 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROSClaw: A Hierarchical Semantic-Physical Framework for Heterogeneous Multi-Agent Collaboration
Apr 06, 2026The integration of large language models (LLMs) with embodied agents has improved high-level reasoning capabilities; however, a critical gap remains between semantic understanding and physical execution. While vision-language-action (VLA) and vision-language-navigation (VLN) systems enable robots to perform manipulation and navigation tasks from natural language instructions, they still struggle with long-horizon sequential and temporally structured tasks. Existing frameworks typically adopt modular pipelines for data collection, skill training, and policy deployment, resulting in high costs in experimental validation and policy optimization. To address these limitations, we propose ROSClaw, an agent framework for heterogeneous robots that integrates policy learning and task execution within a unified vision-language model (VLM) controller. The framework leverages e-URDF representations of heterogeneous robots as physical constraints to construct a sim-to-real topological mapping, enabling real-time access to the physical states of both simulated and real-world agents. We further incorporate a data collection and state accumulation mechanism that stores robot states, multimodal observations, and execution trajectories during real-world execution, enabling subsequent iterative policy optimization. During deployment, a unified agent maintains semantic continuity between reasoning and execution, and dynamically assigns task-specific control to different agents, thereby improving robustness in multi-policy execution. By establishing an autonomous closed-loop framework, ROSClaw minimizes the reliance on robot-specific development workflows. The framework supports hardware-level validation, automated generation of SDK-level control programs, and tool-based execution, enabling rapid cross-platform transfer and continual improvement of robotic skills. Ours project page: https://www.rosclaw.io/.
MorphoGuard: A Morphology-Based Whole-Body Interactive Motion Controller
Apr 02, 2026Whole-body control (WBC) has demonstrated significant advantages in complex interactive movements of high-dimensional robotic systems. However, when a robot is required to handle dynamic multi-contact combinations along a single kinematic chain-such as pushing open a door with its elbow while grasping an object-it faces major obstacles in terms of complex contact representation and joint configuration coupling. To address this, we propose a new control approach that explicitly manages arbitrary contact combinations, aiming to endow robots with whole-body interactive capabilities. We develop a morphology-constrained WBC network (MorphoGuard)-which is trained on a self-constructed dual-arm physical and simulation platform. A series of model recommendation experiments are designed to systematically investigate the impact of backbone architecture, fusion strategy, and model scale on network performance. To evaluate the control performance, we adopt a multi-object interaction task as the benchmark, requiring the model to simultaneously manipulate multiple target objects to specified positions. Experimental results show that the proposed method achieves a contact point management error of approximately 1 cm, demonstrating its effectiveness in whole-body interactive control.
Dual-Horizon Hybrid Internal Model for Low-Gravity Quadrupedal Jumping with Hardware-in-the-Loop Validation
Mar 09, 2026Locomotion under reduced gravity is commonly realized through jumping, yet continuous pronking in lunar gravity remains challenging due to prolonged flight phases and sparse ground contact. The extended aerial duration increases landing impact sensitivity and makes stable attitude regulation over rough planetary terrain difficult. Existing approaches primarily address single jumps on flat surfaces and lack both continuous-terrain solutions and realistic hardware validation. This work presents a Dual-Horizon Hybrid Internal Model for continuous quadrupedal jumping under lunar gravity using proprioceptive sensing only. Two temporal encoders capture complementary time scales: a short-horizon branch models rapid vertical dynamics with explicit vertical velocity estimation, while a long-horizon branch models horizontal motion trends and center-of-mass height evolution across the jump cycle. The fused representation enables stable and continuous jumping under extended aerial phases characteristic of lunar gravity. To provide hardware-in-the-loop validation, we develop the MATRIX (Mixed-reality Adaptive Testbed for Robotic Integrated eXploration) platform, a digital-twin-driven system that offloads gravity through a pulley-counterweight mechanism and maps Unreal Engine lunar terrain to a motion platform and treadmill in real time. Using MATRIX, we demonstrate continuous jumping of a quadruped robot under lunar-gravity emulation across cratered lunar-like terrain.
