 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Orders of User Behaviors via Differentiable Sorting: A Multi-task Framework to Predicting User Post-click Conversion
Jul 18, 2023User post-click conversion prediction is of high interest to researchers and developers. Recent studies employ multi-task learning to tackle the selection bias and data sparsity problem, two severe challenges in post-click behavior prediction, by incorporating click data. However, prior works mainly focused on pointwise learning and the orders of labels (i.e., click and post-click) are not well explored, which naturally poses a listwise learning problem. Inspired by recent advances on differentiable sorting, in this paper, we propose a novel multi-task framework that leverages orders of user behaviors to predict user post-click conversion in an end-to-end approach. Specifically, we define an aggregation operator to combine predicted outputs of different tasks to a unified score, then we use the computed scores to model the label relations via differentiable sorting. Extensive experiments on public and industrial datasets show the superiority of our proposed model against competitive baselines.
PhysFormer++: Facial Video-based Physiological Measurement with SlowFast Temporal Difference Transformer
Feb 07, 2023Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose two end-to-end video transformer based architectures, namely PhysFormer and PhysFormer++, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. To better exploit the temporal contextual and periodic rPPG clues, we also extend the PhysFormer to the two-pathway SlowFast based PhysFormer++ with temporal difference periodic and cross-attention transformers. Furthermore, we propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and PhysFormer++ and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. Unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer family can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community.
Evolutionary Generalized Zero-Shot Learning
Nov 23, 2022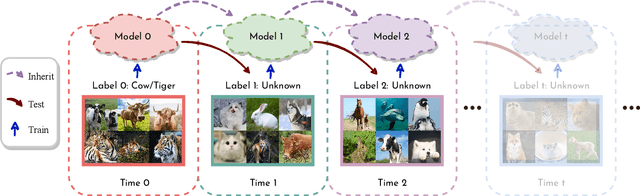
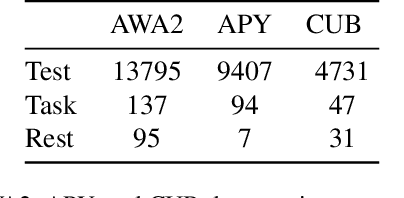
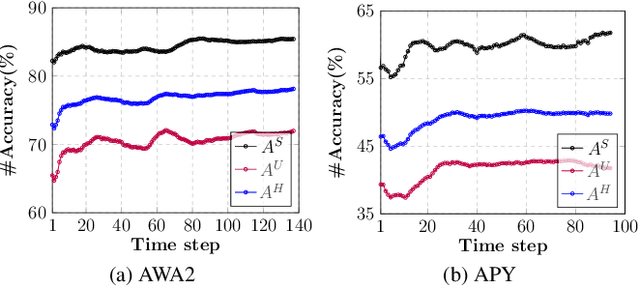
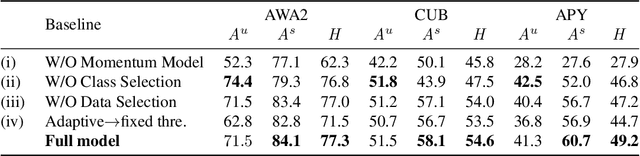
An open problem on the path to artificial intelligence is generalization from the known to the unknown, which is instantiated as Generalized Zero-Shot Learning (GZSL) task. In this work, we propose a novel Evolutionary Generalized Zero-Shot Learning setting, which (i) avoids the domain shift problem in inductive GZSL, and (ii) is more in line with the needs of real-world deployments than transductive GZSL. In the proposed setting, a zero-shot model with poor initial performance is able to achieve online evolution during application. We elaborate on three challenges of this special task, i.e., catastrophic forgetting, initial prediction bias, and evolutionary data class bias. Moreover, we propose targeted solutions for each challenge, resulting in a generic method capable of continuing to evolve on a given initial IGZSL model. Experiments on three popular GZSL benchmark datasets show that our model can learn from the test data stream while other baselines fail.
