 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTemp: Unlocking Video Generation in Any Temporal Order via Bidirectional Distillation
Jun 17, 2026Autoregressive video diffusion models have emerged as a promising approach for long video generation, achieving strong performance in streaming settings. However, existing methods are restricted to forward temporal generation, whereas practical video creation often requires flexible generation order, e.g., conditioning on future context to extend backward, or on both past and future context for inbetween generation. We bridge this gap by training an autoregressive model that supports generation in arbitrary temporal directions. A key technical challenge arises from the Causal 3D VAE widely used in video diffusion models, which encodes latents strictly conditioned on past context. While suited for forward generation, this causal structure causes inter-block discontinuities when generation proceeds backward. To address this, we introduce blockwise anchor latents, a set of auxiliary latents that restore the missing past context at block boundaries during backward generation. Built on this design, we propose UniTemp, a bidirectional distillation framework that trains a single autoregressive student model for any-direction video generation. At inference time, UniTemp conditions on arbitrary past and/or future frames, improving controllability for both bidirectional and inbetween generation. Experiments show that UniTemp maintains competitive performance on short and long video generation compared to forward-only methods, while enabling diverse workflows such as bidirectional video extension, inbetween generation, looping video generation, scene transition, and visual story generation. Project website: https://lzhangbj.github.io/projects/unitemp/
Personal AI Agent for Camera Roll VQA
Jun 03, 2026We study the personal camera roll visual question answering setting. In this setting, a conversational AI assistant can access a user's personal camera roll and retrieve relevant photos to answer queries, ranging from simple factual questions (e.g., ``Name of the food I tried yesterday?'') to more open-ended ones (e.g., ``Recommend some dishes I have never eaten before''). Given the vast nature of the personal camera roll (i.e., multiple years, hundreds to thousands of photos), a successful AI assistant needs to understand a long-horizon, highly personalized visual content stream in order to navigate and locate the correct and/or relevant information. To support this, we collect and manually annotate questions that mimic real-world usage. The final dataset, camroll, contains 50 users, 31,476 images, and 2,500 QA pairs. We further design camroll-agent, a conversational AI agent equipped with hierarchical memory and a minimal set of tools for efficient navigation over large, personalized visual memory. Experimental results show that camroll-agent outperforms numerous baselines and methods for long-context understanding AI agents system. Together, the camroll dataset and camroll-agent highlight the gap in AI agents' long-context reasoning: personalized visual memory requires different approaches from standard long-context textual memory, especially when consistency, visual details, and user-specific context are present.
MAOAM: Unified Object and Material Selection with Vision-Language Models
Jun 02, 2026Selection is a core operation in interactive image editing. To be practical, a user should be able to specify and disambiguate the desired selection region through either text or click-based interactions, and the system should support selecting not only objects but also other criteria, such as materials. Material-based selection is valuable for tasks like re-texturing surfaces or editing instances of a specific material. However, existing vision-language-model (VLM) based selection methods are object-centric and typically support a single interaction modality, limiting their applicability. In this work, we thus present Mask Any Object And Material (MAOAM), a unified selection framework that enables precise object and material-level selection across both text- and click-based interactions. MAOAM leverages a VLM with a segmentation head to produce pixel-accurate masks from user prompts: the VLM interprets the user's selection intent (object or material-level) and encodes visual entities, attributes, and spatial relations, while the segmentation head decodes the output token into a mask. A key challenge is the lack of material selection datasets with text annotations. We propose a scalable data generation pipeline: we collect real and synthetic images with material masks, and leverage VLMs to generate material descriptions with rich visual-semantics. We train MAOAM with a multi-task objective over click and text-based selection, along with an auxiliary VQA task derived from the material descriptions to facilitate deeper material understanding. Despite being trained with uni-modal prompts, our model exhibits an emergent improvement in selection when combining text and clicks at inference, enabling flexible image editing workflows. Experiments demonstrate accurate and coherent selections across diverse objects, materials, and interaction scenarios, highlighting robustness in practice.
