the Detectronv2. The experimental results of different models are provided along with a description of each method. The collected dataset can be found in https://drive.google.com/drive/folders/1EPOpqlF4vG7hp4MYnfAecVOsdQ2JwBEd?usp=share_link
3D objects and scenes classification, recognition, segmentation, and reconstruction using 3D point cloud data: A review
Jun 09, 2023
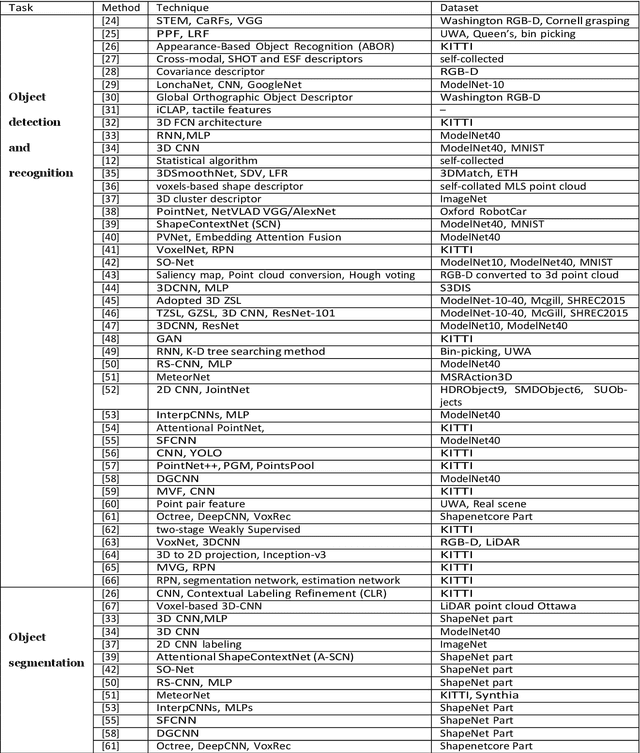
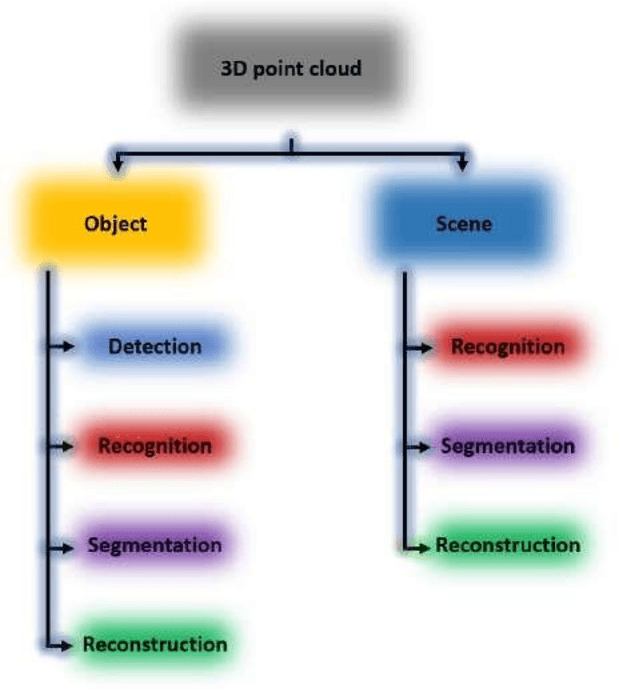
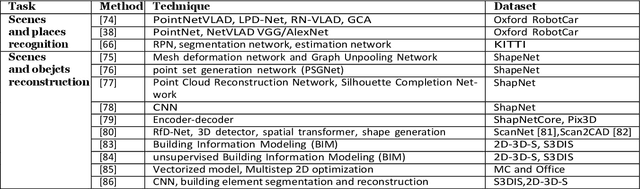
Three-dimensional (3D) point cloud analysis has become one of the attractive subjects in realistic imaging and machine visions due to its simplicity, flexibility and powerful capacity of visualization. Actually, the representation of scenes and buildings using 3D shapes and formats leveraged many applications among which automatic driving, scenes and objects reconstruction, etc. Nevertheless, working with this emerging type of data has been a challenging task for objects representation, scenes recognition, segmentation, and reconstruction. In this regard, a significant effort has recently been devoted to developing novel strategies, using different techniques such as deep learning models. To that end, we present in this paper a comprehensive review of existing tasks on 3D point cloud: a well-defined taxonomy of existing techniques is performed based on the nature of the adopted algorithms, application scenarios, and main objectives. Various tasks performed on 3D point could data are investigated, including objects and scenes detection, recognition, segmentation and reconstruction. In addition, we introduce a list of used datasets, we discuss respective evaluation metrics and we compare the performance of existing solutions to better inform the state-of-the-art and identify their limitations and strengths. Lastly, we elaborate on current challenges facing the subject of technology and future trends attracting considerable interest, which could be a starting point for upcoming research studies
