 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 The First Challenge on Holistic Quality Assessment for 4D World Model (PhyScore)
May 06, 2026This paper reports on the LoViF 2026 PhyScore challenge, a competition on holistic quality assessment of world-model-generated videos across both 2D and 4D generation settings. The challenge is motivated by a central gap in current evaluation practice: perceptual quality alone is insufficient to judge whether generated dynamics are physically plausible, temporally coherent, and consistent with input conditions. Participants are required to build a metric that jointly predicts four dimensions, i.e., Video Quality, Physical Realism, Condition-Video Alignment, and Temporal Consistency. Depart from that, participants also need to localize physical anomaly timestamps for fine-grained diagnosis. The benchmark dataset contains 1,554 videos generated by seven representative world generative models, organized into three tracks (text-2D, image-to-4D, and video-to-4D) and spanning 26 categories. These categories explicitly cover physics-relevant scenarios, including dynamics, optics, and thermodynamics, together with diverse real-world and creative content. To ensure label reliability, scores and anomaly timestamps are produced through trained human annotation with an additional automated quality-control pass. Evaluation is based on both score prediction and anomaly localization, with a composite protocol that combines TimeStamp_IOU and SRCC/PLCC. This report summarizes the challenge design and provides method-level insights from submitted solutions.
OccDirector: Language-Guided Behavior and Interaction Generation in 4D Occupancy Space
Apr 24, 2026Generative world models increasingly rely on 4D occupancy for realistic autonomous driving simulation. However, existing generation frameworks depend on rigid geometric conditions (e.g., explicit trajectories) or simplistic attribute-level text, failing to orchestrate complex, sequential multi-agent interactions. To address this semantic-spatiotemporal gap, we propose OccDirector, a pioneering framework that generates 4D occupancy dynamics conditioned solely on natural language. Operating as a ``scenario director'', OccDirector maps natural language scripts into physically plausible voxel dynamics without requiring geometric priors. Technically, it employs a VLM-driven Spatio-Temporal MMDiT equipped with a history-prefix anchoring strategy to ensure long-horizon interaction consistency. Furthermore, we introduce OccInteract-85k, a novel dataset uniquely annotated with multi-level language instructions: ranging from static layouts to intricate multi-agent behaviors, alongside a novel VLM-based evaluation benchmark. Extensive experiments demonstrate that OccDirector achieves state-of-the-art generation quality and unprecedented instruction-following capabilities, successfully shifting the paradigm from appearance synthesis to language-driven behavior orchestration.
Multimodal Large Language Models for Multi-Subject In-Context Image Generation
Apr 08, 2026Recent advances in text-to-image (T2I) generation have enabled visually coherent image synthesis from descriptions, but generating images containing multiple given subjects remains challenging. As the number of reference identities increases, existing methods often suffer from subject missing and semantic drift. To address this problem, we propose MUSIC, the first MLLM specifically designed for \textbf{MU}lti-\textbf{S}ubject \textbf{I}n-\textbf{C}ontext image generation. To overcome the data scarcity, we introduce an automatic and scalable data generation pipeline that eliminates the need for manual annotation. Furthermore, we enhance the model's understanding of multi-subject semantic relationships through a vision chain-of-thought (CoT) mechanism, guiding step-by-step reasoning from subject images to semantics and generation. To mitigate identity entanglement and manage visual complexity, we develop a novel semantics-driven spatial layout planning method and demonstrate its test-time scalability. By incorporating complex subject images during training, we improve the model's capacity for chained reasoning. In addition, we curate MSIC, a new benchmark tailored for multi-subject in-context generation. Experimental results demonstrate that MUSIC significantly surpasses other methods in both multi- and single-subject scenarios.