Mutual Balancing in State-Object Components for Compositional Zero-Shot Learning
Nov 19, 2022



Compositional Zero-Shot Learning (CZSL) aims to recognize unseen compositions from seen states and objects. The disparity between the manually labeled semantic information and its actual visual features causes a significant imbalance of visual deviation in the distribution of various object classes and state classes, which is ignored by existing methods. To ameliorate these issues, we consider the CZSL task as an unbalanced multi-label classification task and propose a novel method called MUtual balancing in STate-object components (MUST) for CZSL, which provides a balancing inductive bias for the model. In particular, we split the classification of the composition classes into two consecutive processes to analyze the entanglement of the two components to get additional knowledge in advance, which reflects the degree of visual deviation between the two components. We use the knowledge gained to modify the model's training process in order to generate more distinct class borders for classes with significant visual deviations. Extensive experiments demonstrate that our approach significantly outperforms the state-of-the-art on MIT-States, UT-Zappos, and C-GQA when combined with the basic CZSL frameworks, and it can improve various CZSL frameworks. Our codes are available on https://anonymous.4open.science/r/MUST_CGE/.
Collaborative Quantization Embeddings for Intra-Subject Prostate MR Image Registration
Jul 14, 2022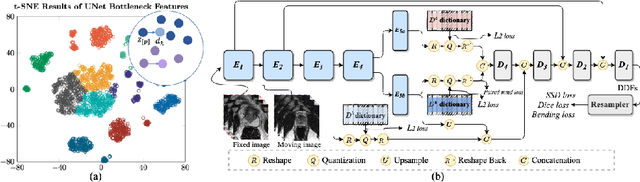
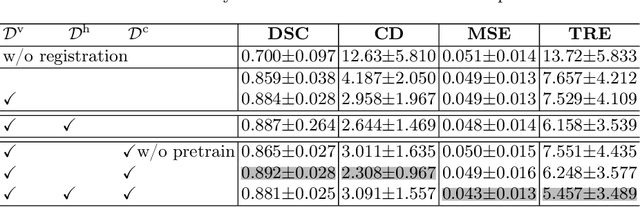
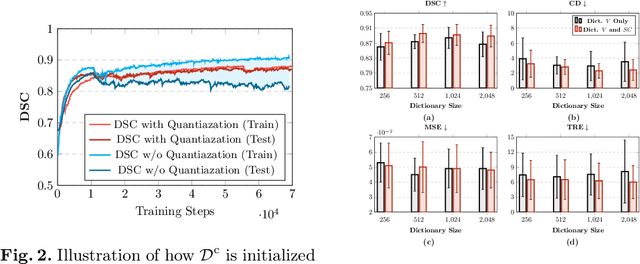
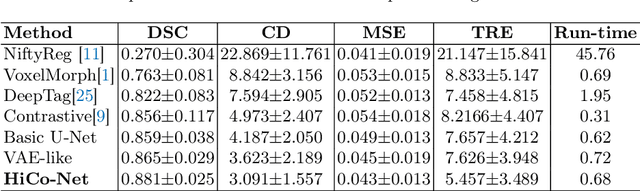
Image registration is useful for quantifying morphological changes in longitudinal MR images from prostate cancer patients. This paper describes a development in improving the learning-based registration algorithms, for this challenging clinical application often with highly variable yet limited training data. First, we report that the latent space can be clustered into a much lower dimensional space than that commonly found as bottleneck features at the deep layer of a trained registration network. Based on this observation, we propose a hierarchical quantization method, discretizing the learned feature vectors using a jointly-trained dictionary with a constrained size, in order to improve the generalisation of the registration networks. Furthermore, a novel collaborative dictionary is independently optimised to incorporate additional prior information, such as the segmentation of the gland or other regions of interest, in the latent quantized space. Based on 216 real clinical images from 86 prostate cancer patients, we show the efficacy of both the designed components. Improved registration accuracy was obtained with statistical significance, in terms of both Dice on gland and target registration error on corresponding landmarks, the latter of which achieved 5.46 mm, an improvement of 28.7\% from the baseline without quantization. Experimental results also show that the difference in performance was indeed minimised between training and testing data.
