 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Augmented Representations for Multimodal Retrieval
Feb 06, 2026Universal Multimodal Retrieval (UMR) seeks any-to-any search across text and vision, yet modern embedding models remain brittle when queries require latent reasoning (e.g., resolving underspecified references or matching compositional constraints). We argue this brittleness is often data-induced: when images carry "silent" evidence and queries leave key semantics implicit, a single embedding pass must both reason and compress, encouraging spurious feature matching. We propose a data-centric framework that decouples these roles by externalizing reasoning before retrieval. Using a strong Vision--Language Model, we make implicit semantics explicit by densely captioning visual evidence in corpus entries, resolving ambiguous multimodal references in queries, and rewriting verbose instructions into concise retrieval constraints. Inference-time enhancement alone is insufficient; the retriever must be trained on these semantically dense representations to avoid distribution shift and fully exploit the added signal. Across M-BEIR, our reasoning-augmented training method yields consistent gains over strong baselines, with ablations showing that corpus enhancement chiefly benefits knowledge-intensive queries while query enhancement is critical for compositional modification requests. We publicly release our code at https://github.com/AugmentedRetrieval/ReasoningAugmentedRetrieval.
VisualToolAgent (VisTA): A Reinforcement Learning Framework for Visual Tool Selection
May 26, 2025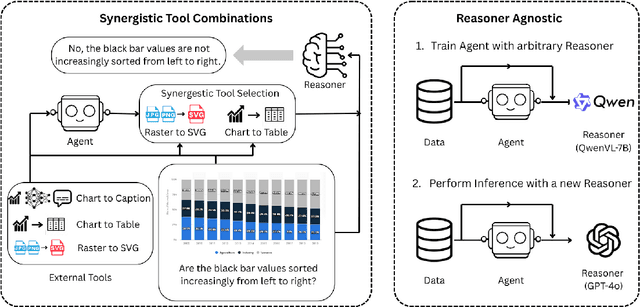
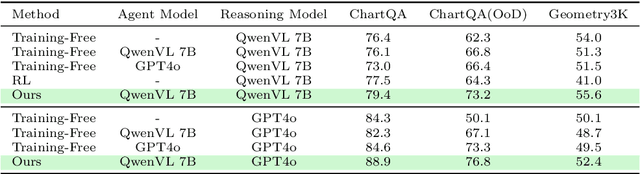
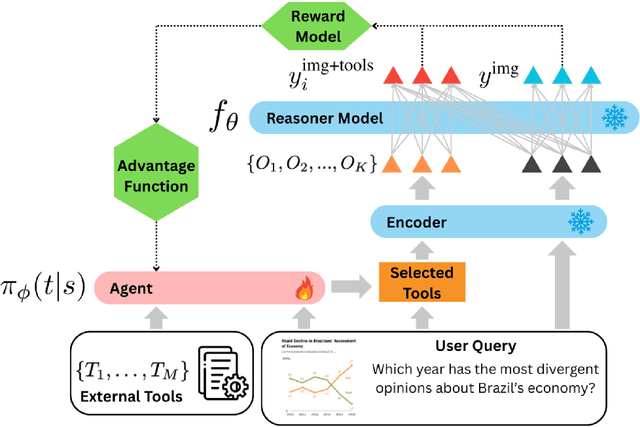
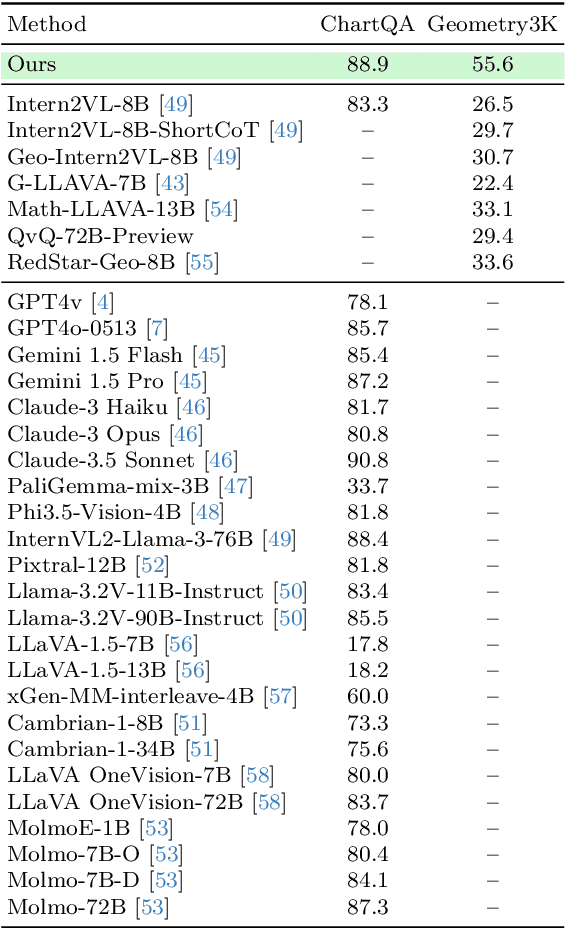
We introduce VisTA, a new reinforcement learning framework that empowers visual agents to dynamically explore, select, and combine tools from a diverse library based on empirical performance. Existing methods for tool-augmented reasoning either rely on training-free prompting or large-scale fine-tuning; both lack active tool exploration and typically assume limited tool diversity, and fine-tuning methods additionally demand extensive human supervision. In contrast, VisTA leverages end-to-end reinforcement learning to iteratively refine sophisticated, query-specific tool selection strategies, using task outcomes as feedback signals. Through Group Relative Policy Optimization (GRPO), our framework enables an agent to autonomously discover effective tool-selection pathways without requiring explicit reasoning supervision. Experiments on the ChartQA, Geometry3K, and BlindTest benchmarks demonstrate that VisTA achieves substantial performance gains over training-free baselines, especially on out-of-distribution examples. These results highlight VisTA's ability to enhance generalization, adaptively utilize diverse tools, and pave the way for flexible, experience-driven visual reasoning systems.