Clinical Cognition Alignment for Gastrointestinal Diagnosis with Multimodal LLMs
Mar 21, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable potential in medical image analysis. However, their application in gastrointestinal endoscopy is currently hindered by two critical limitations: the misalignment between general model reasoning and standardized clinical cognitive pathways, and the lack of causal association between visual features and diagnostic outcomes. In this paper, we propose a novel Clinical-Cognitive-Aligned (CogAlign) framework to address these challenges. First, we endow the model with rigorous clinical analytical capabilities by constructing the hierarchical clinical cognition dataset and employing Supervised Fine-Tuning (SFT). Unlike conventional approaches, this strategy internalizes the hierarchical diagnostic logic of experts, ranging from anatomical localization and morphological evaluation to microvascular analysis, directly into the model. Second, to eliminate visual bias, we provide a theoretical analysis demonstrating that standard supervised tuning inevitably converges to spurious background correlations. Guided by this insight, we propose a counterfactual-driven reinforcement learning strategy to enforce causal rectification. By generating counterfactual normal samples via lesion masking and optimizing through clinical-cognition-centric rewards, we constrain the model to strictly ground its diagnosis in causal lesion features. Extensive experiments demonstrate that our approach achieves State-of-the-Art (SoTA) performance across multiple benchmarks, significantly enhancing diagnostic accuracy in complex clinical scenarios. All source code and datasets will be made publicly available.
From Human Intention to Action Prediction: A Comprehensive Benchmark for Intention-driven End-to-End Autonomous Driving
Dec 13, 2025Current end-to-end autonomous driving systems operate at a level of intelligence akin to following simple steering commands. However, achieving genuinely intelligent autonomy requires a paradigm shift: moving from merely executing low-level instructions to understanding and fulfilling high-level, abstract human intentions. This leap from a command-follower to an intention-fulfiller, as illustrated in our conceptual framework, is hindered by a fundamental challenge: the absence of a standardized benchmark to measure and drive progress on this complex task. To address this critical gap, we introduce Intention-Drive, the first comprehensive benchmark designed to evaluate the ability to translate high-level human intent into safe and precise driving actions. Intention-Drive features two core contributions: (1) a new dataset of complex scenarios paired with corresponding natural language intentions, and (2) a novel evaluation protocol centered on the Intent Success Rate (ISR), which assesses the semantic fulfillment of the human's goal beyond simple geometric accuracy. Through an extensive evaluation of a spectrum of baseline models on Intention-Drive, we reveal a significant performance deficit, showing that the baseline model struggle to achieve the comprehensive scene and intention understanding required for this advanced task.
Semantic Causality-Aware Vision-Based 3D Occupancy Prediction
Sep 10, 2025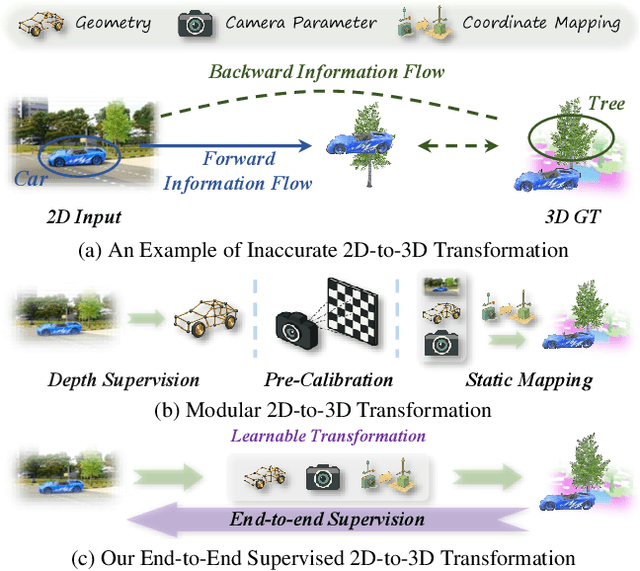

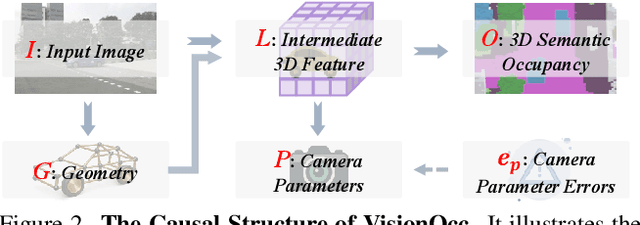
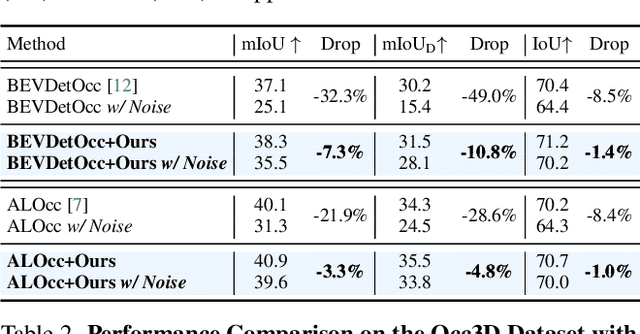
