 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation
Paper and Code
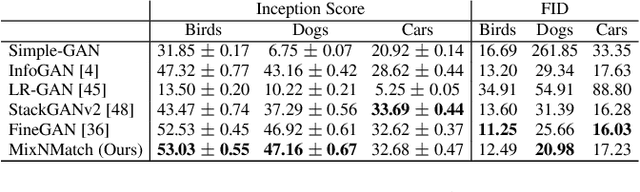

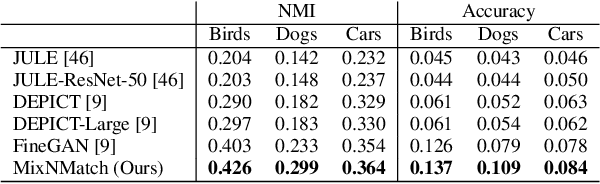

We present MixNMatch, a conditional generative model that learns to disentangle and encode background, object pose, shape, and texture from real images with minimal supervision, for mix-and-match image generation. We build upon FineGAN, an unconditional generative model, to learn the desired disentanglement and image generator, and leverage adversarial joint image-code distribution matching to learn the latent factor encoders. MixNMatch requires bounding boxes during training to model background, but requires no other supervision. Through extensive experiments, we demonstrate MixNMatch's ability to accurately disentangle, encode, and combine multiple factors for mix-and-match image generation, including sketch2color, cartoon2img, and img2gif applications. Our code/models/demo can be found at https://github.com/Yuheng-Li/MixNMatch