Morphogenetic Assembly and Adaptive Control for Heterogeneous Modular Robots
Feb 11, 2026This paper presents a closed-loop automation framework for heterogeneous modular robots, covering the full pipeline from morphological construction to adaptive control. In this framework, a mobile manipulator handles heterogeneous functional modules including structural, joint, and wheeled modules to dynamically assemble diverse robot configurations and provide them with immediate locomotion capability. To address the state-space explosion in large-scale heterogeneous reconfiguration, we propose a hierarchical planner: the high-level planner uses a bidirectional heuristic search with type-penalty terms to generate module-handling sequences, while the low level planner employs A* search to compute optimal execution trajectories. This design effectively decouples discrete configuration planning from continuous motion execution. For adaptive motion generation of unknown assembled configurations, we introduce a GPU accelerated Annealing-Variance Model Predictive Path Integral (MPPI) controller. By incorporating a multi stage variance annealing strategy to balance global exploration and local convergence, the controller enables configuration-agnostic, real-time motion control. Large scale simulations show that the type-penalty term is critical for planning robustness in heterogeneous scenarios. Moreover, the greedy heuristic produces plans with lower physical execution costs than the Hungarian heuristic. The proposed annealing-variance MPPI significantly outperforms standard MPPI in both velocity tracking accuracy and control frequency, achieving real time control at 50 Hz. The framework validates the full-cycle process, including module assembly, robot merging and splitting, and dynamic motion generation.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Data-driven solar forecasting enables near-optimal economic decisions
Sep 08, 2025Solar energy adoption is critical to achieving net-zero emissions. However, it remains difficult for many industrial and commercial actors to decide on whether they should adopt distributed solar-battery systems, which is largely due to the unavailability of fast, low-cost, and high-resolution irradiance forecasts. Here, we present SunCastNet, a lightweight data-driven forecasting system that provides 0.05$^\circ$, 10-minute resolution predictions of surface solar radiation downwards (SSRD) up to 7 days ahead. SunCastNet, coupled with reinforcement learning (RL) for battery scheduling, reduces operational regret by 76--93\% compared to robust decision making (RDM). In 25-year investment backtests, it enables up to five of ten high-emitting industrial sectors per region to cross the commercial viability threshold of 12\% Internal Rate of Return (IRR). These results show that high-resolution, long-horizon solar forecasts can directly translate into measurable economic gains, supporting near-optimal energy operations and accelerating renewable deployment.
LLMs-guided adaptive compensator: Bringing Adaptivity to Automatic Control Systems with Large Language Models
Jul 28, 2025With rapid advances in code generation, reasoning, and problem-solving, Large Language Models (LLMs) are increasingly applied in robotics. Most existing work focuses on high-level tasks such as task decomposition. A few studies have explored the use of LLMs in feedback controller design; however, these efforts are restricted to overly simplified systems, fixed-structure gain tuning, and lack real-world validation. To further investigate LLMs in automatic control, this work targets a key subfield: adaptive control. Inspired by the framework of model reference adaptive control (MRAC), we propose an LLM-guided adaptive compensator framework that avoids designing controllers from scratch. Instead, the LLMs are prompted using the discrepancies between an unknown system and a reference system to design a compensator that aligns the response of the unknown system with that of the reference, thereby achieving adaptivity. Experiments evaluate five methods: LLM-guided adaptive compensator, LLM-guided adaptive controller, indirect adaptive control, learning-based adaptive control, and MRAC, on soft and humanoid robots in both simulated and real-world environments. Results show that the LLM-guided adaptive compensator outperforms traditional adaptive controllers and significantly reduces reasoning complexity compared to the LLM-guided adaptive controller. The Lyapunov-based analysis and reasoning-path inspection demonstrate that the LLM-guided adaptive compensator enables a more structured design process by transforming mathematical derivation into a reasoning task, while exhibiting strong generalizability, adaptability, and robustness. This study opens a new direction for applying LLMs in the field of automatic control, offering greater deployability and practicality compared to vision-language models.
