 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedaVinci-Env: Open SWE Environment Synthesis at Scale
Mar 16, 2026Training capable software engineering (SWE) agents demands large-scale, executable, and verifiable environments that provide dynamic feedback loops for iterative code editing, test execution, and solution refinement. However, existing open-source datasets remain limited in scale and repository diversity, while industrial solutions are opaque with unreleased infrastructure, creating a prohibitive barrier for most academic research groups. We present OpenSWE, the largest fully transparent framework for SWE agent training in Python, comprising 45,320 executable Docker environments spanning over 12.8k repositories, with all Dockerfiles, evaluation scripts, and infrastructure fully open-sourced for reproducibility. OpenSWE is built through a multi-agent synthesis pipeline deployed across a 64-node distributed cluster, automating repository exploration, Dockerfile construction, evaluation script generation, and iterative test analysis. Beyond scale, we propose a quality-centric filtering pipeline that characterizes the inherent difficulty of each environment, filtering out instances that are either unsolvable or insufficiently challenging and retaining only those that maximize learning efficiency. With $891K spent on environment construction and an additional $576K on trajectory sampling and difficulty-aware curation, the entire project represents a total investment of approximately $1.47 million, yielding about 13,000 curated trajectories from roughly 9,000 quality guaranteed environments. Extensive experiments validate OpenSWE's effectiveness: OpenSWE-32B and OpenSWE-72B achieve 62.4% and 66.0% on SWE-bench Verified, establishing SOTA among Qwen2.5 series. Moreover, SWE-focused training yields substantial out-of-domain improvements, including up to 12 points on mathematical reasoning and 5 points on science benchmarks, without degrading factual recall.
GaussianUpdate: Continual 3D Gaussian Splatting Update for Changing Environments
Aug 12, 2025Novel view synthesis with neural models has advanced rapidly in recent years, yet adapting these models to scene changes remains an open problem. Existing methods are either labor-intensive, requiring extensive model retraining, or fail to capture detailed types of changes over time. In this paper, we present GaussianUpdate, a novel approach that combines 3D Gaussian representation with continual learning to address these challenges. Our method effectively updates the Gaussian radiance fields with current data while preserving information from past scenes. Unlike existing methods, GaussianUpdate explicitly models different types of changes through a novel multi-stage update strategy. Additionally, we introduce a visibility-aware continual learning approach with generative replay, enabling self-aware updating without the need to store images. The experiments on the benchmark dataset demonstrate our method achieves superior and real-time rendering with the capability of visualizing changes over different times
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
SGFormer: Satellite-Ground Fusion for 3D Semantic Scene Completion
Mar 21, 2025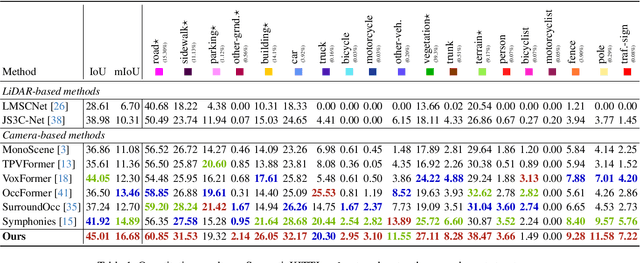
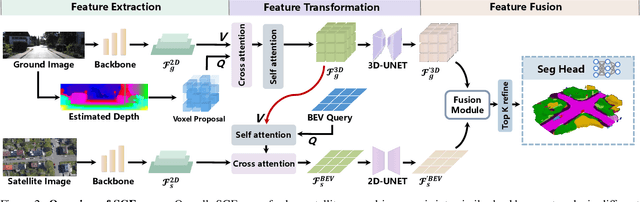
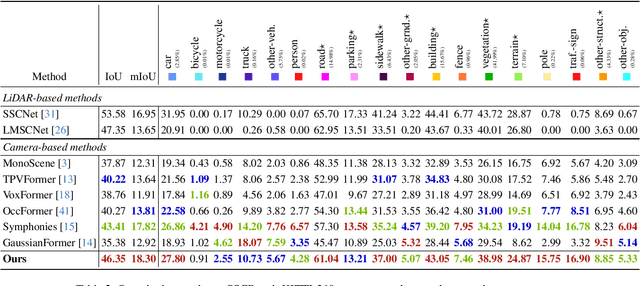
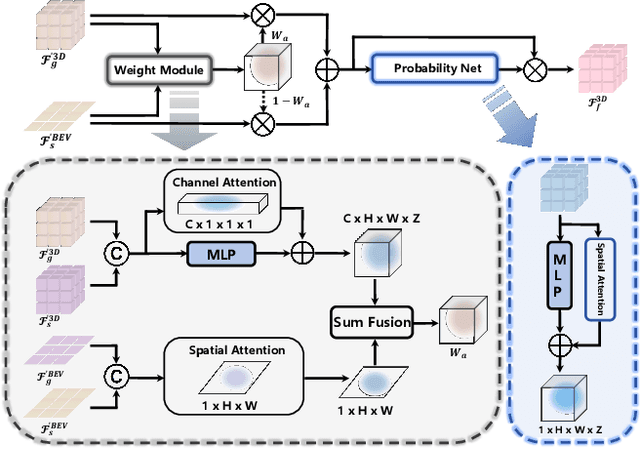