Backbones-Review: Feature Extraction Networks for Deep Learning and Deep Reinforcement Learning Approaches
Jun 16, 2022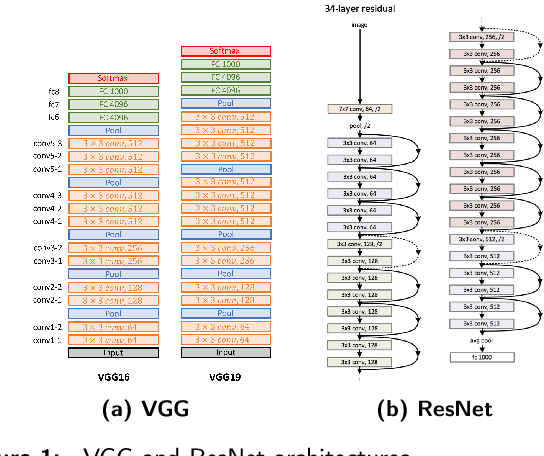

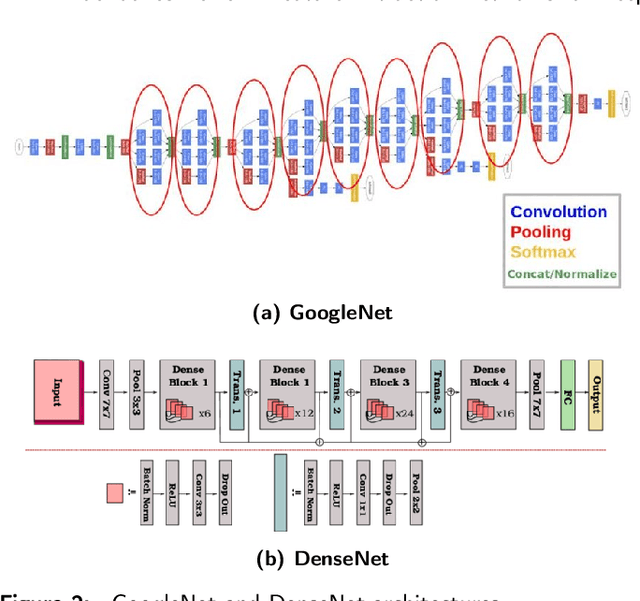
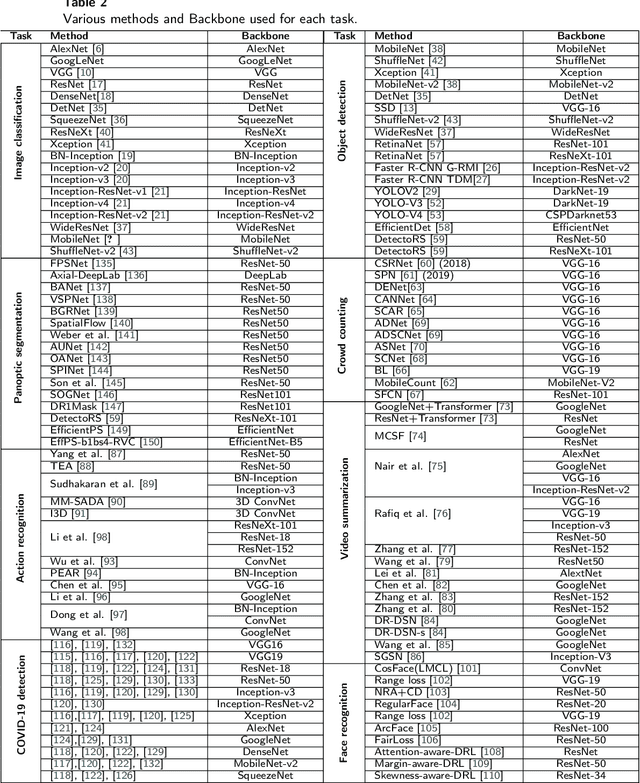
To understand the real world using various types of data, Artificial Intelligence (AI) is the most used technique nowadays. While finding the pattern within the analyzed data represents the main task. This is performed by extracting representative features step, which is proceeded using the statistical algorithms or using some specific filters. However, the selection of useful features from large-scale data represented a crucial challenge. Now, with the development of convolution neural networks (CNNs), the feature extraction operation has become more automatic and easier. CNNs allow to work on large-scale size of data, as well as cover different scenarios for a specific task. For computer vision tasks, convolutional networks are used to extract features also for the other parts of a deep learning model. The selection of a suitable network for feature extraction or the other parts of a DL model is not random work. So, the implementation of such a model can be related to the target task as well as the computational complexity of it. Many networks have been proposed and become the famous networks used for any DL models in any AI task. These networks are exploited for feature extraction or at the beginning of any DL model which is named backbones. A backbone is a known network trained in many other tasks before and demonstrates its effectiveness. In this paper, an overview of the existing backbones, e.g. VGGs, ResNets, DenseNet, etc, is given with a detailed description. Also, a couple of computer vision tasks are discussed by providing a review of each task regarding the backbones used. In addition, a comparison in terms of performance is also provided, based on the backbone used for each task.