Vision-based 3D semantic occupancy prediction is a critical task in 3D vision that integrates volumetric 3D reconstruction with semantic understanding. Existing methods, however, often rely on modular pipelines. These modules are typically optimized independently or use pre-configured inputs, leading to cascading errors. In this paper, we address this limitation by designing a novel causal loss that enables holistic, end-to-end supervision of the modular 2D-to-3D transformation pipeline. Grounded in the principle of 2D-to-3D semantic causality, this loss regulates the gradient flow from 3D voxel representations back to the 2D features. Consequently, it renders the entire pipeline differentiable, unifying the learning process and making previously non-trainable components fully learnable. Building on this principle, we propose the Semantic Causality-Aware 2D-to-3D Transformation, which comprises three components guided by our causal loss: Channel-Grouped Lifting for adaptive semantic mapping, Learnable Camera Offsets for enhanced robustness against camera perturbations, and Normalized Convolution for effective feature propagation. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the Occ3D benchmark, demonstrating significant robustness to camera perturbations and improved 2D-to-3D semantic consistency.
Rethinking Temporal Fusion with a Unified Gradient Descent View for 3D Semantic Occupancy Prediction
Apr 18, 2025We present GDFusion, a temporal fusion method for vision-based 3D semantic occupancy prediction (VisionOcc). GDFusion opens up the underexplored aspects of temporal fusion within the VisionOcc framework, focusing on both temporal cues and fusion strategies. It systematically examines the entire VisionOcc pipeline, identifying three fundamental yet previously overlooked temporal cues: scene-level consistency, motion calibration, and geometric complementation. These cues capture diverse facets of temporal evolution and make distinct contributions across various modules in the VisionOcc framework. To effectively fuse temporal signals across heterogeneous representations, we propose a novel fusion strategy by reinterpreting the formulation of vanilla RNNs. This reinterpretation leverages gradient descent on features to unify the integration of diverse temporal information, seamlessly embedding the proposed temporal cues into the network. Extensive experiments on nuScenes demonstrate that GDFusion significantly outperforms established baselines. Notably, on Occ3D benchmark, it achieves 1.4\%-4.8\% mIoU improvements and reduces memory consumption by 27\%-72\%.
ALOcc: Adaptive Lifting-based 3D Semantic Occupancy and Cost Volume-based Flow Prediction
Nov 12, 2024Vision-based semantic occupancy and flow prediction plays a crucial role in providing spatiotemporal cues for real-world tasks, such as autonomous driving. Existing methods prioritize higher accuracy to cater to the demands of these tasks. In this work, we strive to improve performance by introducing a series of targeted improvements for 3D semantic occupancy prediction and flow estimation. First, we introduce an occlusion-aware adaptive lifting mechanism with a depth denoising technique to improve the robustness of 2D-to-3D feature transformation and reduce the reliance on depth priors. Second, we strengthen the semantic consistency between 3D features and their original 2D modalities by utilizing shared semantic prototypes to jointly constrain both 2D and 3D features. This is complemented by confidence- and category-based sampling strategies to tackle long-tail challenges in 3D space. To alleviate the feature encoding burden in the joint prediction of semantics and flow, we propose a BEV cost volume-based prediction method that links flow and semantic features through a cost volume and employs a classification-regression supervision scheme to address the varying flow scales in dynamic scenes. Our purely convolutional architecture framework, named ALOcc, achieves an optimal tradeoff between speed and accuracy achieving state-of-the-art results on multiple benchmarks. On Occ3D and training without the camera visible mask, our ALOcc achieves an absolute gain of 2.5\% in terms of RayIoU while operating at a comparable speed compared to the state-of-the-art, using the same input size (256$\times$704) and ResNet-50 backbone. Our method also achieves 2nd place in the CVPR24 Occupancy and Flow Prediction Competition.