Zero-Shot Logit Adjustment
May 05, 2022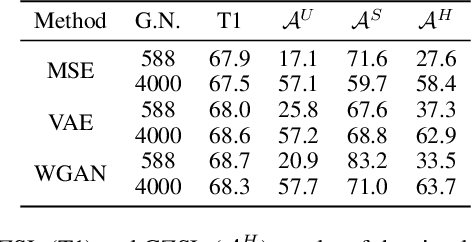
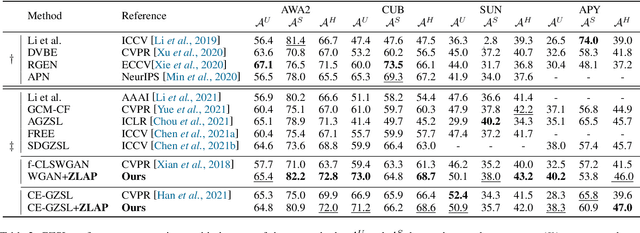
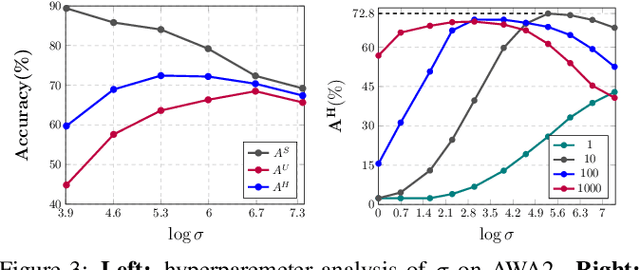
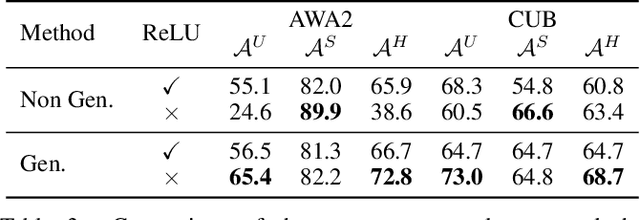
Semantic-descriptor-based Generalized Zero-Shot Learning (GZSL) poses challenges in recognizing novel classes in the test phase. The development of generative models enables current GZSL techniques to probe further into the semantic-visual link, culminating in a two-stage form that includes a generator and a classifier. However, existing generation-based methods focus on enhancing the generator's effect while neglecting the improvement of the classifier. In this paper, we first analyze of two properties of the generated pseudo unseen samples: bias and homogeneity. Then, we perform variational Bayesian inference to back-derive the evaluation metrics, which reflects the balance of the seen and unseen classes. As a consequence of our derivation, the aforementioned two properties are incorporated into the classifier training as seen-unseen priors via logit adjustment. The Zero-Shot Logit Adjustment further puts semantic-based classifiers into effect in generation-based GZSL. Our experiments demonstrate that the proposed technique achieves state-of-the-art when combined with the basic generator, and it can improve various generative Zero-Shot Learning frameworks. Our codes are available on https://github.com/cdb342/IJCAI-2022-ZLA.
