 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionBridge: Dynamic Video Inbetweening with Flexible Controls
Dec 17, 2024



By generating plausible and smooth transitions between two image frames, video inbetweening is an essential tool for video editing and long video synthesis. Traditional works lack the capability to generate complex large motions. While recent video generation techniques are powerful in creating high-quality results, they often lack fine control over the details of intermediate frames, which can lead to results that do not align with the creative mind. We introduce MotionBridge, a unified video inbetweening framework that allows flexible controls, including trajectory strokes, keyframes, masks, guide pixels, and text. However, learning such multi-modal controls in a unified framework is a challenging task. We thus design two generators to extract the control signal faithfully and encode feature through dual-branch embedders to resolve ambiguities. We further introduce a curriculum training strategy to smoothly learn various controls. Extensive qualitative and quantitative experiments have demonstrated that such multi-modal controls enable a more dynamic, customizable, and contextually accurate visual narrative.
SMITE: Segment Me In TimE
Oct 24, 2024
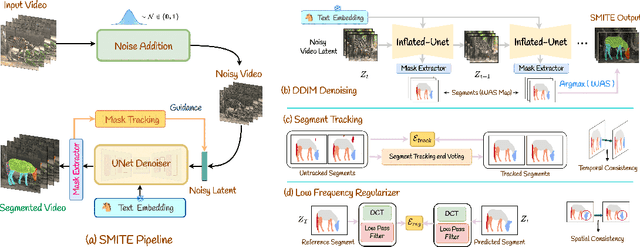

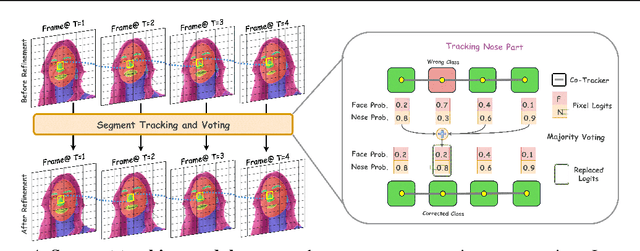
Segmenting an object in a video presents significant challenges. Each pixel must be accurately labelled, and these labels must remain consistent across frames. The difficulty increases when the segmentation is with arbitrary granularity, meaning the number of segments can vary arbitrarily, and masks are defined based on only one or a few sample images. In this paper, we address this issue by employing a pre-trained text to image diffusion model supplemented with an additional tracking mechanism. We demonstrate that our approach can effectively manage various segmentation scenarios and outperforms state-of-the-art alternatives.
GALA: Geometry-Aware Local Adaptive Grids for Detailed 3D Generation
Oct 13, 2024



We propose GALA, a novel representation of 3D shapes that (i) excels at capturing and reproducing complex geometry and surface details, (ii) is computationally efficient, and (iii) lends itself to 3D generative modelling with modern, diffusion-based schemes. The key idea of GALA is to exploit both the global sparsity of surfaces within a 3D volume and their local surface properties. Sparsity is promoted by covering only the 3D object boundaries, not empty space, with an ensemble of tree root voxels. Each voxel contains an octree to further limit storage and compute to regions that contain surfaces. Adaptivity is achieved by fitting one local and geometry-aware coordinate frame in each non-empty leaf node. Adjusting the orientation of the local grid, as well as the anisotropic scales of its axes, to the local surface shape greatly increases the amount of detail that can be stored in a given amount of memory, which in turn allows for quantization without loss of quality. With our optimized C++/CUDA implementation, GALA can be fitted to an object in less than 10 seconds. Moreover, the representation can efficiently be flattened and manipulated with transformer networks. We provide a cascaded generation pipeline capable of generating 3D shapes with great geometric detail.
SLiMe: Segment Like Me
Sep 06, 2023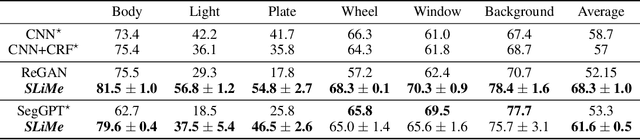

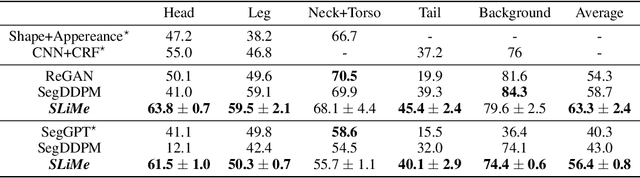

Significant strides have been made using large vision-language models, like Stable Diffusion (SD), for a variety of downstream tasks, including image editing, image correspondence, and 3D shape generation. Inspired by these advancements, we explore leveraging these extensive vision-language models for segmenting images at any desired granularity using as few as one annotated sample by proposing SLiMe. SLiMe frames this problem as an optimization task. Specifically, given a single training image and its segmentation mask, we first extract attention maps, including our novel "weighted accumulated self-attention map" from the SD prior. Then, using the extracted attention maps, the text embeddings of Stable Diffusion are optimized such that, each of them, learn about a single segmented region from the training image. These learned embeddings then highlight the segmented region in the attention maps, which in turn can then be used to derive the segmentation map. This enables SLiMe to segment any real-world image during inference with the granularity of the segmented region in the training image, using just one example. Moreover, leveraging additional training data when available, i.e. few-shot, improves the performance of SLiMe. We carried out a knowledge-rich set of experiments examining various design factors and showed that SLiMe outperforms other existing one-shot and few-shot segmentation methods.
DualCSG: Learning Dual CSG Trees for General and Compact CAD Modeling
Jan 27, 2023We present DualCSG, a novel neural network composed of two dual and complementary branches for unsupervised learning of constructive solid geometry (CSG) representations of 3D CAD shapes. Our network is trained to reconstruct a given 3D CAD shape through a compact assembly of quadric surface primitives via fixed-order CSG operations along two branches. The key difference between our method and all previous neural CSG models is that DualCSG has a dedicated branch, the residual branch, to assemble the potentially complex, complement or residual shape that is to be subtracted from an overall cover shape. The cover shape is modeled by the other branch, the cover branch. Both branches construct a union of primitive intersections, where the only difference is that the residual branch also learns primitive inverses while operating in the complement space. With the shape complements, our network is provably general. We demonstrate both quantitatively and qualitatively that our network produces CSG reconstructions with superior quality, more natural trees, and better quality-compactness tradeoff than all existing alternatives, especially over complex and high-genus CAD shapes.