 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Nov 07, 2025Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Jun 12, 2025



In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95\% and CUDA latency by 78\%, while maintaining 94\% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
TimeSearch: Hierarchical Video Search with Spotlight and Reflection for Human-like Long Video Understanding
Apr 02, 2025



Large video-language models (LVLMs) have shown remarkable performance across various video-language tasks. However, they encounter significant challenges when processing long videos because of the large number of video frames involved. Downsampling long videos in either space or time can lead to visual hallucinations, making it difficult to accurately interpret long videos. Motivated by human hierarchical temporal search strategies, we propose \textbf{TimeSearch}, a novel framework enabling LVLMs to understand long videos in a human-like manner. TimeSearch integrates two human-like primitives into a unified autoregressive LVLM: 1) \textbf{Spotlight} efficiently identifies relevant temporal events through a Temporal-Augmented Frame Representation (TAFR), explicitly binding visual features with timestamps; 2) \textbf{Reflection} evaluates the correctness of the identified events, leveraging the inherent temporal self-reflection capabilities of LVLMs. TimeSearch progressively explores key events and prioritizes temporal search based on reflection confidence. Extensive experiments on challenging long-video benchmarks confirm that TimeSearch substantially surpasses previous state-of-the-art, improving the accuracy from 41.8\% to 51.5\% on the LVBench. Additionally, experiments on temporal grounding demonstrate that appropriate TAFR is adequate to effectively stimulate the surprising temporal grounding ability of LVLMs in a simpler yet versatile manner, which improves mIoU on Charades-STA by 11.8\%. The code will be released.
MammothModa: Multi-Modal Large Language Model
Jun 26, 2024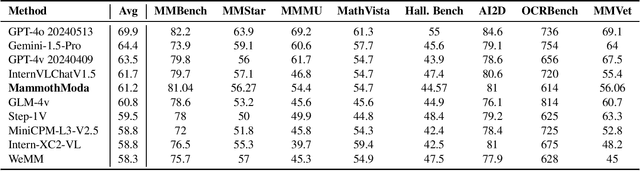