Towards the Semantic Weak Generalization Problem in Generative Zero-Shot Learning: Ante-hoc and Post-hoc
Apr 24, 2022
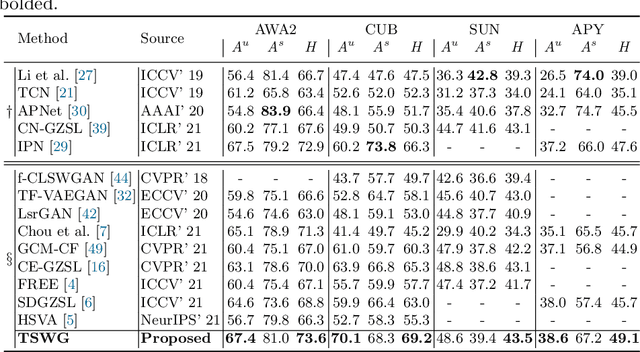
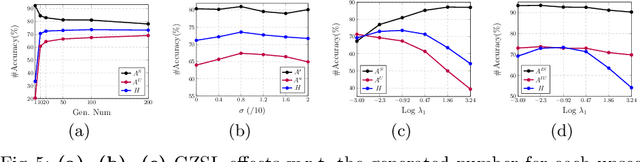
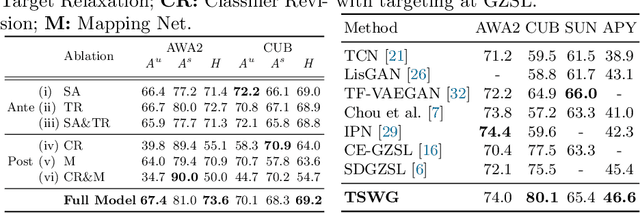
In this paper, we present a simple and effective strategy lowering the previously unexplored factors that limit the performance ceiling of generative Zero-Shot Learning (ZSL). We begin by formally defining semantic generalization, then look into approaches for reducing the semantic weak generalization problem and minimizing its negative influence on classifier training. In the ante-hoc phase, we augment the generator's semantic input, as well as relax the fitting target of the generator. In the post-hoc phase (after generating simulated unseen samples), we derive from the gradient of the loss function to minimize the gradient increment on seen classifier weights carried by biased unseen distribution, which tends to cause misleading on intra-seen class decision boundaries. Without complicated designs, our approach hit the essential problem and significantly outperform the state-of-the-art on four widely used ZSL datasets.
MP2: A Momentum Contrast Approach for Recommendation with Pointwise and Pairwise Learning
Apr 18, 2022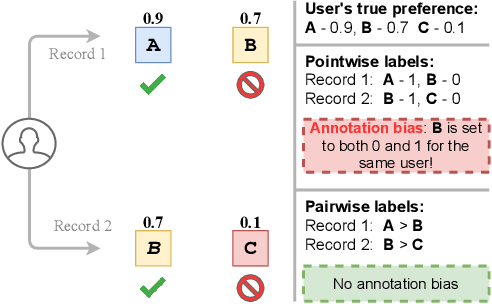
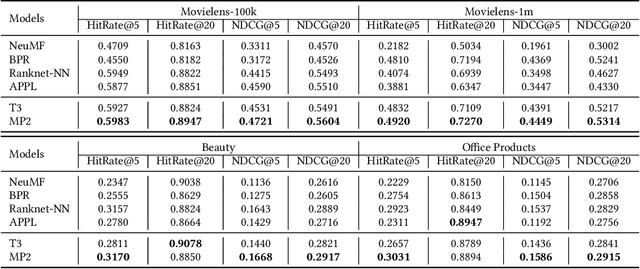
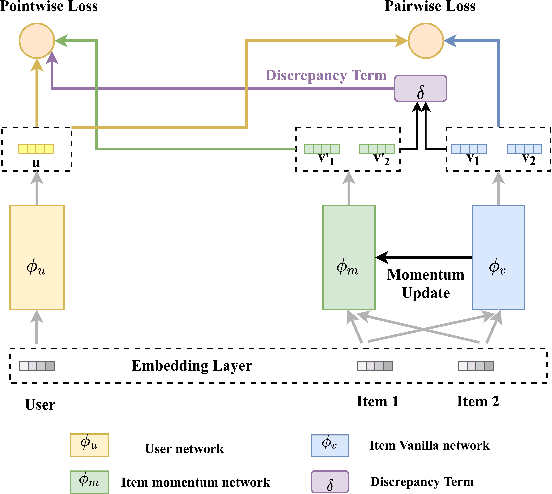
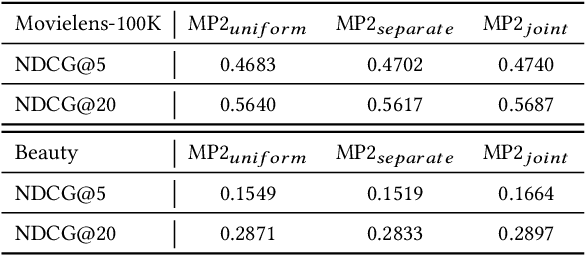
Binary pointwise labels (aka implicit feedback) are heavily leveraged by deep learning based recommendation algorithms nowadays. In this paper we discuss the limited expressiveness of these labels may fail to accommodate varying degrees of user preference, and thus lead to conflicts during model training, which we call annotation bias. To solve this issue, we find the soft-labeling property of pairwise labels could be utilized to alleviate the bias of pointwise labels. To this end, we propose a momentum contrast framework (MP2) that combines pointwise and pairwise learning for recommendation. MP2 has a three-tower network structure: one user network and two item networks. The two item networks are used for computing pointwise and pairwise loss respectively. To alleviate the influence of the annotation bias, we perform a momentum update to ensure a consistent item representation. Extensive experiments on real-world datasets demonstrate the superiority of our method against state-of-the-art recommendation algorithms.