Panoptic Segmentation: A Review
Nov 19, 2021

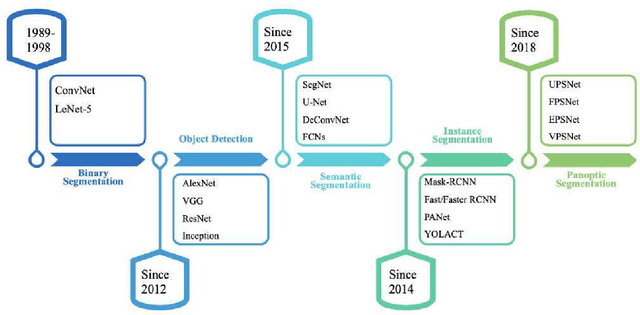

Image segmentation for video analysis plays an essential role in different research fields such as smart city, healthcare, computer vision and geoscience, and remote sensing applications. In this regard, a significant effort has been devoted recently to developing novel segmentation strategies; one of the latest outstanding achievements is panoptic segmentation. The latter has resulted from the fusion of semantic and instance segmentation. Explicitly, panoptic segmentation is currently under study to help gain a more nuanced knowledge of the image scenes for video surveillance, crowd counting, self-autonomous driving, medical image analysis, and a deeper understanding of the scenes in general. To that end, we present in this paper the first comprehensive review of existing panoptic segmentation methods to the best of the authors' knowledge. Accordingly, a well-defined taxonomy of existing panoptic techniques is performed based on the nature of the adopted algorithms, application scenarios, and primary objectives. Moreover, the use of panoptic segmentation for annotating new datasets by pseudo-labeling is discussed. Moving on, ablation studies are carried out to understand the panoptic methods from different perspectives. Moreover, evaluation metrics suitable for panoptic segmentation are discussed, and a comparison of the performance of existing solutions is provided to inform the state-of-the-art and identify their limitations and strengths. Lastly, the current challenges the subject technology faces and the future trends attracting considerable interest in the near future are elaborated, which can be a starting point for the upcoming research studies. The papers provided with code are available at: https://github.com/elharroussomar/Awesome-Panoptic-Segmentation
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021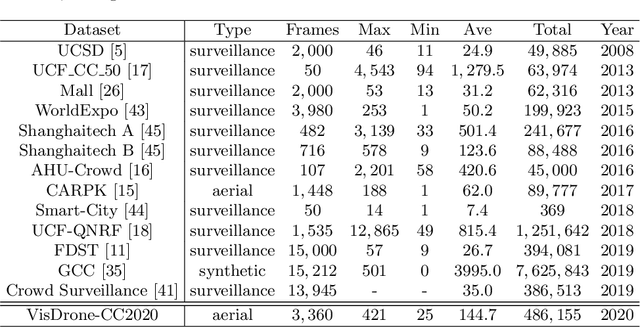

