 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision Models Develop Human-Like Progressive Difficulty Understanding?
Mar 17, 2025When a human undertakes a test, their responses likely follow a pattern: if they answered an easy question $(2 \times 3)$ incorrectly, they would likely answer a more difficult one $(2 \times 3 \times 4)$ incorrectly; and if they answered a difficult question correctly, they would likely answer the easy one correctly. Anything else hints at memorization. Do current visual recognition models exhibit a similarly structured learning capacity? In this work, we consider the task of image classification and study if those models' responses follow that pattern. Since real images aren't labeled with difficulty, we first create a dataset of 100 categories, 10 attributes, and 3 difficulty levels using recent generative models: for each category (e.g., dog) and attribute (e.g., occlusion), we generate images of increasing difficulty (e.g., a dog without occlusion, a dog only partly visible). We find that most of the models do in fact behave similarly to the aforementioned pattern around 80-90% of the time. Using this property, we then explore a new way to evaluate those models. Instead of testing the model on every possible test image, we create an adaptive test akin to GRE, in which the model's performance on the current round of images determines the test images in the next round. This allows the model to skip over questions too easy/hard for itself, and helps us get its overall performance in fewer steps.
On the Effectiveness of Dataset Alignment for Fake Image Detection
Oct 15, 2024



As latent diffusion models (LDMs) democratize image generation capabilities, there is a growing need to detect fake images. A good detector should focus on the generative models fingerprints while ignoring image properties such as semantic content, resolution, file format, etc. Fake image detectors are usually built in a data driven way, where a model is trained to separate real from fake images. Existing works primarily investigate network architecture choices and training recipes. In this work, we argue that in addition to these algorithmic choices, we also require a well aligned dataset of real/fake images to train a robust detector. For the family of LDMs, we propose a very simple way to achieve this: we reconstruct all the real images using the LDMs autoencoder, without any denoising operation. We then train a model to separate these real images from their reconstructions. The fakes created this way are extremely similar to the real ones in almost every aspect (e.g., size, aspect ratio, semantic content), which forces the model to look for the LDM decoders artifacts. We empirically show that this way of creating aligned real/fake datasets, which also sidesteps the computationally expensive denoising process, helps in building a detector that focuses less on spurious correlations, something that a very popular existing method is susceptible to. Finally, to demonstrate just how effective the alignment in a dataset can be, we build a detector using images that are not natural objects, and present promising results. Overall, our work identifies the subtle but significant issues that arise when training a fake image detector and proposes a simple and inexpensive solution to address these problems.
Yo'LLaVA: Your Personalized Language and Vision Assistant
Jun 13, 2024



Large Multimodal Models (LMMs) have shown remarkable capabilities across a variety of tasks (e.g., image captioning, visual question answering). While broad, their knowledge remains generic (e.g., recognizing a dog), and they are unable to handle personalized subjects (e.g., recognizing a user's pet dog). Human reasoning, in contrast, typically operates within the context of specific subjects in our surroundings. For example, one might ask, "What should I buy for my dog's birthday?"; as opposed to a generic inquiry about "What should I buy for a dog's birthday?". Similarly, when looking at a friend's image, the interest lies in seeing their activities (e.g., "my friend is holding a cat"), rather than merely observing generic human actions (e.g., "a man is holding a cat"). In this paper, we introduce the novel task of personalizing LMMs, so that they can have conversations about a specific subject. We propose Yo'LLaVA, which learns to embed a personalized subject into a set of latent tokens given a handful of example images of the subject. Our qualitative and quantitative analyses reveal that Yo'LLaVA can learn the concept more efficiently using fewer tokens and more effectively encode the visual attributes compared to strong prompting baselines (e.g., LLaVA).
Edit One for All: Interactive Batch Image Editing
Jan 18, 2024



In recent years, image editing has advanced remarkably. With increased human control, it is now possible to edit an image in a plethora of ways; from specifying in text what we want to change, to straight up dragging the contents of the image in an interactive point-based manner. However, most of the focus has remained on editing single images at a time. Whether and how we can simultaneously edit large batches of images has remained understudied. With the goal of minimizing human supervision in the editing process, this paper presents a novel method for interactive batch image editing using StyleGAN as the medium. Given an edit specified by users in an example image (e.g., make the face frontal), our method can automatically transfer that edit to other test images, so that regardless of their initial state (pose), they all arrive at the same final state (e.g., all facing front). Extensive experiments demonstrate that edits performed using our method have similar visual quality to existing single-image-editing methods, while having more visual consistency and saving significant time and human effort.
Visual Instruction Inversion: Image Editing via Visual Prompting
Jul 26, 2023



