 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaSBench-Video: A Streaming Video Benchmark for Proactive Safety Warning
Jun 01, 2026Between the first visible sign of danger and the moment an accident occurs, there is often a window where intervention remains possible. Video-capable multimodal large language models (MLLMs) could serve as always-on safety monitors that issue warnings during this window. Yet current benchmarks do not test this ability: they rely on static inputs, ignore timing precision, and omit false-positive measurement on safe scenes. We present PaSBench-Video, a 740-video benchmark with 481 risk and 259 no-risk videos across four domains: driving, healthcare, daily life, and industrial production. Risk videos are annotated with frame-level risk onset and accident boundaries. A model must observe the video causally and produce a warning that is both temporally calibrated and content-correct. Testing 13 MLLMs, we find that no model exceeds 20.0% on our strictest metric, and recall is tightly coupled with false-positive rate, with Pearson correlation 0.64: higher detection comes only at the cost of triggering warnings on the majority of safe clips. Performance splits sharply by domain: models achieve moderate recall at low false-positive rates in daily life, where risks are inherently anomalous, yet fire indiscriminately in driving, where routine and hazardous scenes look alike. These results indicate that current models rely on scene-level activity cues rather than reasoning about emerging harm.
CodeClinic: Evaluating Automation of Coding Skills for Clinical Reasoning Agents
May 10, 2026Clinical reasoning agents based on large language models (LLMs) aim to automate tasks such as intensive care unit (ICU) monitoring and patient state tracking from electronic health records (EHRs). Existing systems typically rely on manually curated clinical tools or skills for concepts such as sepsis detection and organ failure assessment. However, maintaining these tool libraries requires substantial expert effort, while zero-shot querying or code generation often produces inefficient and unreliable reasoning chains, especially under institution-specific clinical policies. We introduce CodeClinic, a benchmark built on MIMIC-IV for evaluating whether LLM agents can synthesize and compose reusable clinical skills instead of relying on fixed toolboxes. The benchmark contains two complementary tasks: longitudinal ICU surveillance and compositional information seeking. The longitudinal setting simulates monitoring patient trajectories with structured decisions every four hours across 25 findings and eight clinical families, while the compositional setting spans 63k instances across 259 tasks in nine domains and is stratified by compositional dependency depth to evaluate increasingly complex multi-step reasoning. We further propose an offline autoformalization pipeline that converts natural-language clinical guidelines into reusable and verified Python skill libraries through iterative LLM refinement. Compared with zero-shot code generation, the resulting libraries improve consistency while reducing per-query token usage by up to 40%.
Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
May 05, 2026Reinforcement learning with verifiable rewards has become a common way to improve explicit reasoning in large language models, but final-answer correctness alone does not reveal whether the reasoning trace is faithful, reliable, or useful to the model that consumes it. This outcome-only signal can reinforce traces that are right for the wrong reasons, overstate reasoning gains by rewarding shortcuts, and propagate flawed intermediate states in multi-step systems. To this end, we propose TraceLift, a planner-executor training framework that treats reasoning as a consumable intermediate artifact. During planner training, the planner emits tagged reasoning. A frozen executor turns this reasoning into the final artifact for verifier feedback, while an executor-grounded reward shapes the intermediate trace. This reward multiplies a rubric-based Reasoning Reward Model (RM) score by measured uplift on the same frozen executor, crediting traces that are both high-quality and useful. To make reasoning quality directly learnable, we introduce TRACELIFT-GROUPS, a rubric-annotated reason-only dataset built from math and code seed problems. Each example is a same-problem group containing a high-quality reference trace and multiple plausible flawed traces with localized perturbations that reduce reasoning quality or solution support while preserving task relevance. Extensive experiments on code and math benchmarks show that this executor-grounded reasoning reward improves the two-stage planner-executor system over execution-only training, suggesting that reasoning supervision should evaluate not only whether a trace looks good, but also whether it helps the model that consumes it.
