 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Explainable Recommendation in E-commerce with LLM-powered Product Knowledge Graph
Nov 17, 2024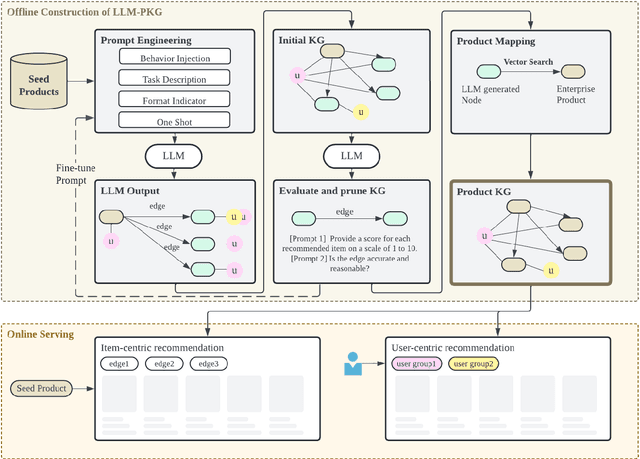



How to leverage large language model's superior capability in e-commerce recommendation has been a hot topic. In this paper, we propose LLM-PKG, an efficient approach that distills the knowledge of LLMs into product knowledge graph (PKG) and then applies PKG to provide explainable recommendations. Specifically, we first build PKG by feeding curated prompts to LLM, and then map LLM response to real enterprise products. To mitigate the risks associated with LLM hallucination, we employ rigorous evaluation and pruning methods to ensure the reliability and availability of the KG. Through an A/B test conducted on an e-commerce website, we demonstrate the effectiveness of LLM-PKG in driving user engagements and transactions significantly.
Modeling Orders of User Behaviors via Differentiable Sorting: A Multi-task Framework to Predicting User Post-click Conversion
Jul 18, 2023User post-click conversion prediction is of high interest to researchers and developers. Recent studies employ multi-task learning to tackle the selection bias and data sparsity problem, two severe challenges in post-click behavior prediction, by incorporating click data. However, prior works mainly focused on pointwise learning and the orders of labels (i.e., click and post-click) are not well explored, which naturally poses a listwise learning problem. Inspired by recent advances on differentiable sorting, in this paper, we propose a novel multi-task framework that leverages orders of user behaviors to predict user post-click conversion in an end-to-end approach. Specifically, we define an aggregation operator to combine predicted outputs of different tasks to a unified score, then we use the computed scores to model the label relations via differentiable sorting. Extensive experiments on public and industrial datasets show the superiority of our proposed model against competitive baselines.
Explainable Recommender with Geometric Information Bottleneck
May 09, 2023



Explainable recommender systems can explain their recommendation decisions, enhancing user trust in the systems. Most explainable recommender systems either rely on human-annotated rationales to train models for explanation generation or leverage the attention mechanism to extract important text spans from reviews as explanations. The extracted rationales are often confined to an individual review and may fail to identify the implicit features beyond the review text. To avoid the expensive human annotation process and to generate explanations beyond individual reviews, we propose to incorporate a geometric prior learnt from user-item interactions into a variational network which infers latent factors from user-item reviews. The latent factors from an individual user-item pair can be used for both recommendation and explanation generation, which naturally inherit the global characteristics encoded in the prior knowledge. Experimental results on three e-commerce datasets show that our model significantly improves the interpretability of a variational recommender using the Wasserstein distance while achieving performance comparable to existing content-based recommender systems in terms of recommendation behaviours.