In this report, we introduce MammothModa, yet another multi-modal large language model (MLLM) designed to achieve state-of-the-art performance starting from an elementary baseline. We focus on three key design insights: (i) Integrating Visual Capabilities while Maintaining Complex Language Understanding: In addition to the vision encoder, we incorporated the Visual Attention Experts into the LLM to enhance its visual capabilities. (ii) Extending Context Window for High-Resolution and Long-Duration Visual Feature: We explore the Visual Merger Module to effectively reduce the token number of high-resolution images and incorporated frame position ids to avoid position interpolation. (iii) High-Quality Bilingual Datasets: We meticulously curated and filtered a high-quality bilingual multimodal dataset to reduce visual hallucinations. With above recipe we build MammothModa that consistently outperforms the state-of-the-art models, e.g., LLaVA-series, across main real-world visual language benchmarks without bells and whistles.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Learning Self-Supervised Low-Rank Network for Single-Stage Weakly and Semi-Supervised Semantic Segmentation
Mar 19, 2022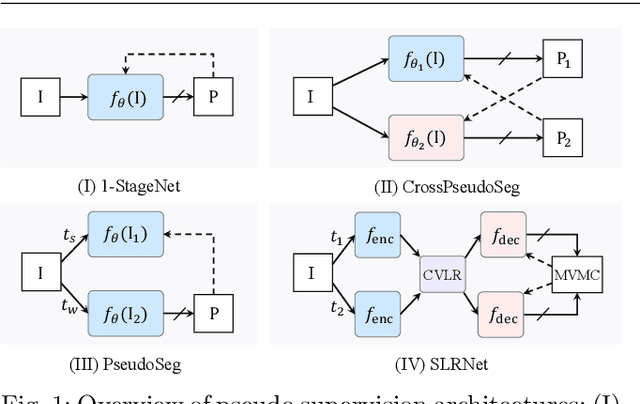
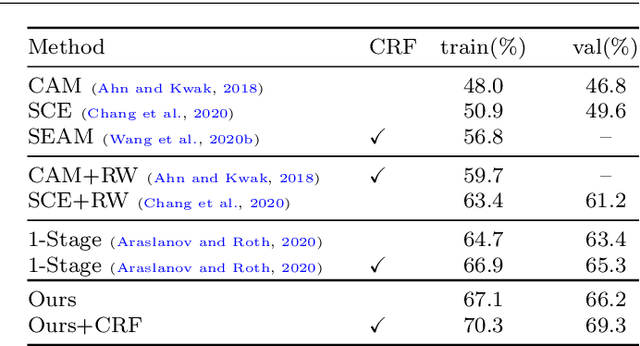
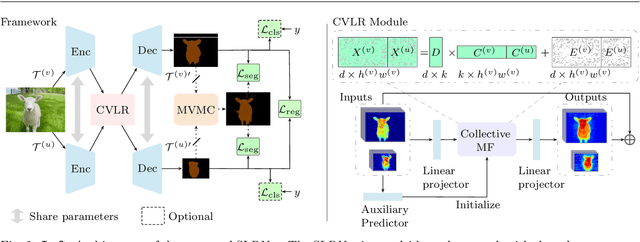
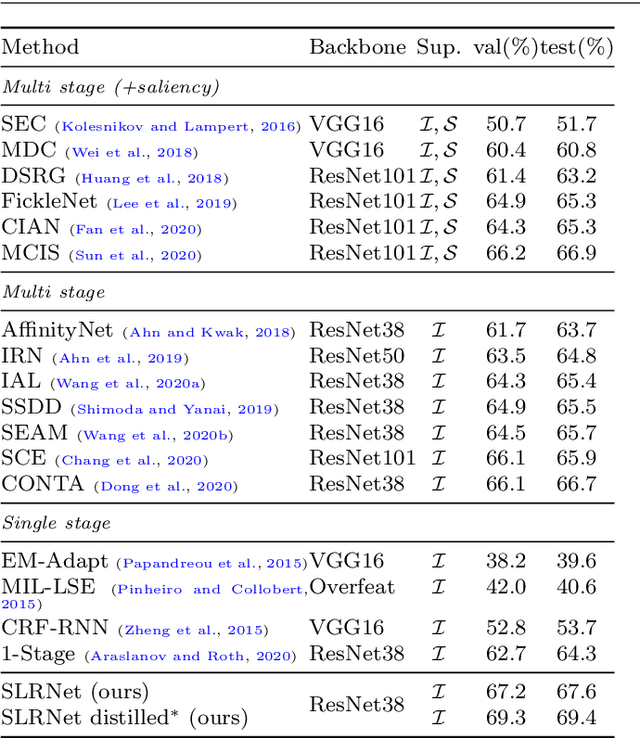
Semantic segmentation with limited annotations, such as weakly supervised semantic segmentation (WSSS) and semi-supervised semantic segmentation (SSSS), is a challenging task that has attracted much attention recently. Most leading WSSS methods employ a sophisticated multi-stage training strategy to estimate pseudo-labels as precise as possible, but they suffer from high model complexity. In contrast, there exists another research line that trains a single network with image-level labels in one training cycle. However, such a single-stage strategy often performs poorly because of the compounding effect caused by inaccurate pseudo-label estimation. To address this issue, this paper presents a Self-supervised Low-Rank Network (SLRNet) for single-stage WSSS and SSSS. The SLRNet uses cross-view self-supervision, that is, it simultaneously predicts several complementary attentive LR representations from different views of an image to learn precise pseudo-labels. Specifically, we reformulate the LR representation learning as a collective matrix factorization problem and optimize it jointly with the network learning in an end-to-end manner. The resulting LR representation deprecates noisy information while capturing stable semantics across different views, making it robust to the input variations, thereby reducing overfitting to self-supervision errors. The SLRNet can provide a unified single-stage framework for various label-efficient semantic segmentation settings: 1) WSSS with image-level labeled data, 2) SSSS with a few pixel-level labeled data, and 3) SSSS with a few pixel-level labeled data and many image-level labeled data. Extensive experiments on the Pascal VOC 2012, COCO, and L2ID datasets demonstrate that our SLRNet outperforms both state-of-the-art WSSS and SSSS methods with a variety of different settings, proving its good generalizability and efficacy.
Label-efficient Hybrid-supervised Learning for Medical Image Segmentation
Mar 10, 2022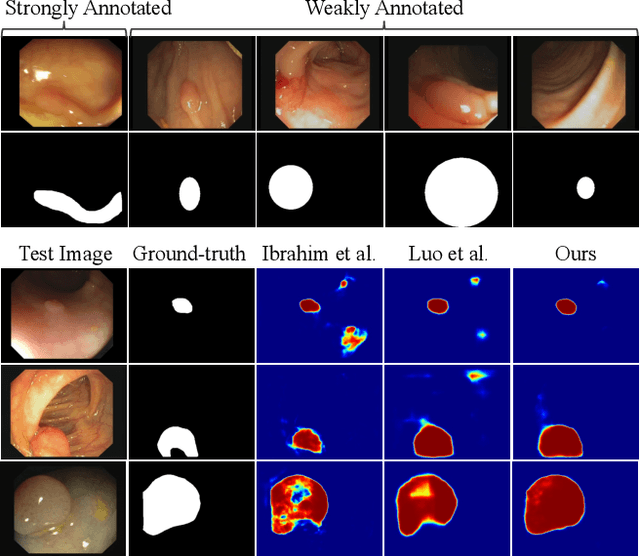