When Safety Fails Before the Answer: Benchmarking Harmful Behavior Detection in Reasoning Chains
Apr 21, 2026Large reasoning models (LRMs) produce complex, multi-step reasoning traces, yet safety evaluation remains focused on final outputs, overlooking how harm emerges during reasoning. When jailbroken, harm does not appear instantaneously but unfolds through distinct behavioral steps such as suppressing refusal, rationalizing compliance, decomposing harmful tasks, and concealing risk. However, no existing benchmark captures this process at sentence-level granularity within reasoning traces -- a key step toward reliable safety monitoring, interventions, and systematic failure diagnosis. To address this gap, we introduce HarmThoughts, a benchmark for step-wise safety evaluation of reasoning traces. \ourdataset is built on our proposed harm taxonomy of 16 harmful reasoning behaviors across four functional groups that characterize how harm propagates rather than what harm is produced. The dataset consists of 56,931 sentences from 1,018 reasoning traces generated by four model families, each annotated with fine-grained sentence-level behavioral labels. Using HarmThoughts, we analyze harm propagation patterns across reasoning traces, identifying common behavioral trajectories and drift points where reasoning transitions from safe to unsafe. Finally, we systematically compare white-box and black-box detectors on the task of identifying harmful reasoning behaviours on HarmThoughts. Our results show that existing detectors struggle with fine-grained behavior detection in reasoning traces, particularly for nuanced categories within harm emergence and execution, highlighting a critical gap in process-level safety monitoring. HarmThoughts is available publicly at: https://huggingface.co/datasets/ishitakakkar-10/HarmThoughts
From Heads to Neurons: Causal Attribution and Steering in Multi-Task Vision-Language Models
Apr 20, 2026Recent work has increasingly explored neuron-level interpretation in vision-language models (VLMs) to identify neurons critical to final predictions. However, existing neuron analyses generally focus on single tasks, limiting the comparability of neuron importance across tasks. Moreover, ranking strategies tend to score neurons in isolation, overlooking how task-dependent information pathways shape the write-in effects of feed-forward network (FFN) neurons. This oversight can exacerbate neuron polysemanticity in multi-task settings, introducing noise into the identification and intervention of task-critical neurons. In this study, we propose HONES (Head-Oriented Neuron Explanation & Steering), a gradient-free framework for task-aware neuron attribution and steering in multi-task VLMs. HONES ranks FFN neurons by their causal write-in contributions conditioned on task-relevant attention heads, and further modulates salient neurons via lightweight scaling. Experiments on four diverse multimodal tasks and two popular VLMs show that HONES outperforms existing methods in identifying task-critical neurons and improves model performance after steering. Our source code is released at: https://github.com/petergit1/HONES.
Opportunistic Promptable Segmentation: Leveraging Routine Radiological Annotations to Guide 3D CT Lesion Segmentation
Jan 30, 2026The development of machine learning models for CT imaging depends on the availability of large, high-quality, and diverse annotated datasets. Although large volumes of CT images and reports are readily available in clinical picture archiving and communication systems (PACS), 3D segmentations of critical findings are costly to obtain, typically requiring extensive manual annotation by radiologists. On the other hand, it is common for radiologists to provide limited annotations of findings during routine reads, such as line measurements and arrows, that are often stored in PACS as GSPS objects. We posit that these sparse annotations can be extracted along with CT volumes and converted into 3D segmentations using promptable segmentation models, a paradigm we term Opportunistic Promptable Segmentation. To enable this paradigm, we propose SAM2CT, the first promptable segmentation model designed to convert radiologist annotations into 3D segmentations in CT volumes. SAM2CT builds upon SAM2 by extending the prompt encoder to support arrow and line inputs and by introducing Memory-Conditioned Memories (MCM), a memory encoding strategy tailored to 3D medical volumes. On public lesion segmentation benchmarks, SAM2CT outperforms existing promptable segmentation models and similarly trained baselines, achieving Dice similarity coefficients of 0.649 for arrow prompts and 0.757 for line prompts. Applying the model to pre-existing GSPS annotations from a clinical PACS (N = 60), SAM2CT generates 3D segmentations that are clinically acceptable or require only minor adjustments in 87% of cases, as scored by radiologists. Additionally, SAM2CT demonstrates strong zero-shot performance on select Emergency Department findings. These results suggest that large-scale mining of historical GSPS annotations represents a promising and scalable approach for generating 3D CT segmentation datasets.
SITA: Learning Speaker-Invariant and Tone-Aware Speech Representations for Low-Resource Tonal Languages
Jan 14, 2026Tonal low-resource languages are widely spoken yet remain underserved by modern speech technology. A key challenge is learning representations that are robust to nuisance variation such as gender while remaining tone-aware for different lexical meanings. To address this, we propose SITA, a lightweight adaptation recipe that enforces Speaker-Invariance and Tone-Awareness for pretrained wav2vec-style encoders. SITA uses staged multi-objective training: (i) a cross-gender contrastive objective encourages lexical consistency across speakers, while a tone-repulsive loss prevents tone collapse by explicitly separating same-word different-tone realizations; and (ii) an auxiliary Connectionist Temporal Classification (CTC)-based ASR objective with distillation stabilizes recognition-relevant structure. We evaluate primarily on Hmong, a highly tonal and severely under-resourced language where off-the-shelf multilingual encoders fail to represent tone effectively. On a curated Hmong word corpus, SITA improves cross-gender lexical retrieval accuracy, while maintaining usable ASR accuracy relative to an ASR-adapted XLS-R teacher. We further observe similar gains when transferring the same recipe to Mandarin, suggesting SITA is a general, plug-in approach for adapting multilingual speech encoders to tonal languages.
