 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Causality-Aware Vision-Based 3D Occupancy Prediction
Sep 10, 2025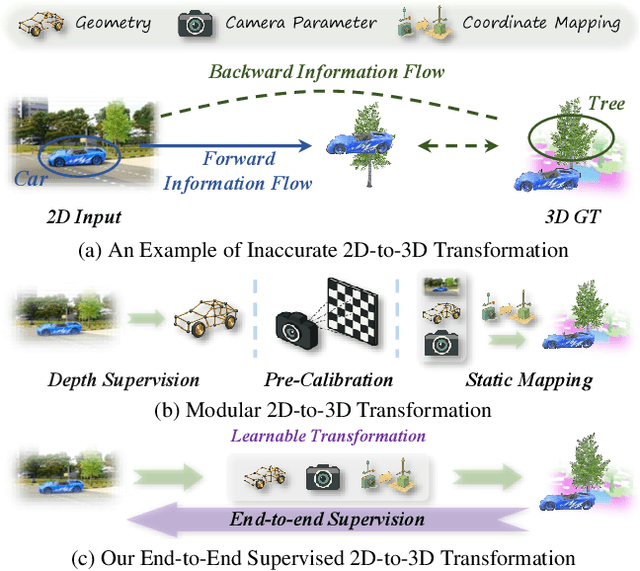

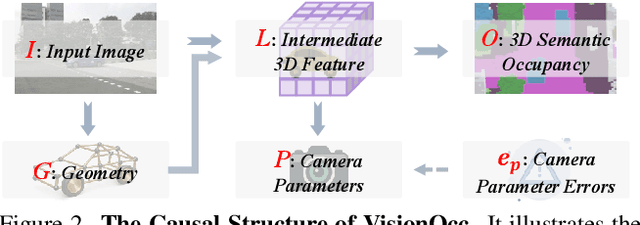
Vision-based 3D semantic occupancy prediction is a critical task in 3D vision that integrates volumetric 3D reconstruction with semantic understanding. Existing methods, however, often rely on modular pipelines. These modules are typically optimized independently or use pre-configured inputs, leading to cascading errors. In this paper, we address this limitation by designing a novel causal loss that enables holistic, end-to-end supervision of the modular 2D-to-3D transformation pipeline. Grounded in the principle of 2D-to-3D semantic causality, this loss regulates the gradient flow from 3D voxel representations back to the 2D features. Consequently, it renders the entire pipeline differentiable, unifying the learning process and making previously non-trainable components fully learnable. Building on this principle, we propose the Semantic Causality-Aware 2D-to-3D Transformation, which comprises three components guided by our causal loss: Channel-Grouped Lifting for adaptive semantic mapping, Learnable Camera Offsets for enhanced robustness against camera perturbations, and Normalized Convolution for effective feature propagation. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the Occ3D benchmark, demonstrating significant robustness to camera perturbations and improved 2D-to-3D semantic consistency.
Rethinking Temporal Fusion with a Unified Gradient Descent View for 3D Semantic Occupancy Prediction
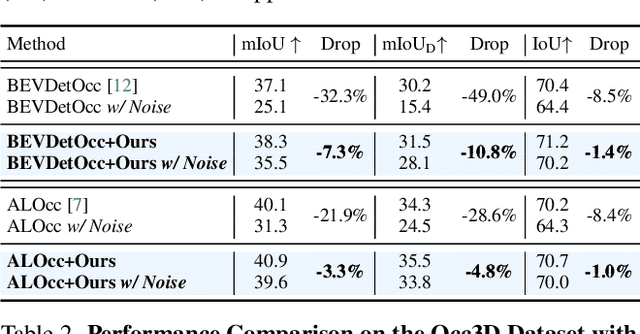
Apr 18, 2025We present GDFusion, a temporal fusion method for vision-based 3D semantic occupancy prediction (VisionOcc). GDFusion opens up the underexplored aspects of temporal fusion within the VisionOcc framework, focusing on both temporal cues and fusion strategies. It systematically examines the entire VisionOcc pipeline, identifying three fundamental yet previously overlooked temporal cues: scene-level consistency, motion calibration, and geometric complementation. These cues capture diverse facets of temporal evolution and make distinct contributions across various modules in the VisionOcc framework. To effectively fuse temporal signals across heterogeneous representations, we propose a novel fusion strategy by reinterpreting the formulation of vanilla RNNs. This reinterpretation leverages gradient descent on features to unify the integration of diverse temporal information, seamlessly embedding the proposed temporal cues into the network. Extensive experiments on nuScenes demonstrate that GDFusion significantly outperforms established baselines. Notably, on Occ3D benchmark, it achieves 1.4\%-4.8\% mIoU improvements and reduces memory consumption by 27\%-72\%.
You Only Click Once: Single Point Weakly Supervised 3D Instance Segmentation for Autonomous Driving
Feb 28, 2025Outdoor LiDAR point cloud 3D instance segmentation is a crucial task in autonomous driving. However, it requires laborious human efforts to annotate the point cloud for training a segmentation model. To address this challenge, we propose a YoCo framework, which generates 3D pseudo labels using minimal coarse click annotations in the bird's eye view plane. It is a significant challenge to produce high-quality pseudo labels from sparse annotations. Our YoCo framework first leverages vision foundation models combined with geometric constraints from point clouds to enhance pseudo label generation. Second, a temporal and spatial-based label updating module is designed to generate reliable updated labels. It leverages predictions from adjacent frames and utilizes the inherent density variation of point clouds (dense near, sparse far). Finally, to further improve label quality, an IoU-guided enhancement module is proposed, replacing pseudo labels with high-confidence and high-IoU predictions. Experiments on the Waymo dataset demonstrate YoCo's effectiveness and generality, achieving state-of-the-art performance among weakly supervised methods and surpassing fully supervised Cylinder3D. Additionally, the YoCo is suitable for various networks, achieving performance comparable to fully supervised methods with minimal fine-tuning using only 0.8% of the fully labeled data, significantly reducing annotation costs.
Know You First and Be You Better: Modeling Human-Like User Simulators via Implicit Profiles
Feb 26, 2025User simulators are crucial for replicating human interactions with dialogue systems, supporting both collaborative training and automatic evaluation, especially for large language models (LLMs). However, existing simulators often rely solely on text utterances, missing implicit user traits such as personality, speaking style, and goals. In contrast, persona-based methods lack generalizability, as they depend on predefined profiles of famous individuals or archetypes. To address these challenges, we propose User Simulator with implicit Profiles (USP), a framework that infers implicit user profiles from human-machine conversations and uses them to generate more personalized and realistic dialogues. We first develop an LLM-driven extractor with a comprehensive profile schema. Then, we refine the simulation through conditional supervised fine-tuning and reinforcement learning with cycle consistency, optimizing it at both the utterance and conversation levels. Finally, we adopt a diverse profile sampler to capture the distribution of real-world user profiles. Experimental results demonstrate that USP outperforms strong baselines in terms of authenticity and diversity while achieving comparable performance in consistency. Furthermore, dynamic multi-turn evaluations based on USP strongly align with mainstream benchmarks, demonstrating its effectiveness in real-world applications.
Generative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
Jan 15, 2025