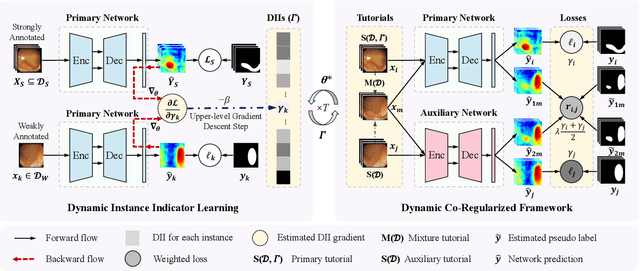
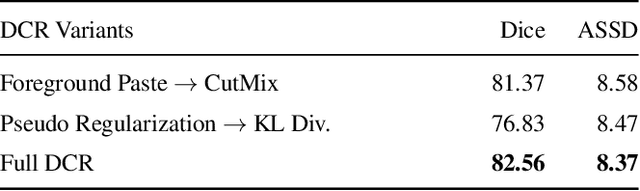
Due to the lack of expertise for medical image annotation, the investigation of label-efficient methodology for medical image segmentation becomes a heated topic. Recent progresses focus on the efficient utilization of weak annotations together with few strongly-annotated labels so as to achieve comparable segmentation performance in many unprofessional scenarios. However, these approaches only concentrate on the supervision inconsistency between strongly- and weakly-annotated instances but ignore the instance inconsistency inside the weakly-annotated instances, which inevitably leads to performance degradation. To address this problem, we propose a novel label-efficient hybrid-supervised framework, which considers each weakly-annotated instance individually and learns its weight guided by the gradient direction of the strongly-annotated instances, so that the high-quality prior in the strongly-annotated instances is better exploited and the weakly-annotated instances are depicted more precisely. Specially, our designed dynamic instance indicator (DII) realizes the above objectives, and is adapted to our dynamic co-regularization (DCR) framework further to alleviate the erroneous accumulation from distortions of weak annotations. Extensive experiments on two hybrid-supervised medical segmentation datasets demonstrate that with only 10% strong labels, the proposed framework can leverage the weak labels efficiently and achieve competitive performance against the 100% strong-label supervised scenario.
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021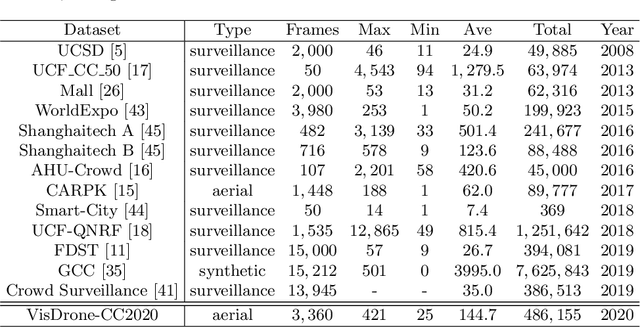

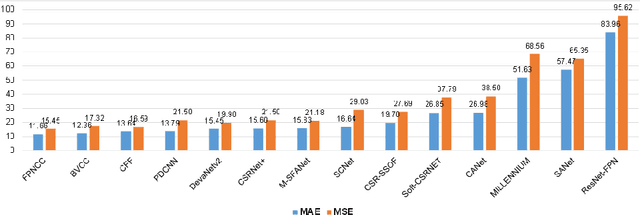
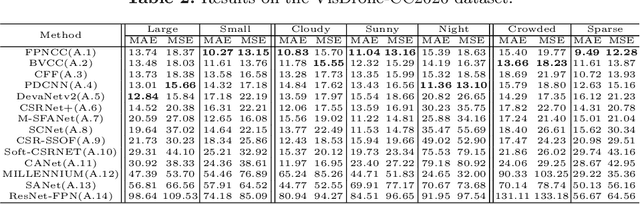
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added