 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Contrastive Hashing
Sep 28, 2022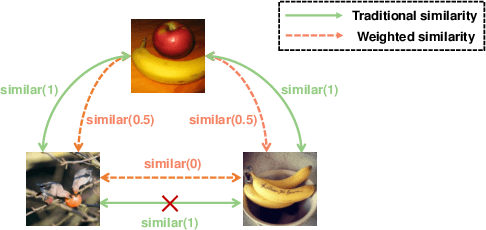
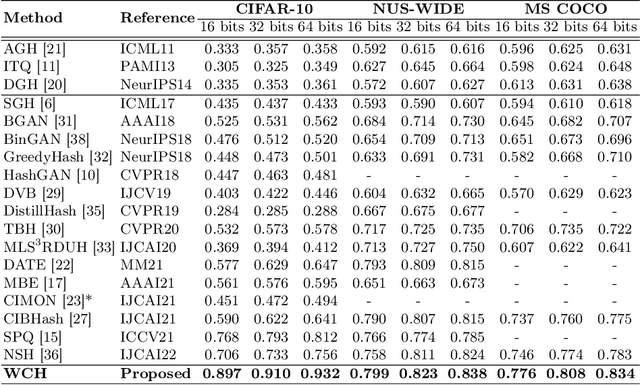
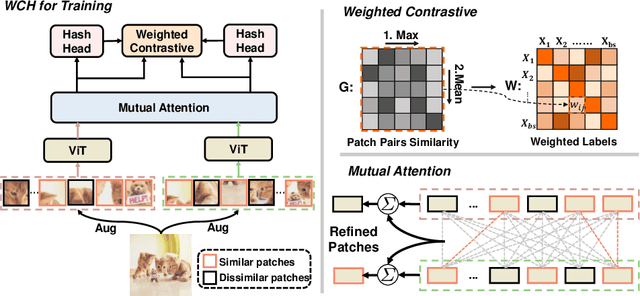
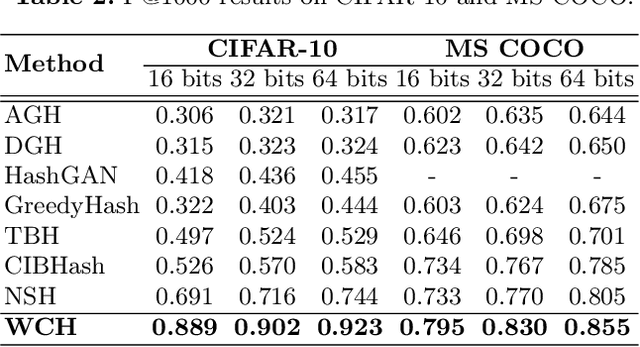
The development of unsupervised hashing is advanced by the recent popular contrastive learning paradigm. However, previous contrastive learning-based works have been hampered by (1) insufficient data similarity mining based on global-only image representations, and (2) the hash code semantic loss caused by the data augmentation. In this paper, we propose a novel method, namely Weighted Contrative Hashing (WCH), to take a step towards solving these two problems. We introduce a novel mutual attention module to alleviate the problem of information asymmetry in network features caused by the missing image structure during contrative augmentation. Furthermore, we explore the fine-grained semantic relations between images, i.e., we divide the images into multiple patches and calculate similarities between patches. The aggregated weighted similarities, which reflect the deep image relations, are distilled to facilitate the hash codes learning with a distillation loss, so as to obtain better retrieval performance. Extensive experiments show that the proposed WCH significantly outperforms existing unsupervised hashing methods on three benchmark datasets.
Learning to Hash Naturally Sorts
Jan 31, 2022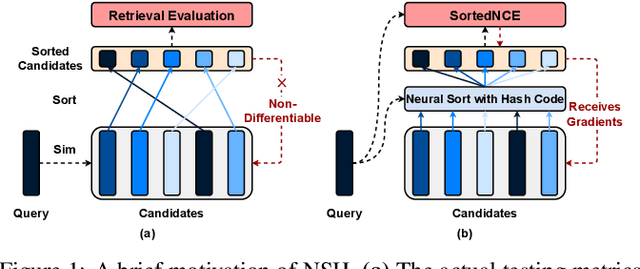
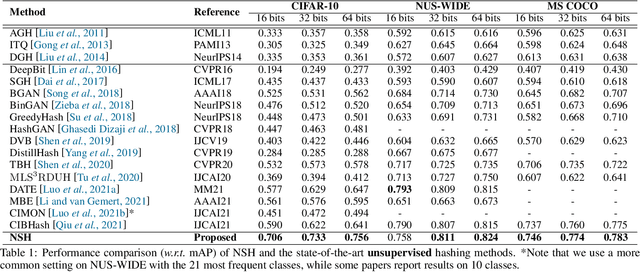
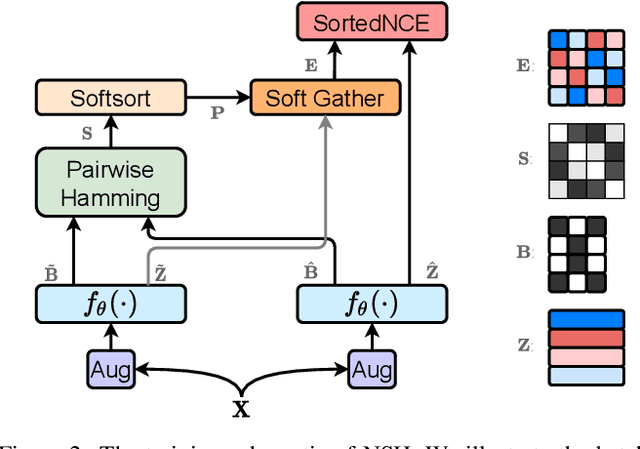
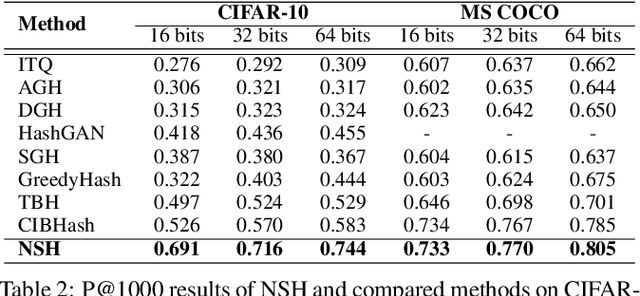
Locality sensitive hashing pictures a list-wise sorting problem. Its testing metrics, e.g., mean-average precision, count on a sorted candidate list ordered by pair-wise code similarity. However, scarcely does one train a deep hashing model with the sorted results end-to-end because of the non-differentiable nature of the sorting operation. This inconsistency in the objectives of training and test may lead to sub-optimal performance since the training loss often fails to reflect the actual retrieval metric. In this paper, we tackle this problem by introducing Naturally-Sorted Hashing (NSH). We sort the Hamming distances of samples' hash codes and accordingly gather their latent representations for self-supervised training. Thanks to the recent advances in differentiable sorting approximations, the hash head receives gradients from the sorter so that the hash encoder can be optimized along with the training procedure. Additionally, we describe a novel Sorted Noise-Contrastive Estimation (SortedNCE) loss that selectively picks positive and negative samples for contrastive learning, which allows NSH to mine data semantic relations during training in an unsupervised manner. Our extensive experiments show the proposed NSH model significantly outperforms the existing unsupervised hashing methods on three benchmarked datasets.