RiskCueBench: Benchmarking Anticipatory Reasoning from Early Risk Cues in Video-Language Models
Jan 06, 2026With the rapid growth of video centered social media, the ability to anticipate risky events from visual data is a promising direction for ensuring public safety and preventing real world accidents. Prior work has extensively studied supervised video risk assessment across domains such as driving, protests, and natural disasters. However, many existing datasets provide models with access to the full video sequence, including the accident itself, which substantially reduces the difficulty of the task. To better reflect real world conditions, we introduce a new video understanding benchmark RiskCueBench in which videos are carefully annotated to identify a risk signal clip, defined as the earliest moment that indicates a potential safety concern. Experimental results reveal a significant gap in current systems ability to interpret evolving situations and anticipate future risky events from early visual signals, highlighting important challenges for deploying video risk prediction models in practice.
MMGR: Multi-Modal Generative Reasoning
Dec 17, 2025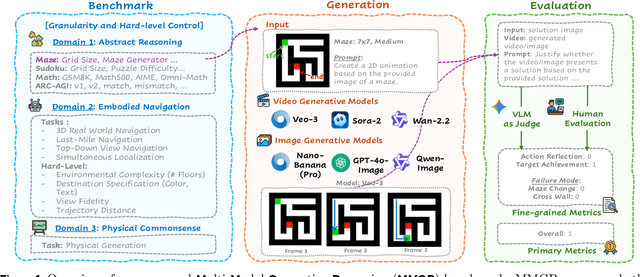
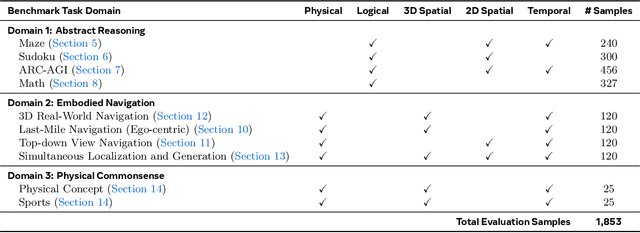

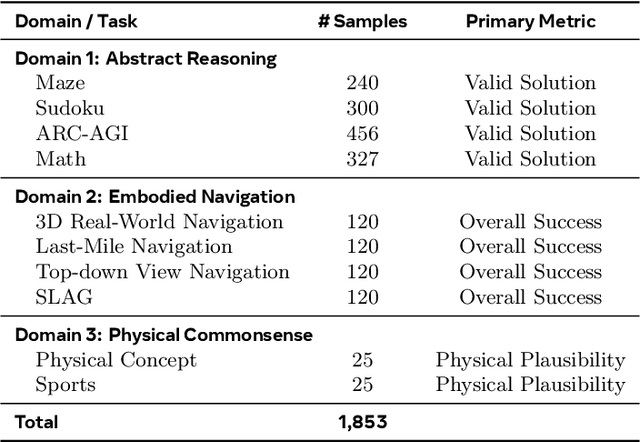
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
Class Incremental Medical Image Segmentation via Prototype-Guided Calibration and Dual-Aligned Distillation
Nov 11, 2025



Class incremental medical image segmentation (CIMIS) aims to preserve knowledge of previously learned classes while learning new ones without relying on old-class labels. However, existing methods 1) either adopt one-size-fits-all strategies that treat all spatial regions and feature channels equally, which may hinder the preservation of accurate old knowledge, 2) or focus solely on aligning local prototypes with global ones for old classes while overlooking their local representations in new data, leading to knowledge degradation. To mitigate the above issues, we propose Prototype-Guided Calibration Distillation (PGCD) and Dual-Aligned Prototype Distillation (DAPD) for CIMIS in this paper. Specifically, PGCD exploits prototype-to-feature similarity to calibrate class-specific distillation intensity in different spatial regions, effectively reinforcing reliable old knowledge and suppressing misleading information from old classes. Complementarily, DAPD aligns the local prototypes of old classes extracted from the current model with both global prototypes and local prototypes, further enhancing segmentation performance on old categories. Comprehensive evaluations on two widely used multi-organ segmentation benchmarks demonstrate that our method outperforms state-of-the-art methods, highlighting its robustness and generalization capabilities.