Learning to Hash Naturally Sorts
Jan 31, 2022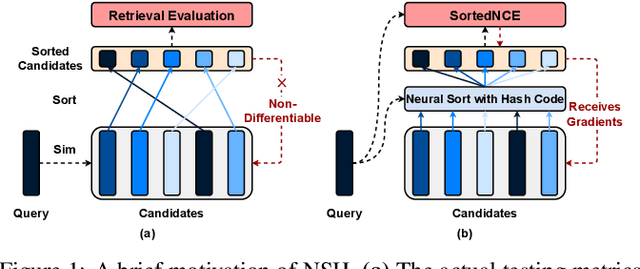
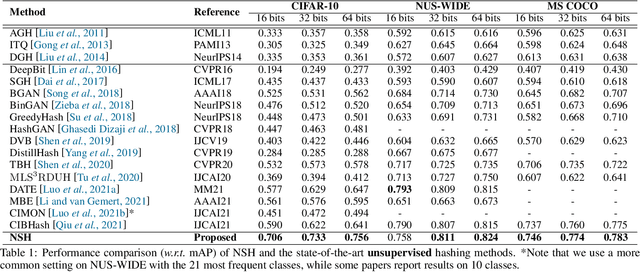
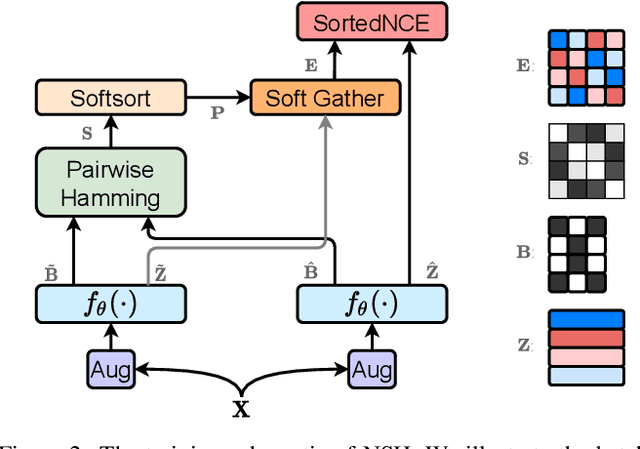
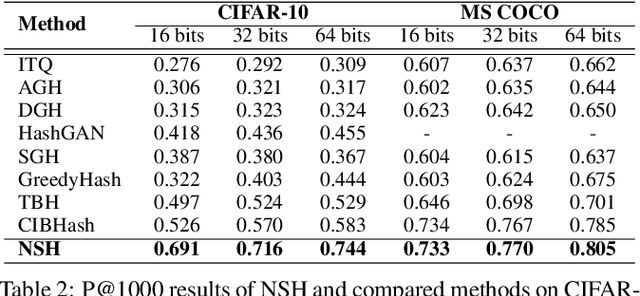
Locality sensitive hashing pictures a list-wise sorting problem. Its testing metrics, e.g., mean-average precision, count on a sorted candidate list ordered by pair-wise code similarity. However, scarcely does one train a deep hashing model with the sorted results end-to-end because of the non-differentiable nature of the sorting operation. This inconsistency in the objectives of training and test may lead to sub-optimal performance since the training loss often fails to reflect the actual retrieval metric. In this paper, we tackle this problem by introducing Naturally-Sorted Hashing (NSH). We sort the Hamming distances of samples' hash codes and accordingly gather their latent representations for self-supervised training. Thanks to the recent advances in differentiable sorting approximations, the hash head receives gradients from the sorter so that the hash encoder can be optimized along with the training procedure. Additionally, we describe a novel Sorted Noise-Contrastive Estimation (SortedNCE) loss that selectively picks positive and negative samples for contrastive learning, which allows NSH to mine data semantic relations during training in an unsupervised manner. Our extensive experiments show the proposed NSH model significantly outperforms the existing unsupervised hashing methods on three benchmarked datasets.