Stay-Positive: A Case for Ignoring Real Image Features in Fake Image Detection
Feb 11, 2025Detecting AI generated images is a challenging yet essential task. A primary difficulty arises from the detectors tendency to rely on spurious patterns, such as compression artifacts, which can influence its decisions. These issues often stem from specific patterns that the detector associates with the real data distribution, making it difficult to isolate the actual generative traces. We argue that an image should be classified as fake if and only if it contains artifacts introduced by the generative model. Based on this premise, we propose Stay Positive, an algorithm designed to constrain the detectors focus to generative artifacts while disregarding those associated with real data. Experimental results demonstrate that detectors trained with Stay Positive exhibit reduced susceptibility to spurious correlations, leading to improved generalization and robustness to post processing. Additionally, unlike detectors that associate artifacts with real images, those that focus purely on fake artifacts are better at detecting inpainted real images.
On the Effectiveness of Dataset Alignment for Fake Image Detection
Oct 15, 2024



As latent diffusion models (LDMs) democratize image generation capabilities, there is a growing need to detect fake images. A good detector should focus on the generative models fingerprints while ignoring image properties such as semantic content, resolution, file format, etc. Fake image detectors are usually built in a data driven way, where a model is trained to separate real from fake images. Existing works primarily investigate network architecture choices and training recipes. In this work, we argue that in addition to these algorithmic choices, we also require a well aligned dataset of real/fake images to train a robust detector. For the family of LDMs, we propose a very simple way to achieve this: we reconstruct all the real images using the LDMs autoencoder, without any denoising operation. We then train a model to separate these real images from their reconstructions. The fakes created this way are extremely similar to the real ones in almost every aspect (e.g., size, aspect ratio, semantic content), which forces the model to look for the LDM decoders artifacts. We empirically show that this way of creating aligned real/fake datasets, which also sidesteps the computationally expensive denoising process, helps in building a detector that focuses less on spurious correlations, something that a very popular existing method is susceptible to. Finally, to demonstrate just how effective the alignment in a dataset can be, we build a detector using images that are not natural objects, and present promising results. Overall, our work identifies the subtle but significant issues that arise when training a fake image detector and proposes a simple and inexpensive solution to address these problems.