Recently, camera-based solutions have been extensively explored for scene semantic completion (SSC). Despite their success in visible areas, existing methods struggle to capture complete scene semantics due to frequent visual occlusions. To address this limitation, this paper presents the first satellite-ground cooperative SSC framework, i.e., SGFormer, exploring the potential of satellite-ground image pairs in the SSC task. Specifically, we propose a dual-branch architecture that encodes orthogonal satellite and ground views in parallel, unifying them into a common domain. Additionally, we design a ground-view guidance strategy that corrects satellite image biases during feature encoding, addressing misalignment between satellite and ground views. Moreover, we develop an adaptive weighting strategy that balances contributions from satellite and ground views. Experiments demonstrate that SGFormer outperforms the state of the art on SemanticKITTI and SSCBench-KITTI-360 datasets. Our code is available on https://github.com/gxytcrc/SGFormer.
SSFold: Learning to Fold Arbitrary Crumpled Cloth Using Graph Dynamics from Human Demonstration
Oct 24, 2024



Robotic cloth manipulation faces challenges due to the fabric's complex dynamics and the high dimensionality of configuration spaces. Previous methods have largely focused on isolated smoothing or folding tasks and overly reliant on simulations, often failing to bridge the significant sim-to-real gap in deformable object manipulation. To overcome these challenges, we propose a two-stream architecture with sequential and spatial pathways, unifying smoothing and folding tasks into a single adaptable policy model that accommodates various cloth types and states. The sequential stream determines the pick and place positions for the cloth, while the spatial stream, using a connectivity dynamics model, constructs a visibility graph from partial point cloud data of the self-occluded cloth, allowing the robot to infer the cloth's full configuration from incomplete observations. To bridge the sim-to-real gap, we utilize a hand tracking detection algorithm to gather and integrate human demonstration data into our novel end-to-end neural network, improving real-world adaptability. Our method, validated on a UR5 robot across four distinct cloth folding tasks with different goal shapes, consistently achieves folded states from arbitrary crumpled initial configurations, with success rates of 99\%, 99\%, 83\%, and 67\%. It outperforms existing state-of-the-art cloth manipulation techniques and demonstrates strong generalization to unseen cloth with diverse colors, shapes, and stiffness in real-world experiments.Videos and source code are available at: https://zcswdt.github.io/SSFold/
CG-SLAM: Efficient Dense RGB-D SLAM in a Consistent Uncertainty-aware 3D Gaussian Field
Mar 24, 2024
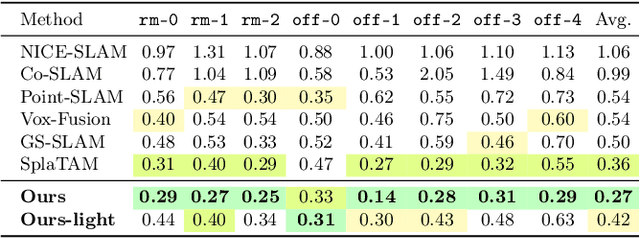
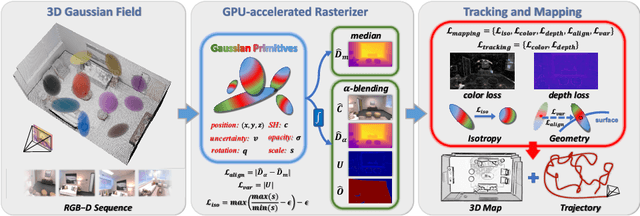
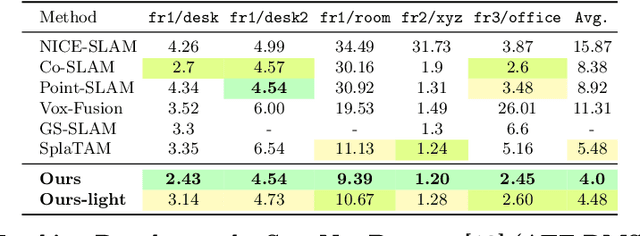
Recently neural radiance fields (NeRF) have been widely exploited as 3D representations for dense simultaneous localization and mapping (SLAM). Despite their notable successes in surface modeling and novel view synthesis, existing NeRF-based methods are hindered by their computationally intensive and time-consuming volume rendering pipeline. This paper presents an efficient dense RGB-D SLAM system, i.e., CG-SLAM, based on a novel uncertainty-aware 3D Gaussian field with high consistency and geometric stability. Through an in-depth analysis of Gaussian Splatting, we propose several techniques to construct a consistent and stable 3D Gaussian field suitable for tracking and mapping. Additionally, a novel depth uncertainty model is proposed to ensure the selection of valuable Gaussian primitives during optimization, thereby improving tracking efficiency and accuracy. Experiments on various datasets demonstrate that CG-SLAM achieves superior tracking and mapping performance with a notable tracking speed of up to 15 Hz. We will make our source code publicly available. Project page: https://zju3dv.github.io/cg-slam.
