 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFM3Q: Factorized Multi-Agent MiniMax Q-Learning for Two-Team Zero-Sum Markov Game
Feb 01, 2024Many real-world applications involve some agents that fall into two teams, with payoffs that are equal within the same team but of opposite sign across the opponent team. The so-called two-team zero-sum Markov games (2t0sMGs) can be resolved with reinforcement learning in recent years. However, existing methods are thus inefficient in light of insufficient consideration of intra-team credit assignment, data utilization and computational intractability. In this paper, we propose the individual-global-minimax (IGMM) principle to ensure the coherence between two-team minimax behaviors and the individual greedy behaviors through Q functions in 2t0sMGs. Based on it, we present a novel multi-agent reinforcement learning framework, Factorized Multi-Agent MiniMax Q-Learning (FM3Q), which can factorize the joint minimax Q function into individual ones and iteratively solve for the IGMM-satisfied minimax Q functions for 2t0sMGs. Moreover, an online learning algorithm with neural networks is proposed to implement FM3Q and obtain the deterministic and decentralized minimax policies for two-team players. A theoretical analysis is provided to prove the convergence of FM3Q. Empirically, we use three environments to evaluate the learning efficiency and final performance of FM3Q and show its superiority on 2t0sMGs.
NeuronsMAE: A Novel Multi-Agent Reinforcement Learning Environment for Cooperative and Competitive Multi-Robot Tasks
Mar 22, 2023Multi-agent reinforcement learning (MARL) has achieved remarkable success in various challenging problems. Meanwhile, more and more benchmarks have emerged and provided some standards to evaluate the algorithms in different fields. On the one hand, the virtual MARL environments lack knowledge of real-world tasks and actuator abilities, and on the other hand, the current task-specified multi-robot platform has poor support for the generality of multi-agent reinforcement learning algorithms and lacks support for transferring from simulation to the real environment. Bridging the gap between the virtual MARL environments and the real multi-robot platform becomes the key to promoting the practicability of MARL algorithms. This paper proposes a novel MARL environment for real multi-robot tasks named NeuronsMAE (Neurons Multi-Agent Environment). This environment supports cooperative and competitive multi-robot tasks and is configured with rich parameter interfaces to study the multi-agent policy transfer from simulation to reality. With this platform, we evaluate various popular MARL algorithms and build a new MARL benchmark for multi-robot tasks. We hope that this platform will facilitate the research and application of MARL algorithms for real robot tasks. Information about the benchmark and the open-source code will be released.
MP2: A Momentum Contrast Approach for Recommendation with Pointwise and Pairwise Learning
Apr 18, 2022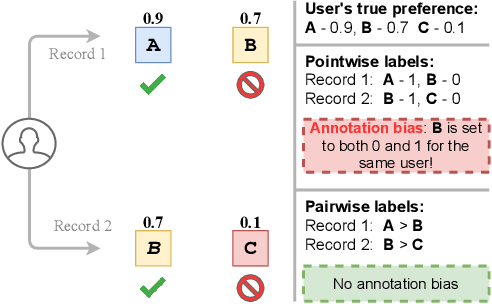
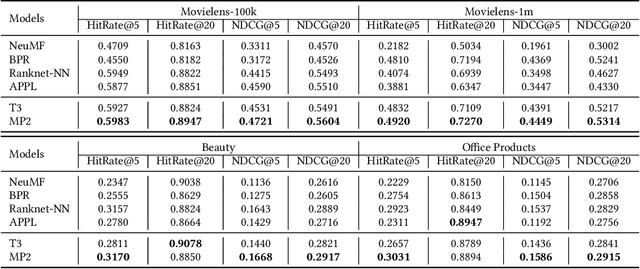
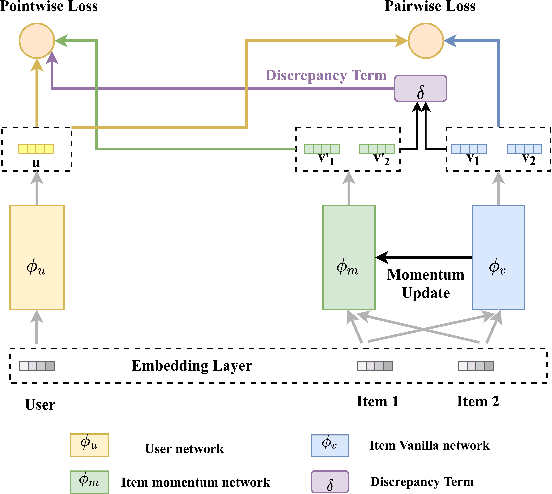
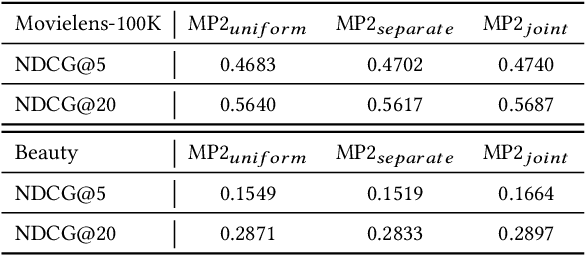
Binary pointwise labels (aka implicit feedback) are heavily leveraged by deep learning based recommendation algorithms nowadays. In this paper we discuss the limited expressiveness of these labels may fail to accommodate varying degrees of user preference, and thus lead to conflicts during model training, which we call annotation bias. To solve this issue, we find the soft-labeling property of pairwise labels could be utilized to alleviate the bias of pointwise labels. To this end, we propose a momentum contrast framework (MP2) that combines pointwise and pairwise learning for recommendation. MP2 has a three-tower network structure: one user network and two item networks. The two item networks are used for computing pointwise and pairwise loss respectively. To alleviate the influence of the annotation bias, we perform a momentum update to ensure a consistent item representation. Extensive experiments on real-world datasets demonstrate the superiority of our method against state-of-the-art recommendation algorithms.