 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain-Query-Test: Self-Evaluating LLMs Via Explanation and Comprehension Discrepancy
Jan 20, 2025



Large language models (LLMs) have demonstrated remarkable proficiency in generating detailed and coherent explanations of complex concepts. However, the extent to which these models truly comprehend the concepts they articulate remains unclear. To assess the level of comprehension of a model relative to the content it generates, we implemented a self-evaluation pipeline where models: (i) given a topic generate an excerpt with information about the topic, (ii) given an excerpt generate question-answer pairs, and finally (iii) given a question generate an answer. We refer to this self-evaluation approach as Explain-Query-Test (EQT). Interestingly, the accuracy on generated questions resulting from running the EQT pipeline correlates strongly with the model performance as verified by typical benchmarks such as MMLU-Pro. In other words, EQT's performance is predictive of MMLU-Pro's, and EQT can be used to rank models without the need for any external source of evaluation data other than lists of topics of interest. Moreover, our results reveal a disparity between the models' ability to produce detailed explanations and their performance on questions related to those explanations. This gap highlights fundamental limitations in the internal knowledge representation and reasoning abilities of current LLMs. We release the code at https://github.com/asgsaeid/EQT.
Disentangled PET Lesion Segmentation
Nov 04, 2024


PET imaging is an invaluable tool in clinical settings as it captures the functional activity of both healthy anatomy and cancerous lesions. Developing automatic lesion segmentation methods for PET images is crucial since manual lesion segmentation is laborious and prone to inter- and intra-observer variability. We propose PET-Disentangler, a 3D disentanglement method that uses a 3D UNet-like encoder-decoder architecture to disentangle disease and normal healthy anatomical features with losses for segmentation, reconstruction, and healthy component plausibility. A critic network is used to encourage the healthy latent features to match the distribution of healthy samples and thus encourages these features to not contain any lesion-related features. Our quantitative results show that PET-Disentangler is less prone to incorrectly declaring healthy and high tracer uptake regions as cancerous lesions, since such uptake pattern would be assigned to the disentangled healthy component.
SMITE: Segment Me In TimE
Oct 24, 2024
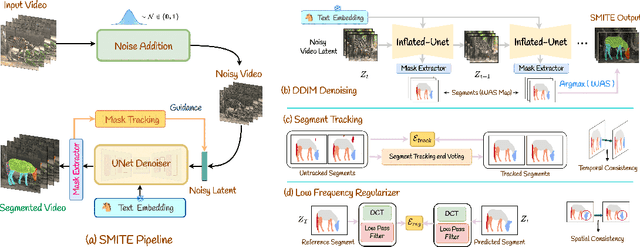

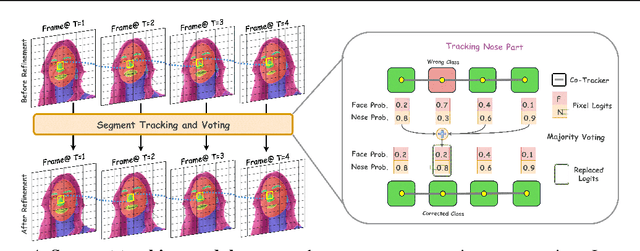
Segmenting an object in a video presents significant challenges. Each pixel must be accurately labelled, and these labels must remain consistent across frames. The difficulty increases when the segmentation is with arbitrary granularity, meaning the number of segments can vary arbitrarily, and masks are defined based on only one or a few sample images. In this paper, we address this issue by employing a pre-trained text to image diffusion model supplemented with an additional tracking mechanism. We demonstrate that our approach can effectively manage various segmentation scenarios and outperforms state-of-the-art alternatives.
How to Determine the Preferred Image Distribution of a Black-Box Vision-Language Model?
Sep 03, 2024Large foundation models have revolutionized the field, yet challenges remain in optimizing multi-modal models for specialized visual tasks. We propose a novel, generalizable methodology to identify preferred image distributions for black-box Vision-Language Models (VLMs) by measuring output consistency across varied input prompts. Applying this to different rendering types of 3D objects, we demonstrate its efficacy across various domains requiring precise interpretation of complex structures, with a focus on Computer-Aided Design (CAD) as an exemplar field. We further refine VLM outputs using in-context learning with human feedback, significantly enhancing explanation quality. To address the lack of benchmarks in specialized domains, we introduce CAD-VQA, a new dataset for evaluating VLMs on CAD-related visual question answering tasks. Our evaluation of state-of-the-art VLMs on CAD-VQA establishes baseline performance levels, providing a framework for advancing VLM capabilities in complex visual reasoning tasks across various fields requiring expert-level visual interpretation. We release the dataset and evaluation codes at \url{https://github.com/asgsaeid/cad_vqa}.
MMLU-Pro+: Evaluating Higher-Order Reasoning and Shortcut Learning in LLMs
Sep 03, 2024Existing benchmarks for large language models (LLMs) increasingly struggle to differentiate between top-performing models, underscoring the need for more challenging evaluation frameworks. We introduce MMLU-Pro+, an enhanced benchmark building upon MMLU-Pro to assess shortcut learning and higher-order reasoning in LLMs. By incorporating questions with multiple correct answers across diverse domains, MMLU-Pro+ tests LLMs' ability to engage in complex reasoning and resist simplistic problem-solving strategies. Our results show that MMLU-Pro+ maintains MMLU-Pro's difficulty while providing a more rigorous test of model discrimination, particularly in multi-correct answer scenarios. We introduce novel metrics like shortcut selection ratio and correct pair identification ratio, offering deeper insights into model behavior and anchoring bias. Evaluations of five state-of-the-art LLMs reveal significant performance gaps, highlighting variations in reasoning abilities and bias susceptibility. We release the dataset and evaluation codes at \url{https://github.com/asgsaeid/mmlu-pro-plus}.
Detecting Generative Parroting through Overfitting Masked Autoencoders
Mar 27, 2024