Causal Inference Based Single-branch Ensemble Trees For Uplift Modeling
Feb 03, 2023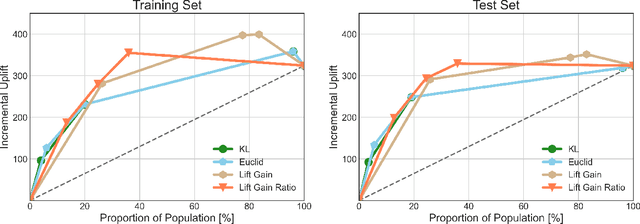


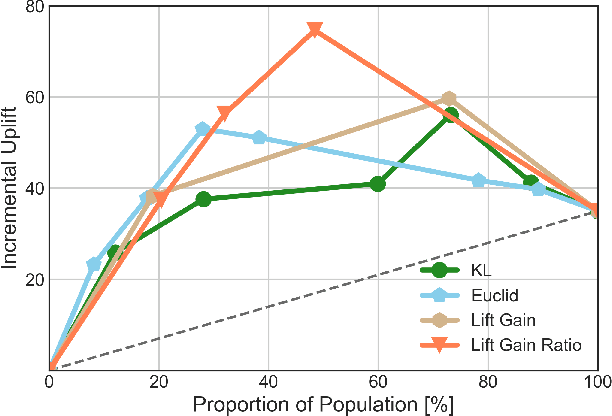
In this manuscript (ms), we propose causal inference based single-branch ensemble trees for uplift modeling, namely CIET. Different from standard classification methods for predictive probability modeling, CIET aims to achieve the change in the predictive probability of outcome caused by an action or a treatment. According to our CIET, two partition criteria are specifically designed to maximize the difference in outcome distribution between the treatment and control groups. Next, a novel single-branch tree is built by taking a top-down node partition approach, and the remaining samples are censored since they are not covered by the upper node partition logic. Repeating the tree-building process on the censored data, single-branch ensemble trees with a set of inference rules are thus formed. Moreover, CIET is experimentally demonstrated to outperform previous approaches for uplift modeling in terms of both area under uplift curve (AUUC) and Qini coefficient significantly. At present, CIET has already been applied to online personal loans in a national financial holdings group in China. CIET will also be of use to analysts applying machine learning techniques to causal inference in broader business domains such as web advertising, medicine and economics.
Human Mobility Prediction with Causal and Spatial-constrained Multi-task Network
Jun 12, 2022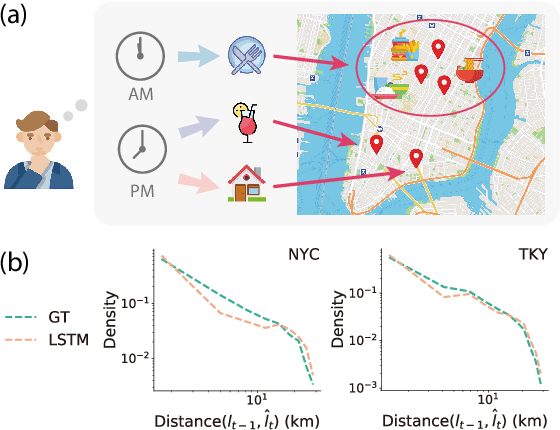
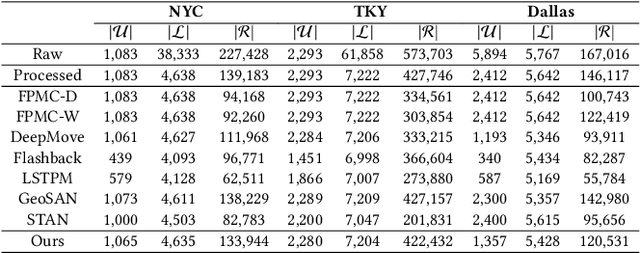
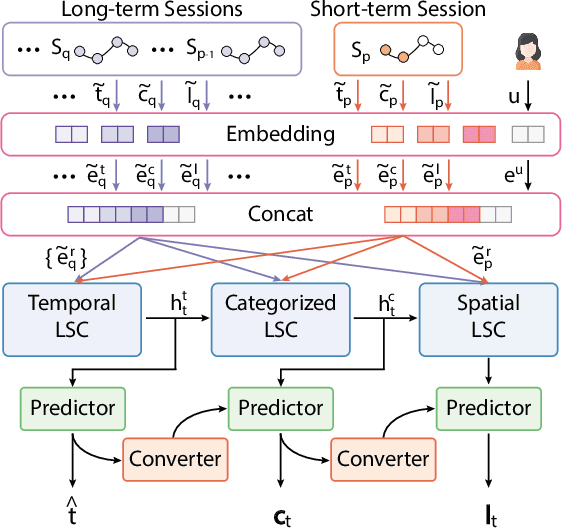
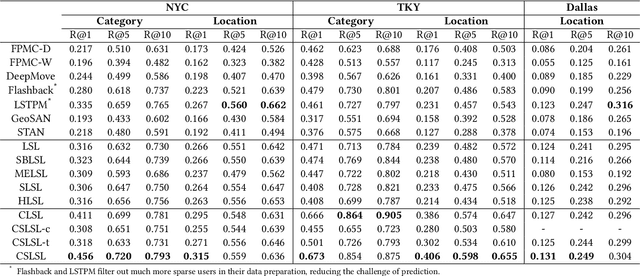
Modeling human mobility helps to understand how people are accessing resources and physically contacting with each other in cities, and thus contributes to various applications such as urban planning, epidemic control, and location-based advertisement. Next location prediction is one decisive task in individual human mobility modeling and is usually viewed as sequence modeling, solved with Markov or RNN-based methods. However, the existing models paid little attention to the logic of individual travel decisions and the reproducibility of the