 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFE-DE: Learning Meta Feature Embedding for Depth Estimation from Monocular Endoscopic Images
Feb 05, 2025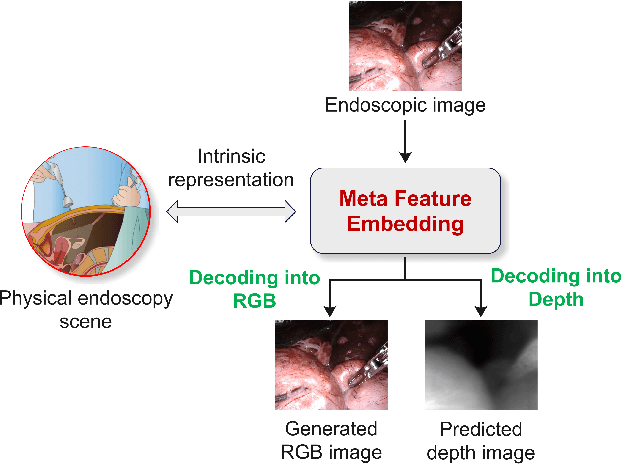

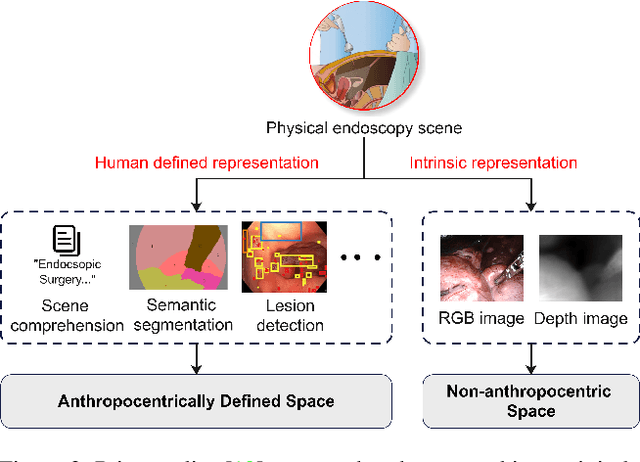

Depth estimation from monocular endoscopic images presents significant challenges due to the complexity of endoscopic surgery, such as irregular shapes of human soft tissues, as well as variations in lighting conditions. Existing methods primarily estimate the depth information from RGB images directly, and often surffer the limited interpretability and accuracy. Given that RGB and depth images are two views of the same endoscopic surgery scene, in this paper, we introduce a novel concept referred as ``meta feature embedding (MetaFE)", in which the physical entities (e.g., tissues and surgical instruments) of endoscopic surgery are represented using the shared features that can be alternatively decoded into RGB or depth image. With this concept, we propose a two-stage self-supervised learning paradigm for the monocular endoscopic depth estimation. In the first stage, we propose a temporal representation learner using diffusion models, which are aligned with the spatial information through the cross normalization to construct the MetaFE. In the second stage, self-supervised monocular depth estimation with the brightness calibration is applied to decode the meta features into the depth image. Extensive evaluation on diverse endoscopic datasets demonstrates that our approach outperforms the state-of-the-art method in depth estimation, achieving superior accuracy and generalization. The source code will be publicly available.
MammothModa: Multi-Modal Large Language Model
Jun 26, 2024In this report, we introduce MammothModa, yet another multi-modal large language model (MLLM) designed to achieve state-of-the-art performance starting from an elementary baseline. We focus on three key design insights: (i) Integrating Visual Capabilities while Maintaining Complex Language Understanding: In addition to the vision encoder, we incorporated the Visual Attention Experts into the LLM to enhance its visual capabilities. (ii) Extending Context Window for High-Resolution and Long-Duration Visual Feature: We explore the Visual Merger Module to effectively reduce the token number of high-resolution images and incorporated frame position ids to avoid position interpolation. (iii) High-Quality Bilingual Datasets: We meticulously curated and filtered a high-quality bilingual multimodal dataset to reduce visual hallucinations. With above recipe we build MammothModa that consistently outperforms the state-of-the-art models, e.g., LLaVA-series, across main real-world visual language benchmarks without bells and whistles.
Learning Syntactic Dense Embedding with Correlation Graph for Automatic Readability Assessment
Jul 09, 2021



Deep learning models for automatic readability assessment generally discard linguistic features traditionally used in machine learning models for the task. We propose to incorporate linguistic features into neural network models by learning syntactic dense embeddings based on linguistic features. To cope with the relationships between the features, we form a correlation graph among features and use it to learn their embeddings so that similar features will be represented by similar embeddings. Experiments with six data sets of two proficiency levels demonstrate that our proposed methodology can complement BERT-only model to achieve significantly better performances for automatic readability assessment.