Text-conditioned image editing has emerged as a powerful tool for editing images. However, in many situations, language can be ambiguous and ineffective in describing specific image edits. When faced with such challenges, visual prompts can be a more informative and intuitive way to convey ideas. We present a method for image editing via visual prompting. Given pairs of example that represent the "before" and "after" images of an edit, our goal is to learn a text-based editing direction that can be used to perform the same edit on new images. We leverage the rich, pretrained editing capabilities of text-to-image diffusion models by inverting visual prompts into editing instructions. Our results show that with just one example pair, we can achieve competitive results compared to state-of-the-art text-conditioned image editing frameworks.
Towards Universal Fake Image Detectors that Generalize Across Generative Models
Feb 20, 2023



With generative models proliferating at a rapid rate, there is a growing need for general purpose fake image detectors. In this work, we first show that the existing paradigm, which consists of training a deep network for real-vs-fake classification, fails to detect fake images from newer breeds of generative models when trained to detect GAN fake images. Upon analysis, we find that the resulting classifier is asymmetrically tuned to detect patterns that make an image fake. The real class becomes a sink class holding anything that is not fake, including generated images from models not accessible during training. Building upon this discovery, we propose to perform real-vs-fake classification without learning; i.e., using a feature space not explicitly trained to distinguish real from fake images. We use nearest neighbor and linear probing as instantiations of this idea. When given access to the feature space of a large pretrained vision-language model, the very simple baseline of nearest neighbor classification has surprisingly good generalization ability in detecting fake images from a wide variety of generative models; e.g., it improves upon the SoTA by +15.07 mAP and +25.90% acc when tested on unseen diffusion and autoregressive models.
What Knowledge Gets Distilled in Knowledge Distillation?
May 31, 2022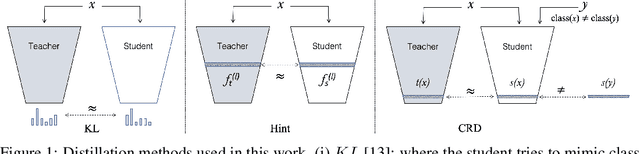


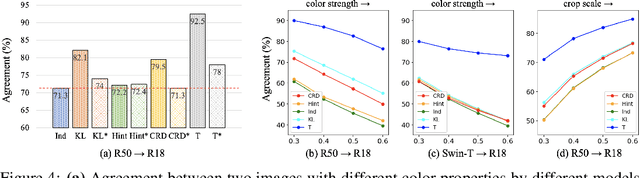
Knowledge distillation aims to transfer useful information from a teacher network to a student network, with the primary goal of improving the student's performance for the task at hand. Over the years, there has a been a deluge of novel techniques and use cases of knowledge distillation. Yet, despite the various improvements, there seems to be a glaring gap in the community's fundamental understanding of the process. Specifically, what is the knowledge that gets distilled in knowledge distillation? In other words, in what ways does the student become similar to the teacher? Does it start to localize objects in the same way? Does it get fooled by the same adversarial samples? Does its data invariance properties become similar? Our work presents a comprehensive study to try to answer these questions and more. Our results, using image classification as a case study and three state-of-the-art knowledge distillation techniques, show that knowledge distillation methods can indeed indirectly distill other kinds of properties beyond improving task performance. By exploring these questions, we hope for our work to provide a clearer picture of what happens during knowledge distillation.
Few-shot Image Generation via Cross-domain Correspondence
Apr 13, 2021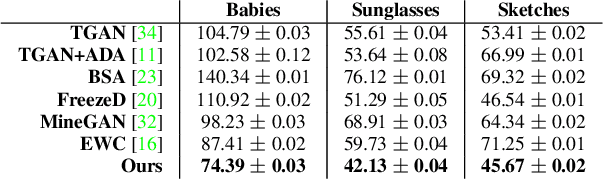