collective behavior of population. To this end, we propose a Causal and Spatial-constrained Long and Short-term Learner (CSLSL) for next location prediction. CSLSL utilizes a causal structure based on multi-task learning to explicitly model the "when$\rightarrow$what$\rightarrow$where", a.k.a. "time$\rightarrow$activity$\rightarrow$location" decision logic. We next propose a spatial-constrained loss function as an auxiliary task, to ensure the consistency between the predicted and actual spatial distribution of travelers' destinations. Moreover, CSLSL adopts modules named Long and Short-term Capturer (LSC) to learn the transition regularities across different time spans. Extensive experiments on three real-world datasets show a 33.4% performance improvement of CSLSL over baselines and confirm the effectiveness of introducing the causality and consistency constraints. The implementation is available at https://github.com/urbanmobility/CSLSL.
MP2: A Momentum Contrast Approach for Recommendation with Pointwise and Pairwise Learning
Apr 18, 2022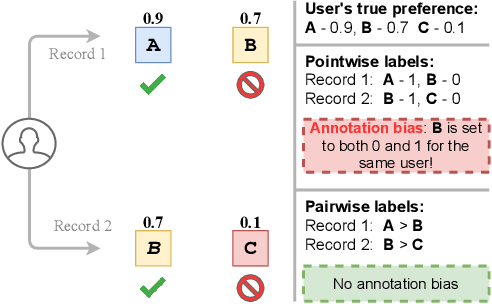
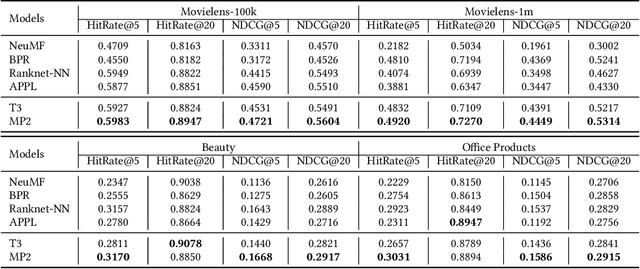
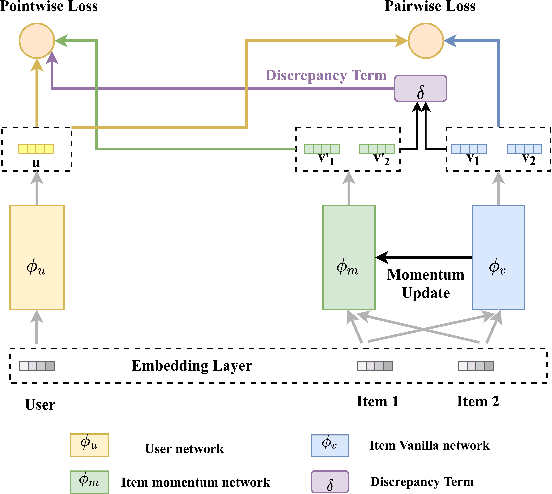
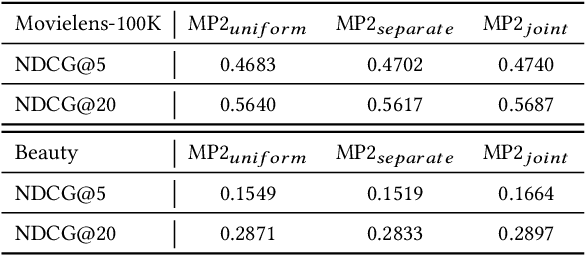
Binary pointwise labels (aka implicit feedback) are heavily leveraged by deep learning based recommendation algorithms nowadays. In this paper we discuss the limited expressiveness of these labels may fail to accommodate varying degrees of user preference, and thus lead to conflicts during model training, which we call annotation bias. To solve this issue, we find the soft-labeling property of pairwise labels could be utilized to alleviate the bias of pointwise labels. To this end, we propose a momentum contrast framework (MP2) that combines pointwise and pairwise learning for recommendation. MP2 has a three-tower network structure: one user network and two item networks. The two item networks are used for computing pointwise and pairwise loss respectively. To alleviate the influence of the annotation bias, we perform a momentum update to ensure a consistent item representation. Extensive experiments on real-world datasets demonstrate the superiority of our method against state-of-the-art recommendation algorithms.