Boosting Generative Zero-Shot Learning by Synthesizing Diverse Features with Attribute Augmentation
Dec 23, 2021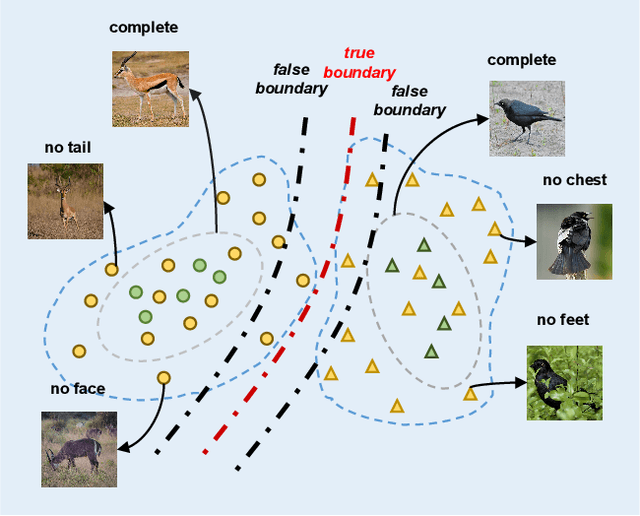
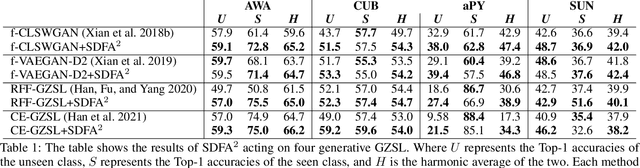
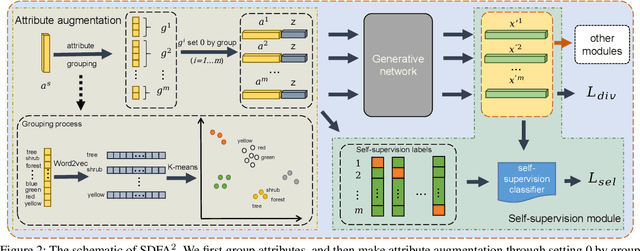
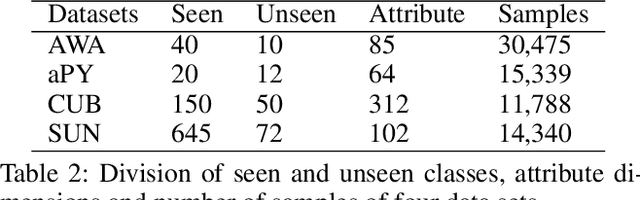
The recent advance in deep generative models outlines a promising perspective in the realm of Zero-Shot Learning (ZSL). Most generative ZSL methods use category semantic attributes plus a Gaussian noise to generate visual features. After generating unseen samples, this family of approaches effectively transforms the ZSL problem into a supervised classification scheme. However, the existing models use a single semantic attribute, which contains the complete attribute information of the category. The generated data also carry the complete attribute information, but in reality, visual samples usually have limited attributes. Therefore, the generated data from attribute could have incomplete semantics. Based on this fact, we propose a novel framework to boost ZSL by synthesizing diverse features. This method uses augmented semantic attributes to train the generative model, so as to simulate the real distribution of visual features. We evaluate the proposed model on four benchmark datasets, observing significant performance improvement against the state-of-the-art.