 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
Jan 15, 2025



Autonomous driving is a challenging task that requires perceiving and understanding the surrounding environment for safe trajectory planning. While existing vision-based end-to-end models have achieved promising results, these methods are still facing the challenges of vision understanding, decision reasoning and scene generalization. To solve these issues, a generative planning with 3D-vision language pre-training model named GPVL is proposed for end-to-end autonomous driving. The proposed paradigm has two significant aspects. On one hand, a 3D-vision language pre-training module is designed to bridge the gap between visual perception and linguistic understanding in the bird's eye view. On the other hand, a cross-modal language model is introduced to generate holistic driving decisions and fine-grained trajectories with perception and navigation information in an auto-regressive manner. Experiments on the challenging nuScenes dataset demonstrate that the proposed scheme achieves excellent performances compared with state-of-the-art methods. Besides, the proposed GPVL presents strong generalization ability and real-time potential when handling high-level commands in various scenarios. It is believed that the effective, robust and efficient performance of GPVL is crucial for the practical application of future autonomous driving systems. Code is available at https://github.com/ltp1995/GPVL
Taking an Emotional Look at Video Paragraph Captioning
Mar 12, 2022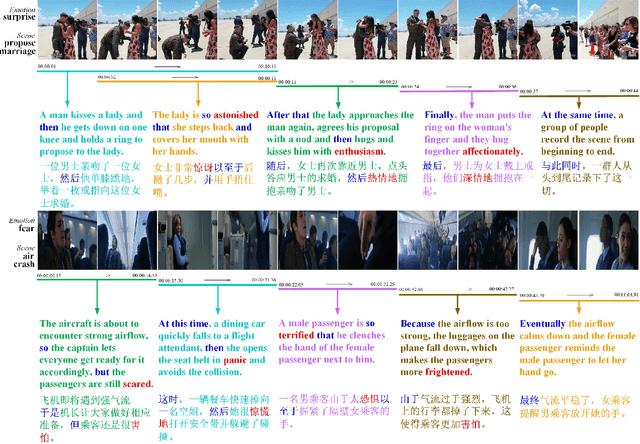
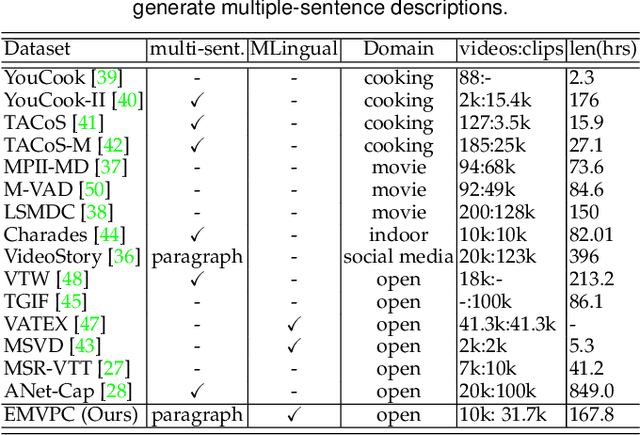
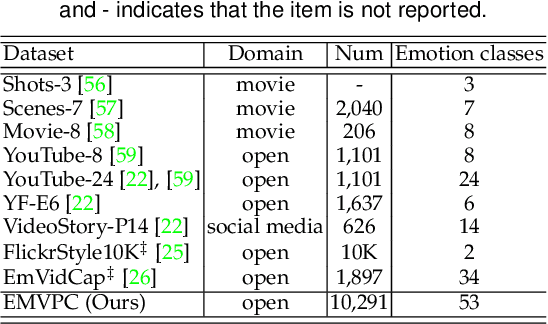
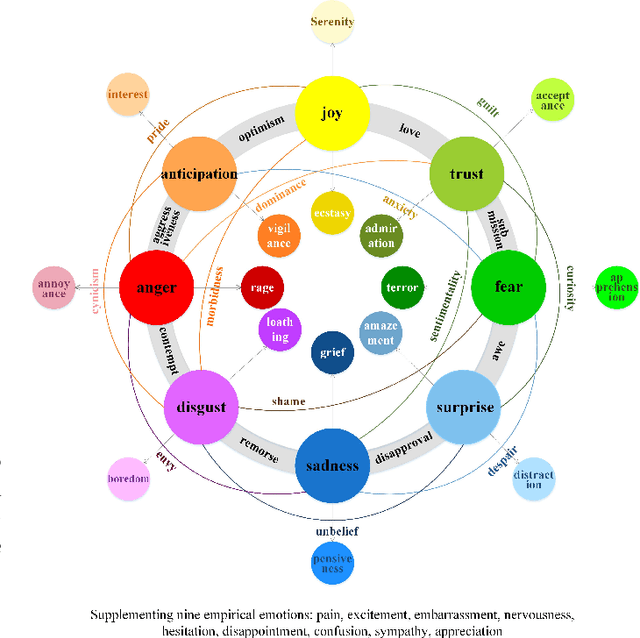