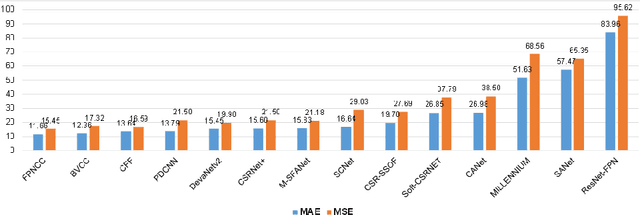
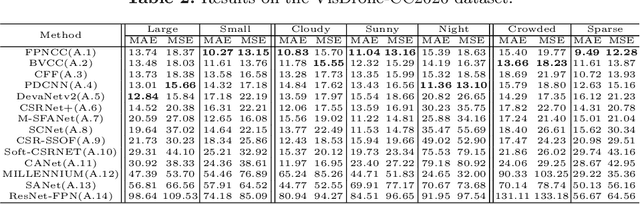
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added
An encoder-decoder-based method for COVID-19 lung infection segmentation
Jul 04, 2020
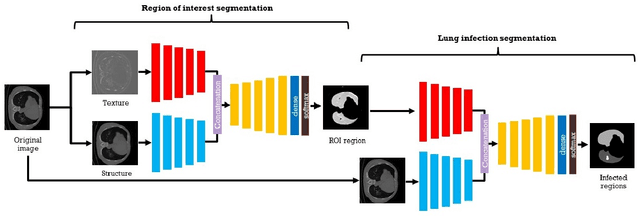
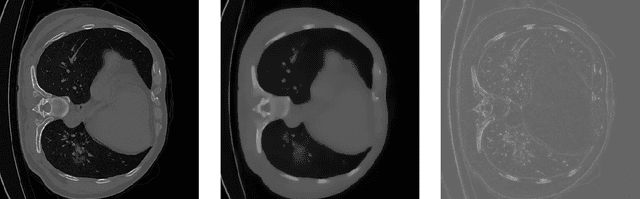
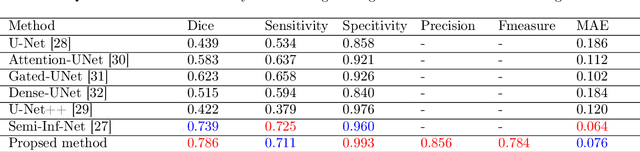
The novelty of the COVID-19 disease and the speed of spread has created a colossal chaos, impulse among researchers worldwide to exploit all the resources and capabilities to understand and analyze characteristics of the coronavirus in term of the ways it spreads and virus incubation time. For that, the existing medical features like CT and X-ray images are used. For example, CT-scan images can be used for the detection of lung infection. But the challenges of these features such as the quality of the image and infection characteristics limitate the effectiveness of these features. Using artificial intelligence (AI) tools and computer vision algorithms, the accuracy of detection can be more accurate and can help to overcome these issues. This paper proposes a multi-task deep-learning-based method for lung infection segmentation using CT-scan images. Our proposed method starts by segmenting the lung regions that can be infected. Then, segmenting the infections in these regions. Also, to perform a multi-class segmentation the proposed model is trained using the two-stream inputs. The multi-task learning used in this paper allows us to overcome shortage of labeled data. Also, the multi-input stream allows the model to do the learning on many features that can improve the results. To evaluate the proposed method, many features have been used. Also, from the experiments, the proposed method can segment lung infections with a high degree performance even with shortage of data and labeled images. In addition, comparing with the state-of-the-art method our method achieves good performance results.