 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGFormer: Satellite-Ground Fusion for 3D Semantic Scene Completion
Paper and Code
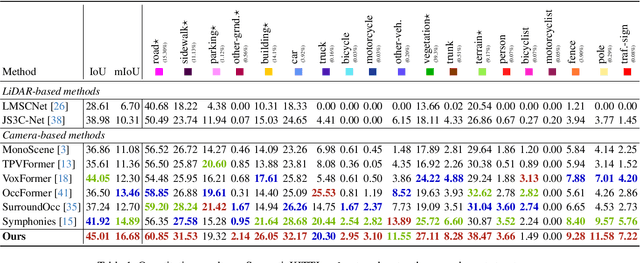
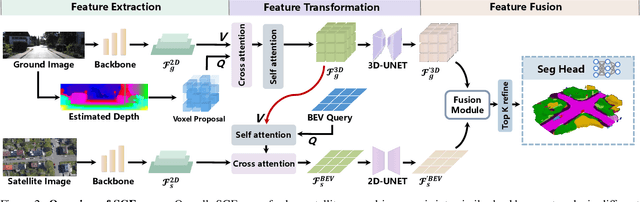
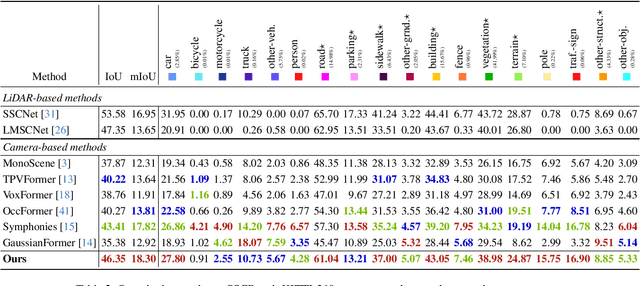
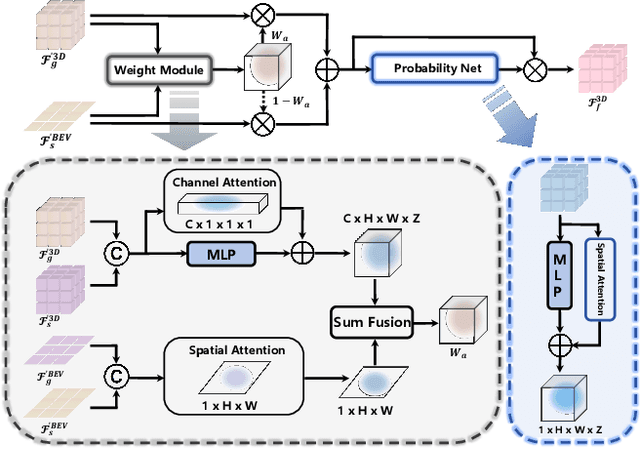
Recently, camera-based solutions have been extensively explored for scene semantic completion (SSC). Despite their success in visible areas, existing methods struggle to capture complete scene semantics due to frequent visual occlusions. To address this limitation, this paper presents the first satellite-ground cooperative SSC framework, i.e., SGFormer, exploring the potential of satellite-ground image pairs in the SSC task. Specifically, we propose a dual-branch architecture that encodes orthogonal satellite and ground views in parallel, unifying them into a common domain. Additionally, we design a ground-view guidance strategy that corrects satellite image biases during feature encoding, addressing misalignment between satellite and ground views. Moreover, we develop an adaptive weighting strategy that balances contributions from satellite and ground views. Experiments demonstrate that SGFormer outperforms the state of the art on SemanticKITTI and SSCBench-KITTI-360 datasets. Our code is available on https://github.com/gxytcrc/SGFormer.