AdaOcc: Adaptive Forward View Transformation and Flow Modeling for 3D Occupancy and Flow Prediction
Jul 01, 2024



In this technical report, we present our solution for the Vision-Centric 3D Occupancy and Flow Prediction track in the nuScenes Open-Occ Dataset Challenge at CVPR 2024. Our innovative approach involves a dual-stage framework that enhances 3D occupancy and flow predictions by incorporating adaptive forward view transformation and flow modeling. Initially, we independently train the occupancy model, followed by flow prediction using sequential frame integration. Our method combines regression with classification to address scale variations in different scenes, and leverages predicted flow to warp current voxel features to future frames, guided by future frame ground truth. Experimental results on the nuScenes dataset demonstrate significant improvements in accuracy and robustness, showcasing the effectiveness of our approach in real-world scenarios. Our single model based on Swin-Base ranks second on the public leaderboard, validating the potential of our method in advancing autonomous car perception systems.
Evolutionary Generalized Zero-Shot Learning
Nov 23, 2022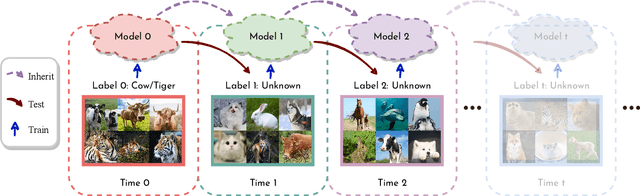
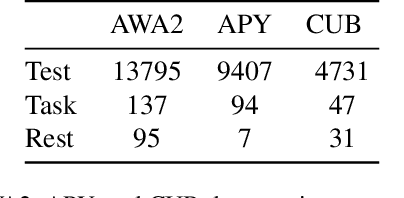
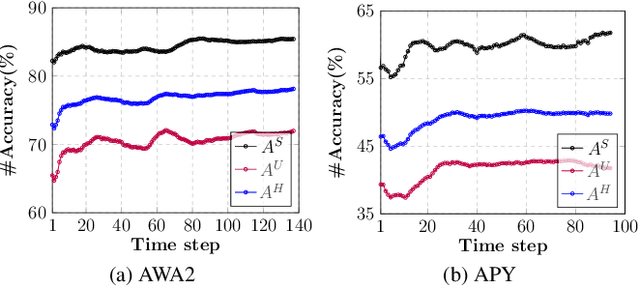
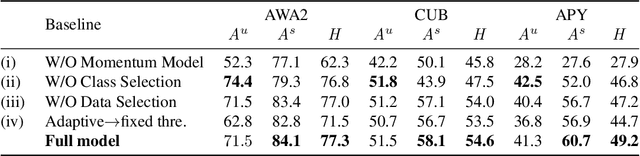
An open problem on the path to artificial intelligence is generalization from the known to the unknown, which is instantiated as Generalized Zero-Shot Learning (GZSL) task. In this work, we propose a novel Evolutionary Generalized Zero-Shot Learning setting, which (i) avoids the domain shift problem in inductive GZSL, and (ii) is more in line with the needs of real-world deployments than transductive GZSL. In the proposed setting, a zero-shot model with poor initial performance is able to achieve online evolution during application. We elaborate on three challenges of this special task, i.e., catastrophic forgetting, initial prediction bias, and evolutionary data class bias. Moreover, we propose targeted solutions for each challenge, resulting in a generic method capable of continuing to evolve on a given initial IGZSL model. Experiments on three popular GZSL benchmark datasets show that our model can learn from the test data stream while other baselines fail.