Translating visual data into natural language is essential for machines to understand the world and interact with humans. In this work, a comprehensive study is conducted on video paragraph captioning, with the goal to generate paragraph-level descriptions for a given video. However, current researches mainly focus on detecting objective facts, ignoring the needs to establish the logical associations between sentences and to discover more accurate emotions related to video contents. Such a problem impairs fluent and abundant expressions of predicted captions, which are far below human language tandards. To solve this problem, we propose to construct a large-scale emotion and logic driven multilingual dataset for this task. This dataset is named EMVPC (standing for "Emotional Video Paragraph Captioning") and contains 53 widely-used emotions in daily life, 376 common scenes corresponding to these emotions, 10,291 high-quality videos and 20,582 elaborated paragraph captions with English and Chinese versions. Relevant emotion categories, scene labels, emotion word labels and logic word labels are also provided in this new dataset. The proposed EMVPC dataset intends to provide full-fledged video paragraph captioning in terms of rich emotions, coherent logic and elaborate expressions, which can also benefit other tasks in vision-language fields. Furthermore, a comprehensive study is conducted through experiments on existing benchmark video paragraph captioning datasets and the proposed EMVPC. The stateof-the-art schemes from different visual captioning tasks are compared in terms of 15 popular metrics, and their detailed objective as well as subjective results are summarized. Finally, remaining problems and future directions of video paragraph captioning are also discussed. The unique perspective of this work is expected to boost further development in video paragraph captioning research.