Learning to Hash Naturally Sorts
Jan 31, 2022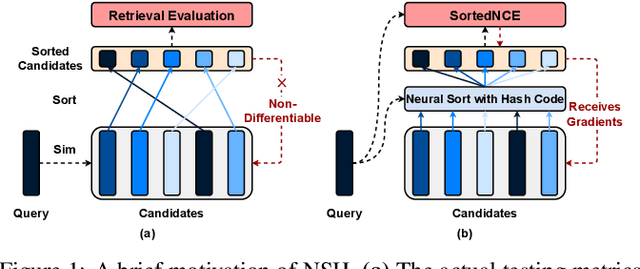
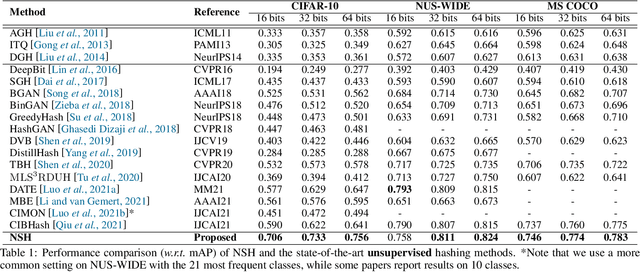
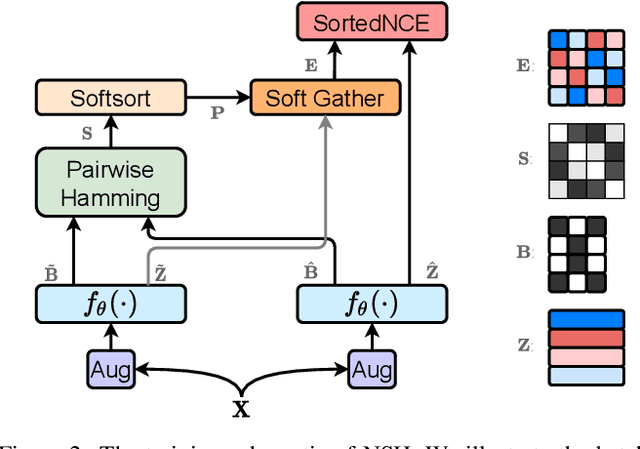
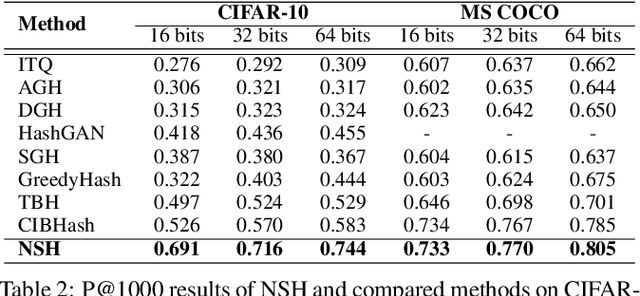
Locality sensitive hashing pictures a list-wise sorting problem. Its testing metrics, e.g., mean-average precision, count on a sorted candidate list ordered by pair-wise code similarity. However, scarcely does one train a deep hashing model with the sorted results end-to-end because of the non-differentiable nature of the sorting operation. This inconsistency in the objectives of training and test may lead to sub-optimal performance since the training loss often fails to reflect the actual retrieval metric. In this paper, we tackle this problem by introducing Naturally-Sorted Hashing (NSH). We sort the Hamming distances of samples' hash codes and accordingly gather their latent representations for self-supervised training. Thanks to the recent advances in differentiable sorting approximations, the hash head receives gradients from the sorter so that the hash encoder can be optimized along with the training procedure. Additionally, we describe a novel Sorted Noise-Contrastive Estimation (SortedNCE) loss that selectively picks positive and negative samples for contrastive learning, which allows NSH to mine data semantic relations during training in an unsupervised manner. Our extensive experiments show the proposed NSH model significantly outperforms the existing unsupervised hashing methods on three benchmarked datasets.