CP-SLAM: Collaborative Neural Point-based SLAM System
Nov 14, 2023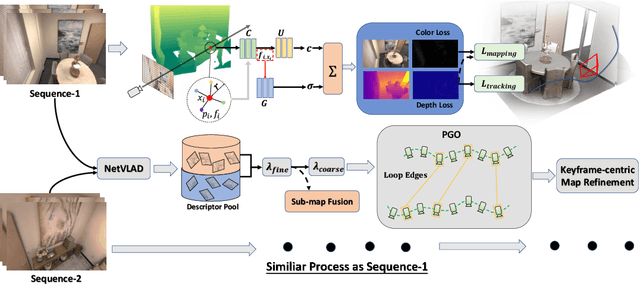
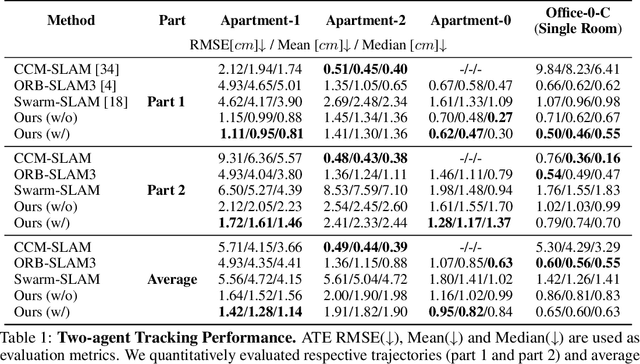
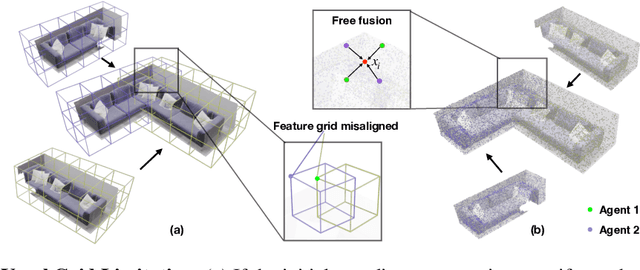
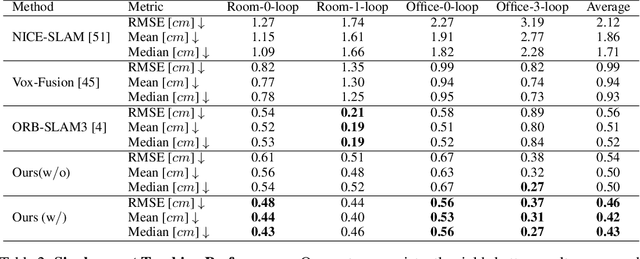
This paper presents a collaborative implicit neural simultaneous localization and mapping (SLAM) system with RGB-D image sequences, which consists of complete front-end and back-end modules including odometry, loop detection, sub-map fusion, and global refinement. In order to enable all these modules in a unified framework, we propose a novel neural point based 3D scene representation in which each point maintains a learnable neural feature for scene encoding and is associated with a certain keyframe. Moreover, a distributed-to-centralized learning strategy is proposed for the collaborative implicit SLAM to improve consistency and cooperation. A novel global optimization framework is also proposed to improve the system accuracy like traditional bundle adjustment. Experiments on various datasets demonstrate the superiority of the proposed method in both camera tracking and mapping.