AdvantageFlow: Advantage-Weighted Least Squares for RL in Flow Models
May 25, 2026We introduce AdvantageFlow, a forward-process reinforcement learning algorithm for rectified flow models. Unlike Flow-GRPO, which optimizes the reverse process, we optimize an advantage-weighted forward-process prediction loss. This optimization problem is unstable when advantages are negative and the loss becomes non-convex. We stabilize it by rollout policy regularization, which reduces variance and arises from fitting a local reward-improving target distribution. We evaluate AdvantageFlow on image generation tasks with Stable Diffusion 3.5 Medium. It outperforms both Flow-GRPO and a state-of-the-art forward-process RL baseline based on negative-aware fine-tuning.
From Plans to Pixels: Learning to Plan and Orchestrate for Open-Ended Image Editing
May 14, 2026Modern image editing models produce realistic results but struggle with abstract, multi step instructions (e.g., ``make this advertisement more vegetarian-friendly''). Prior agent based methods decompose such tasks but rely on handcrafted pipelines or teacher imitation, limiting flexibility and decoupling learning from actual editing outcomes. We propose an experiential framework for long-horizon image editing, where a planner generates structured atomic decompositions and an orchestrator selects tools and regions to execute each step. A vision language judge provides outcome-based rewards for instruction adherence and visual quality. The orchestrator is trained to maximize these rewards, and successful trajectories are used to refine the planner. By tightly coupling planning with reward driven execution, our approach yields more coherent and reliable edits than single-step or rule-based multistep baselines.
Stepwise Credit Assignment for GRPO on Flow-Matching Models
Mar 30, 2026Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Dec 11, 2025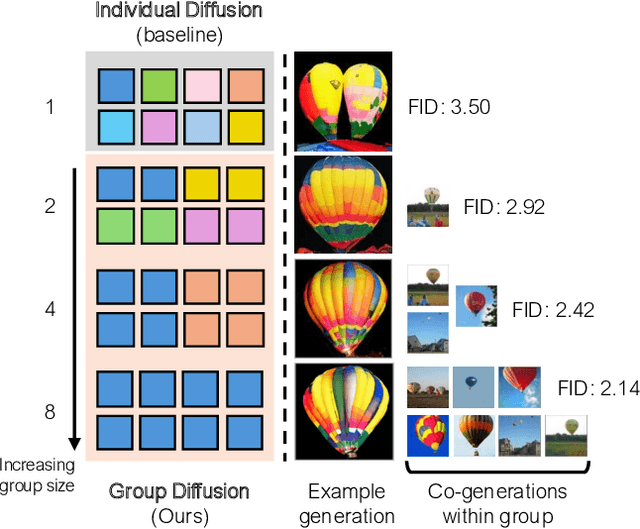
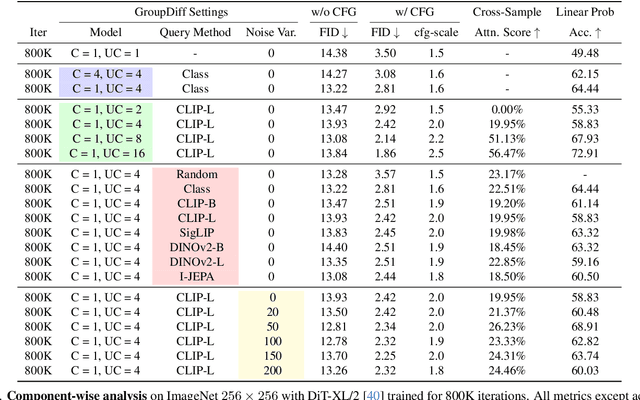

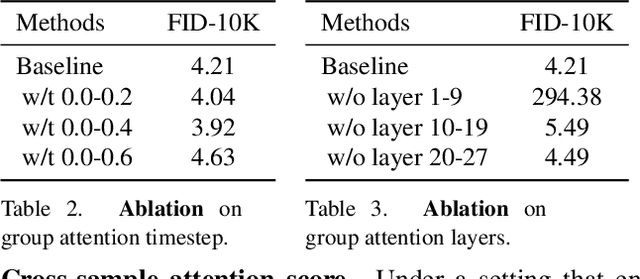
In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.