You Never Cluster Alone
Jun 03, 2021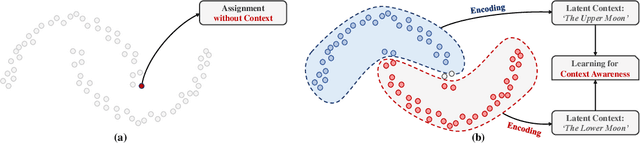
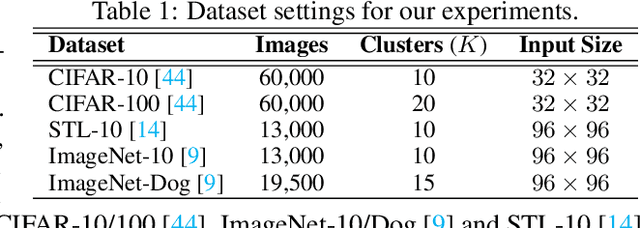
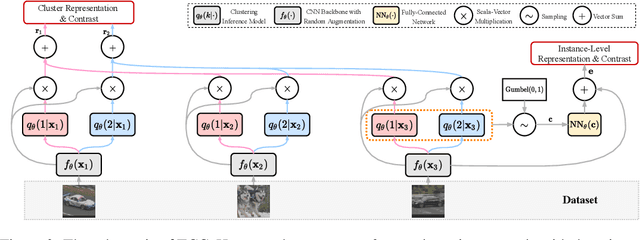
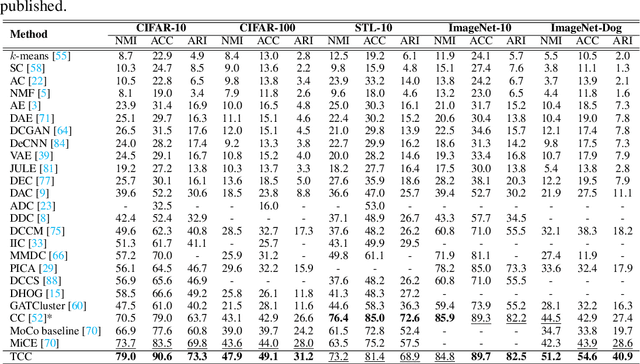
Recent advances in self-supervised learning with instance-level contrastive objectives facilitate unsupervised clustering. However, a standalone datum is not perceiving the context of the holistic cluster, and may undergo sub-optimal assignment. In this paper, we extend the mainstream contrastive learning paradigm to a cluster-level scheme, where all the data subjected to the same cluster contribute to a unified representation that encodes the context of each data group. Contrastive learning with this representation then rewards the assignment of each datum. To implement this vision, we propose twin-contrast clustering (TCC). We define a set of categorical variables as clustering assignment confidence, which links the instance-level learning track with the cluster-level one. On one hand, with the corresponding assignment variables being the weight, a weighted aggregation along the data points implements the set representation of a cluster. We further propose heuristic cluster augmentation equivalents to enable cluster-level contrastive learning. On the other hand, we derive the evidence lower-bound of the instance-level contrastive objective with the assignments. By reparametrizing the assignment variables, TCC is trained end-to-end, requiring no alternating steps. Extensive experiments show that TCC outperforms the state-of-the-art on challenging benchmarks.