Knowledge-enriched Attention Network with Group-wise Semantic for Visual Storytelling
Mar 10, 2022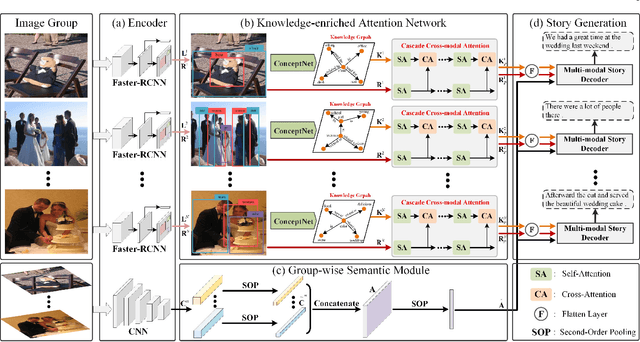
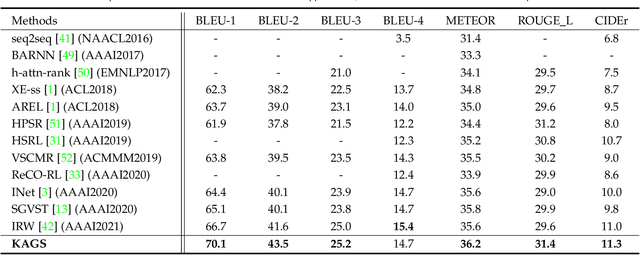
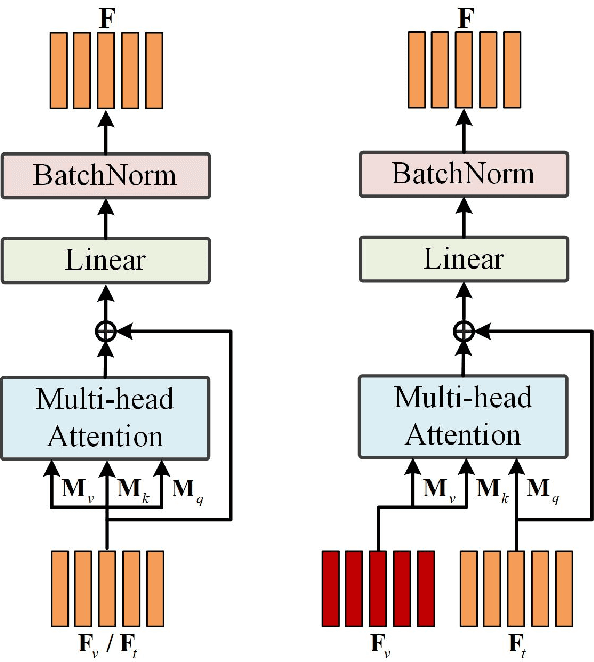
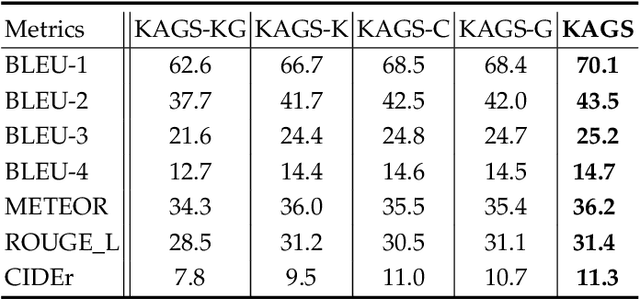
As a technically challenging topic, visual storytelling aims at generating an imaginary and coherent story with narrative multi-sentences from a group of relevant images. Existing methods often generate direct and rigid descriptions of apparent image-based contents, because they are not capable of exploring implicit information beyond images. Hence, these schemes could not capture consistent dependencies from holistic representation, impairing the generation of reasonable and fluent story. To address these problems, a novel knowledge-enriched attention network with group-wise semantic model is proposed. Three main novel components are designed and supported by substantial experiments to reveal practical advantages. First, a knowledge-enriched attention network is designed to extract implicit concepts from external knowledge system, and these concepts are followed by a cascade cross-modal attention mechanism to characterize imaginative and concrete representations. Second, a group-wise semantic module with second-order pooling is developed to explore the globally consistent guidance. Third, a unified one-stage story generation model with encoder-decoder structure is proposed to simultaneously train and infer the knowledge-enriched attention network, group-wise semantic module and multi-modal story generation decoder in an end-to-end fashion. Substantial experiments on the popular Visual Storytelling dataset with both objective and subjective evaluation metrics demonstrate the superior performance of the proposed scheme as compared with other state-of-the-art methods.