Relational Visual Similarity
Dec 08, 2025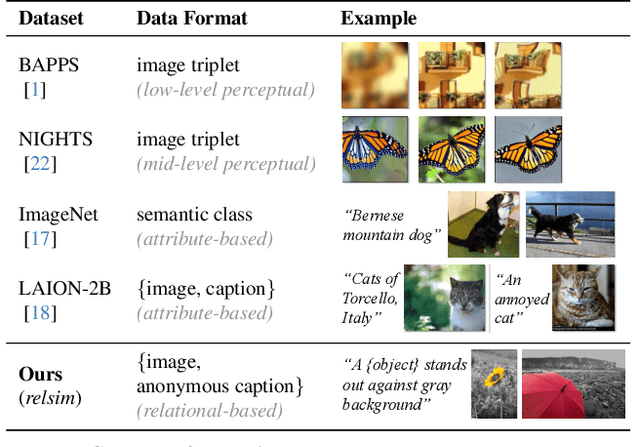
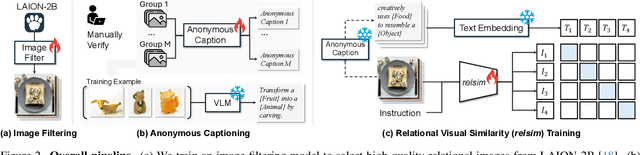
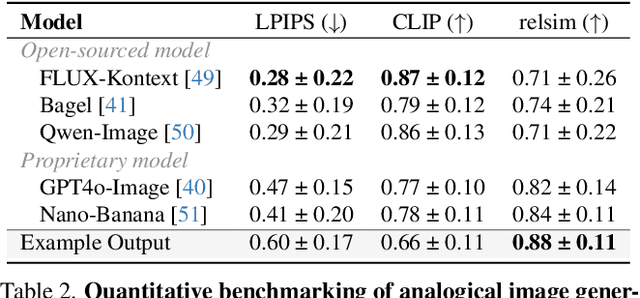

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025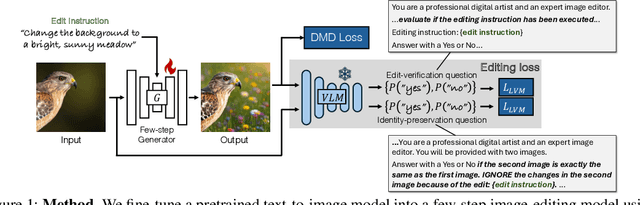
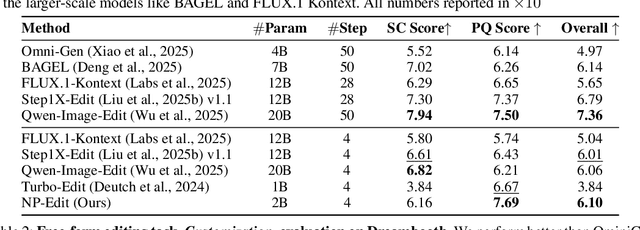

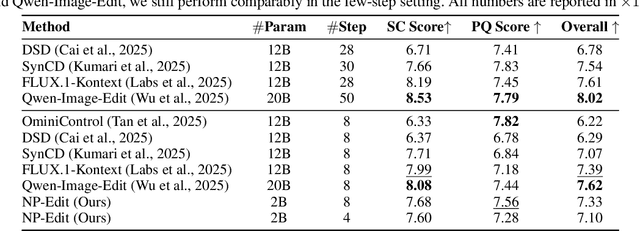
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.