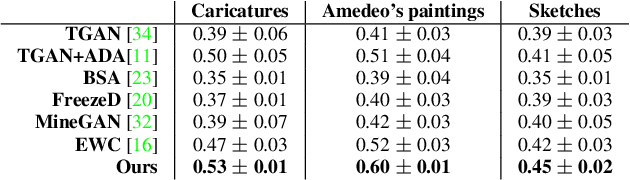
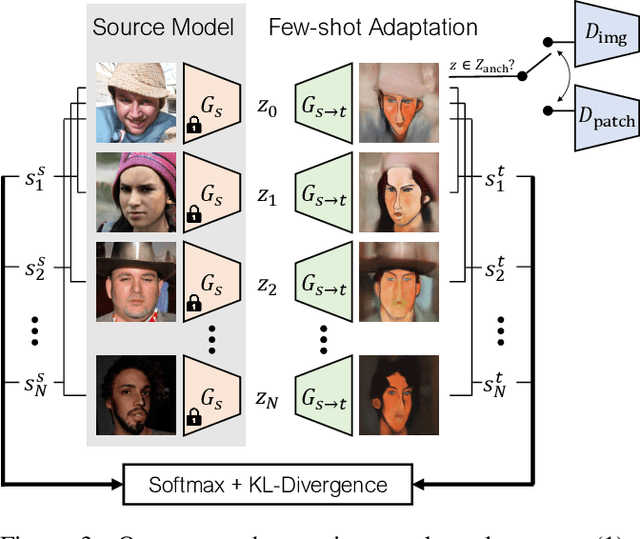
Training generative models, such as GANs, on a target domain containing limited examples (e.g., 10) can easily result in overfitting. In this work, we seek to utilize a large source domain for pretraining and transfer the diversity information from source to target. We propose to preserve the relative similarities and differences between instances in the source via a novel cross-domain distance consistency loss. To further reduce overfitting, we present an anchor-based strategy to encourage different levels of realism over different regions in the latent space. With extensive results in both photorealistic and non-photorealistic domains, we demonstrate qualitatively and quantitatively that our few-shot model automatically discovers correspondences between source and target domains and generates more diverse and realistic images than previous methods.
Generating Furry Cars: Disentangling Object Shape & Appearance across Multiple Domains
Apr 05, 2021
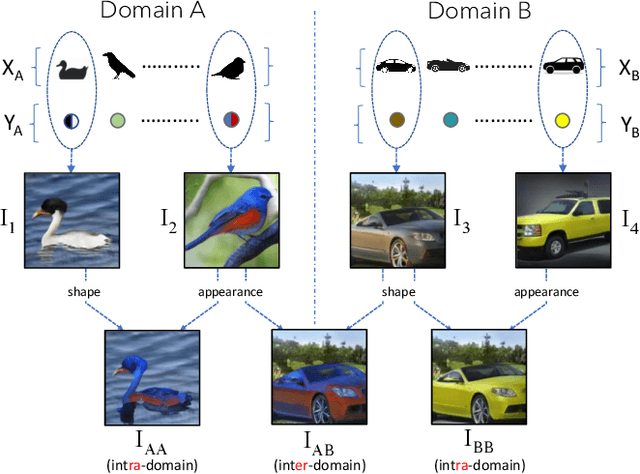

We consider the novel task of learning disentangled representations of object shape and appearance across multiple domains (e.g., dogs and cars). The goal is to learn a generative model that learns an intermediate distribution, which borrows a subset of properties from each domain, enabling the generation of images that did not exist in any domain exclusively. This challenging problem requires an accurate disentanglement of object shape, appearance, and background from each domain, so that the appearance and shape factors from the two domains can be interchanged. We augment an existing approach that can disentangle factors within a single domain but struggles to do so across domains. Our key technical contribution is to represent object appearance with a differentiable histogram of visual features, and to optimize the generator so that two images with the same latent appearance factor but different latent shape factors produce similar histograms. On multiple multi-domain datasets, we demonstrate our method leads to accurate and consistent appearance and shape transfer across domains.
MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation
Nov 27, 2019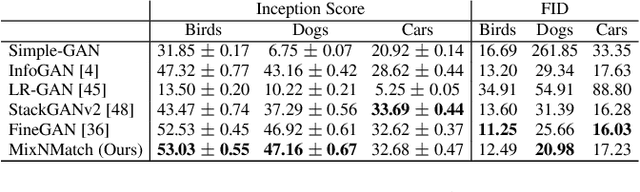

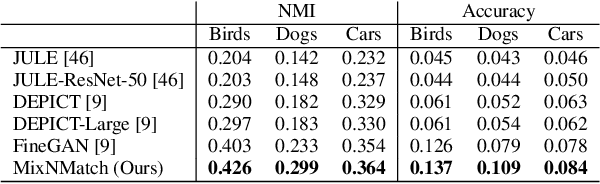

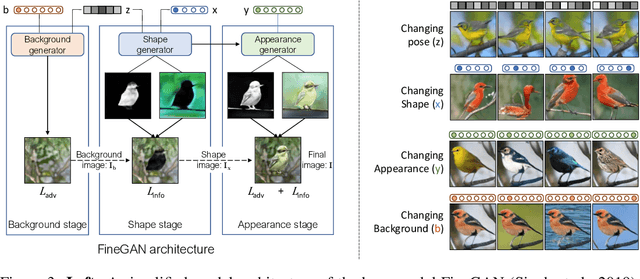
We present MixNMatch, a conditional generative model that learns to disentangle and encode background, object pose, shape, and texture from real images with minimal supervision, for mix-and-match image generation. We build upon FineGAN, an unconditional generative model, to learn the desired disentanglement and image generator, and leverage adversarial joint image-code distribution matching to learn the latent factor encoders. MixNMatch requires bounding boxes during training to model background, but requires no other supervision. Through extensive experiments, we demonstrate MixNMatch's ability to accurately disentangle, encode, and combine multiple factors for mix-and-match image generation, including sketch2color, cartoon2img, and img2gif applications. Our code/models/demo can be found at https://github.com/Yuheng-Li/MixNMatch