M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems
Jun 01, 2020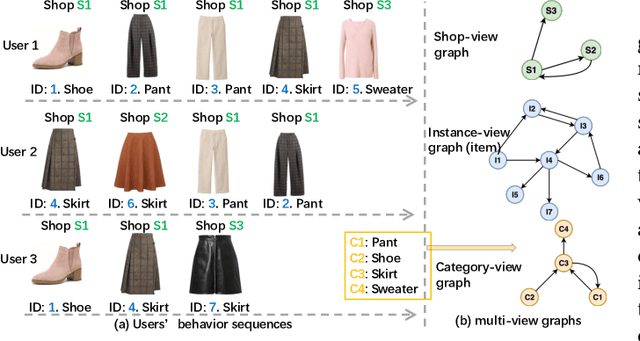

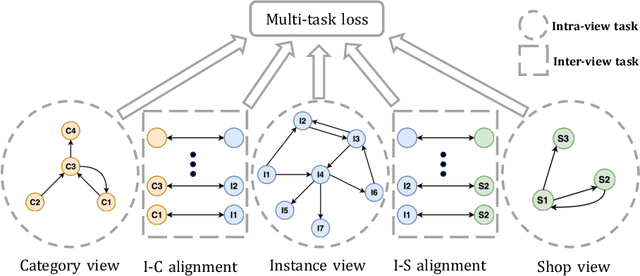
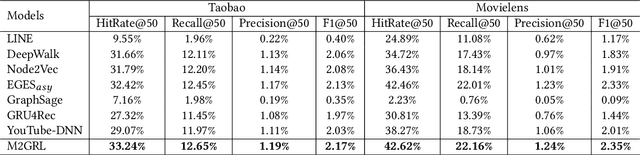
Combining graph representation learning with multi-view data (side information) for recommendation is a trend in industry. Most existing methods can be categorized as \emph{multi-view representation fusion}; they first build one graph and then integrate multi-view data into a single compact representation for each node in the graph. However, these methods are raising concerns in both engineering and algorithm aspects: 1) multi-view data are abundant and informative in industry and may exceed the capacity of one single vector, and 2) inductive bias may be introduced as multi-view data are often from different distributions. In this paper, we use a \emph{multi-view representation alignment} approach to address this issue. Particularly, we propose a multi-task multi-view graph representation learning framework (M2GRL) to learn node representations from multi-view graphs for web-scale recommender systems. M2GRL constructs one graph for each single-view data, learns multiple separate representations from multiple graphs, and performs alignment to model cross-view relations. M2GRL chooses a multi-task learning paradigm to learn intra-view representations and cross-view relations jointly. Besides, M2GRL applies homoscedastic uncertainty to adaptively tune the loss weights of tasks during training. We deploy M2GRL at Taobao and train it on 57 billion examples. According to offline metrics and online A/B tests, M2GRL significantly outperforms other state-of-the-art algorithms. Further exploration on diversity recommendation in Taobao shows the effectiveness of utilizing multiple representations produced by \method{}, which we argue is a promising direction for various industrial recommendation tasks of different focus.
Tracing the Propagation Path: A Flow Perspective of Representation Learning on Graphs
Dec 12, 2019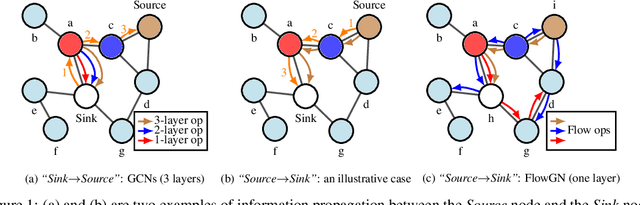

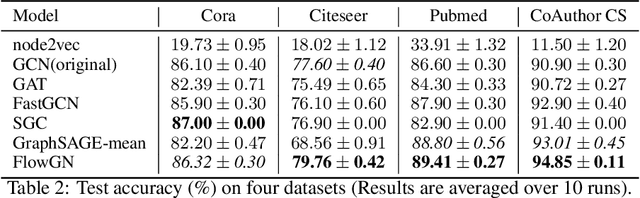
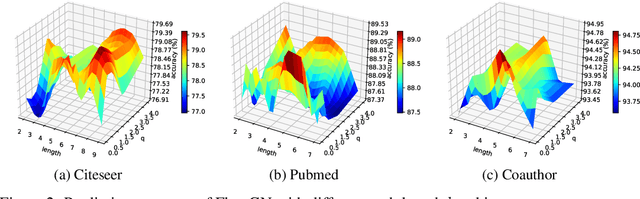
Graph Convolutional Networks (GCNs) have gained significant developments in representation learning on graphs. However, current GCNs suffer from two common challenges: 1) GCNs are only effective with shallow structures; stacking multiple GCN layers will lead to over-smoothing. 2) GCNs do not scale well with large, dense graphs due to the recursive neighborhood expansion. We generalize the propagation strategies of current GCNs as a \emph{"Sink$\to$Source"} mode, which seems to be an underlying cause of the two challenges. To address these issues intrinsically, in this paper, we study the information propagation mechanism in a \emph{"Source$\to$Sink"} mode. We introduce a new concept "information flow path" that explicitly defines where information originates and how it diffuses. Then a novel framework, namely Flow Graph Network (FlowGN), is proposed to learn node representations. FlowGN is computationally efficient and flexible in propagation strategies. Moreover, FlowGN decouples the layer structure from the information propagation process, removing the interior constraint of applying deep structures in traditional GCNs. Further experiments on public datasets demonstrate the superiority of FlowGN against state-of-the-art GCNs.