Autonomous driving is a challenging task that requires perceiving and understanding the surrounding environment for safe trajectory planning. While existing vision-based end-to-end models have achieved promising results, these methods are still facing the challenges of vision understanding, decision reasoning and scene generalization. To solve these issues, a generative planning with 3D-vision language pre-training model named GPVL is proposed for end-to-end autonomous driving. The proposed paradigm has two significant aspects. On one hand, a 3D-vision language pre-training module is designed to bridge the gap between visual perception and linguistic understanding in the bird's eye view. On the other hand, a cross-modal language model is introduced to generate holistic driving decisions and fine-grained trajectories with perception and navigation information in an auto-regressive manner. Experiments on the challenging nuScenes dataset demonstrate that the proposed scheme achieves excellent performances compared with state-of-the-art methods. Besides, the proposed GPVL presents strong generalization ability and real-time potential when handling high-level commands in various scenarios. It is believed that the effective, robust and efficient performance of GPVL is crucial for the practical application of future autonomous driving systems. Code is available at https://github.com/ltp1995/GPVL
Open-Vocabulary Object Detection via Neighboring Region Attention Alignment
May 14, 2024



The nature of diversity in real-world environments necessitates neural network models to expand from closed category settings to accommodate novel emerging categories. In this paper, we study the open-vocabulary object detection (OVD), which facilitates the detection of novel object classes under the supervision of only base annotations and open-vocabulary knowledge. However, we find that the inadequacy of neighboring relationships between regions during the alignment process inevitably constrains the performance on recent distillation-based OVD strategies. To this end, we propose Neighboring Region Attention Alignment (NRAA), which performs alignment within the attention mechanism of a set of neighboring regions to boost the open-vocabulary inference. Specifically, for a given proposal region, we randomly explore the neighboring boxes and conduct our proposed neighboring region attention (NRA) mechanism to extract relationship information. Then, this interaction information is seamlessly provided into the distillation procedure to assist the alignment between the detector and the pre-trained vision-language models (VLMs). Extensive experiments validate that our proposed model exhibits superior performance on open-vocabulary benchmarks.