Re-thinking Co-Salient Object Detection
Jul 11, 2020

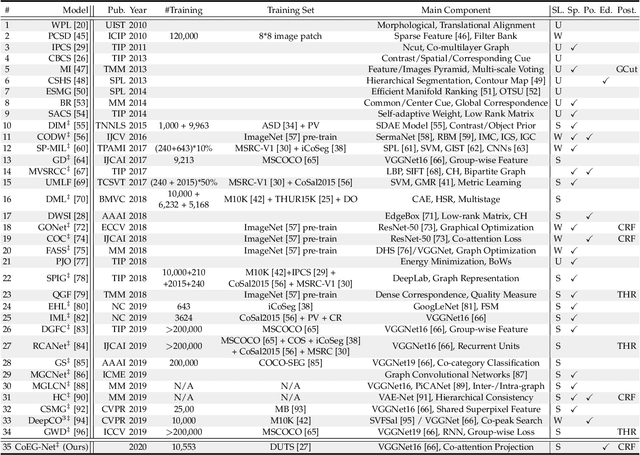

In this paper, we conduct a comprehensive study on the co-salient object detection (CoSOD) problem for images. CoSOD is an emerging and rapidly growing extension of salient object detection (SOD), which aims to detect the co-occurring salient objects in a group of images. However, existing CoSOD datasets often have a serious data bias, assuming that each group of images contains salient objects of similar visual appearances. This bias can lead to the ideal settings and effectiveness of models trained on existing datasets, being impaired in real-life situations, where similarities are usually semantic or conceptual. To tackle this issue, we first introduce a new benchmark, called CoSOD3k in the wild, which requires a large amount of semantic context, making it more challenging than existing CoSOD datasets. Our CoSOD3k consists of 3,316 high-quality, elaborately selected images divided into 160 groups with hierarchical annotations. The images span a wide range of categories, shapes, object sizes, and backgrounds. Second, we integrate the existing SOD techniques to build a unified, trainable CoSOD framework, which is long overdue in this field. Specifically, we propose a novel CoEG-Net that augments our prior model EGNet with a co-attention projection strategy to enable fast common information learning. CoEG-Net fully leverages previous large-scale SOD datasets and significantly improves the model scalability and stability. Third, we comprehensively summarize 34 cutting-edge algorithms, benchmarking 16 of them over three challenging CoSOD datasets (iCoSeg, CoSal2015, and our CoSOD3k), and reporting more detailed (i.e., group-level) performance analysis. Finally, we discuss the challenges and future works of CoSOD. We hope that our study will give a strong boost to growth in the CoSOD community
Adaptive Graph Convolutional Network with Attention Graph Clustering for Co-saliency Detection
Mar 13, 2020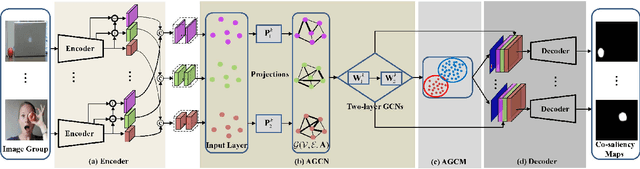

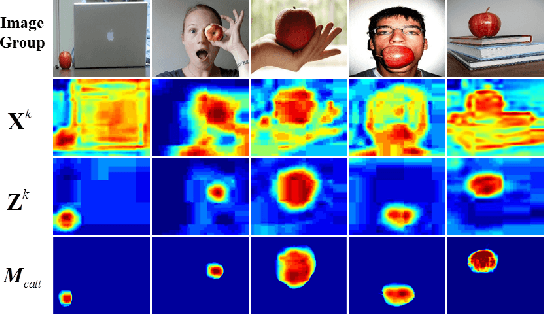
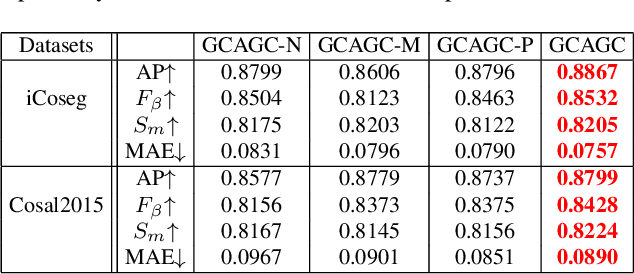
Co-saliency detection aims to discover the common and salient foregrounds from a group of relevant images. For this task, we present a novel adaptive graph convolutional network with attention graph clustering (GCAGC). Three major contributions have been made, and are experimentally shown to have substantial practical merits. First, we propose a graph convolutional network design to extract information cues to characterize the intra- and interimage correspondence. Second, we develop an attention graph clustering algorithm to discriminate the common objects from all the salient foreground objects in an unsupervised fashion. Third, we present a unified framework with encoder-decoder structure to jointly train and optimize the graph convolutional network, attention graph cluster, and co-saliency detection decoder in an end-to-end manner. We evaluate our proposed GCAGC method on three cosaliency detection benchmark datasets (iCoseg, Cosal2015 and COCO-SEG). Our GCAGC method obtains significant improvements over the state-of-the-arts on most of them.