Duplex Self-Aligning Resonant Beam Communications and Power Transfer with Coupled Spatially Distributed Laser Resonator
May 08, 2025



Sustainable energy supply and high-speed communications are two significant needs for mobile electronic devices. This paper introduces a self-aligning resonant beam system for simultaneous light information and power transfer (SLIPT), employing a novel coupled spatially distributed resonator (CSDR). The system utilizes a resonant beam for efficient power delivery and a second-harmonic beam for concurrent data transmission, inherently minimizing echo interference and enabling bidirectional communication. Through comprehensive analyses, we investigate the CSDR's stable region, beam evolution, and power characteristics in relation to working distance and device parameters. Numerical simulations validate the CSDR-SLIPT system's feasibility by identifying a stable beam waist location for achieving accurate mode-match coupling between two spatially distributed resonant cavities and demonstrating its operational range and efficient power delivery across varying distances. The research reveals the system's benefits in terms of both safety and energy transmission efficiency. We also demonstrate the trade-off among the reflectivities of the cavity mirrors in the CSDR. These findings offer valuable design insights for resonant beam systems, advancing SLIPT with significant potential for remote device connectivity.
Bayesian Reasoning Enabled by Spin-Orbit Torque Magnetic Tunnel Junctions
Apr 11, 2025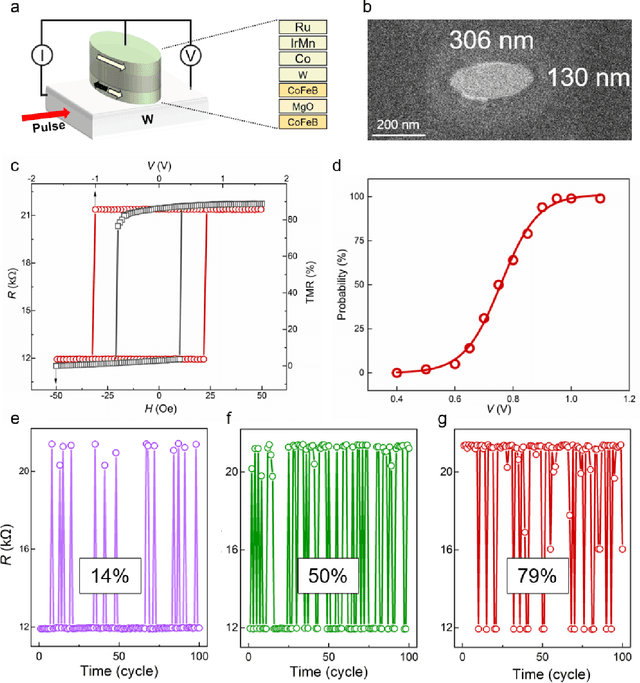
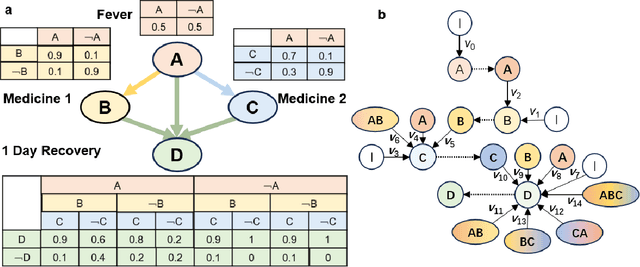
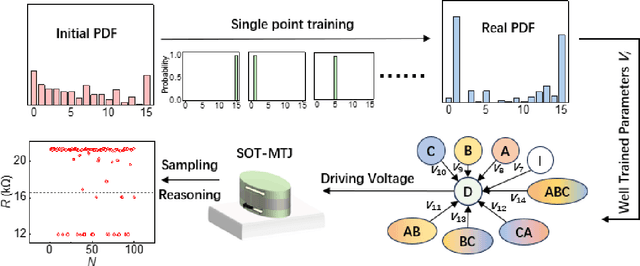
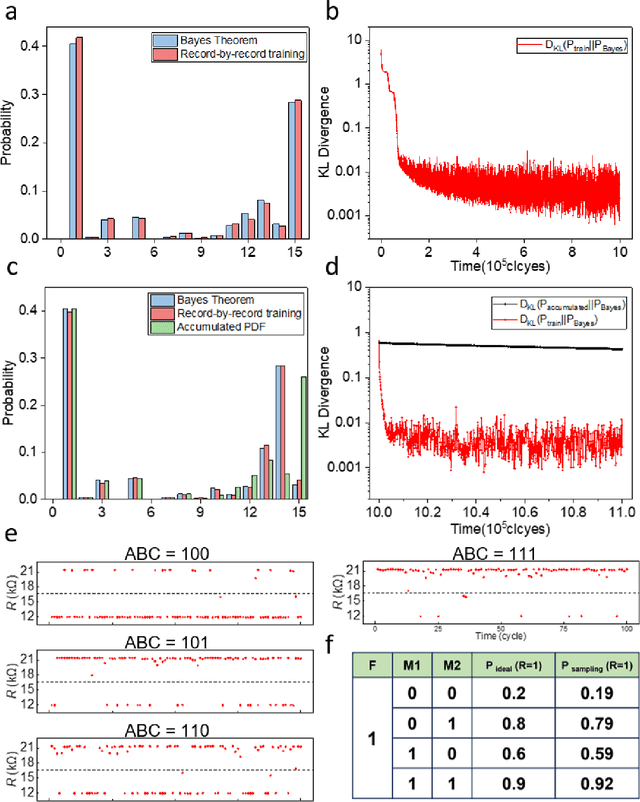
Bayesian networks play an increasingly important role in data mining, inference, and reasoning with the rapid development of artificial intelligence. In this paper, we present proof-of-concept experiments demonstrating the use of spin-orbit torque magnetic tunnel junctions (SOT-MTJs) in Bayesian network reasoning. Not only can the target probability distribution function (PDF) of a Bayesian network be precisely formulated by a conditional probability table as usual but also quantitatively parameterized by a probabilistic forward propagating neuron network. Moreover, the parameters of the network can also approach the optimum through a simple point-by point training algorithm, by leveraging which we do not need to memorize all historical data nor statistically summarize conditional probabilities behind them, significantly improving storage efficiency and economizing data pretreatment. Furthermore, we developed a simple medical diagnostic system using the SOT-MTJ as a random number generator and sampler, showcasing the application of SOT-MTJ-based Bayesian reasoning. This SOT-MTJ-based Bayesian reasoning shows great promise in the field of artificial probabilistic neural network, broadening the scope of spintronic device applications and providing an efficient and low-storage solution for complex reasoning tasks.
Kaiwu: A Multimodal Manipulation Dataset and Framework for Robot Learning and Human-Robot Interaction
Mar 07, 2025



Cutting-edge robot learning techniques including foundation models and imitation learning from humans all pose huge demands on large-scale and high-quality datasets which constitute one of the bottleneck in the general intelligent robot fields. This paper presents the Kaiwu multimodal dataset to address the missing real-world synchronized multimodal data problems in the sophisticated assembling scenario,especially with dynamics information and its fine-grained labelling. The dataset first provides an integration of human,environment and robot data collection framework with 20 subjects and 30 interaction objects resulting in totally 11,664 instances of integrated actions. For each of the demonstration,hand motions,operation pressures,sounds of the assembling process,multi-view videos, high-precision motion capture information,eye gaze with first-person videos,electromyography signals are all recorded. Fine-grained multi-level annotation based on absolute timestamp,and semantic segmentation labelling are performed. Kaiwu dataset aims to facilitate robot learning,dexterous manipulation,human intention investigation and human-robot collaboration research.