The advent of generative AI models has revolutionized digital content creation, yet it introduces challenges in maintaining copyright integrity due to generative parroting, where models mimic their training data too closely. Our research presents a novel approach to tackle this issue by employing an overfitted Masked Autoencoder (MAE) to detect such parroted samples effectively. We establish a detection threshold based on the mean loss across the training dataset, allowing for the precise identification of parroted content in modified datasets. Preliminary evaluations demonstrate promising results, suggesting our method's potential to ensure ethical use and enhance the legal compliance of generative models.
SLiMe: Segment Like Me
Sep 06, 2023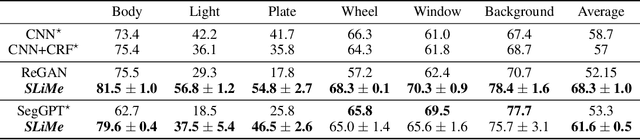

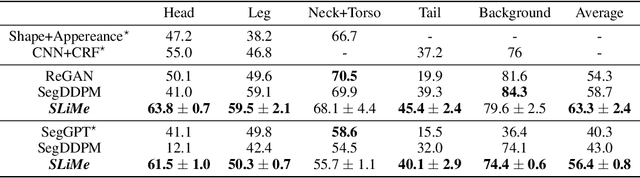

Significant strides have been made using large vision-language models, like Stable Diffusion (SD), for a variety of downstream tasks, including image editing, image correspondence, and 3D shape generation. Inspired by these advancements, we explore leveraging these extensive vision-language models for segmenting images at any desired granularity using as few as one annotated sample by proposing SLiMe. SLiMe frames this problem as an optimization task. Specifically, given a single training image and its segmentation mask, we first extract attention maps, including our novel "weighted accumulated self-attention map" from the SD prior. Then, using the extracted attention maps, the text embeddings of Stable Diffusion are optimized such that, each of them, learn about a single segmented region from the training image. These learned embeddings then highlight the segmented region in the attention maps, which in turn can then be used to derive the segmentation map. This enables SLiMe to segment any real-world image during inference with the granularity of the segmented region in the training image, using just one example. Moreover, leveraging additional training data when available, i.e. few-shot, improves the performance of SLiMe. We carried out a knowledge-rich set of experiments examining various design factors and showed that SLiMe outperforms other existing one-shot and few-shot segmentation methods.
Learned Visual Features to Textual Explanations
Sep 01, 2023Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of large language models (LLMs) to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and LLMs. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation
Jul 08, 2023



Significant progress has recently been made in creative applications of large pre-trained models for downstream tasks in 3D vision, such as text-to-shape generation. This motivates our investigation of how these pre-trained models can be used effectively to generate 3D shapes from sketches, which has largely remained an open challenge due to the limited sketch-shape paired datasets and the varying level of abstraction in the sketches. We discover that conditioning a 3D generative model on the features (obtained from a frozen large pre-trained vision model) of synthetic renderings during training enables us to effectively generate 3D shapes from sketches at inference time. This suggests that the large pre-trained vision model features carry semantic signals that are resilient to domain shifts, i.e., allowing us to use only RGB renderings, but generalizing to sketches at inference time. We conduct a comprehensive set of experiments investigating different design factors and demonstrate the effectiveness of our straightforward approach for generation of multiple 3D shapes per each input sketch regardless of their level of abstraction without requiring any paired datasets during training.
MaskTune: Mitigating Spurious Correlations by Forcing to Explore
Oct 08, 2022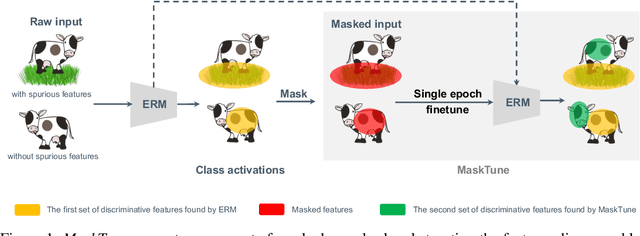
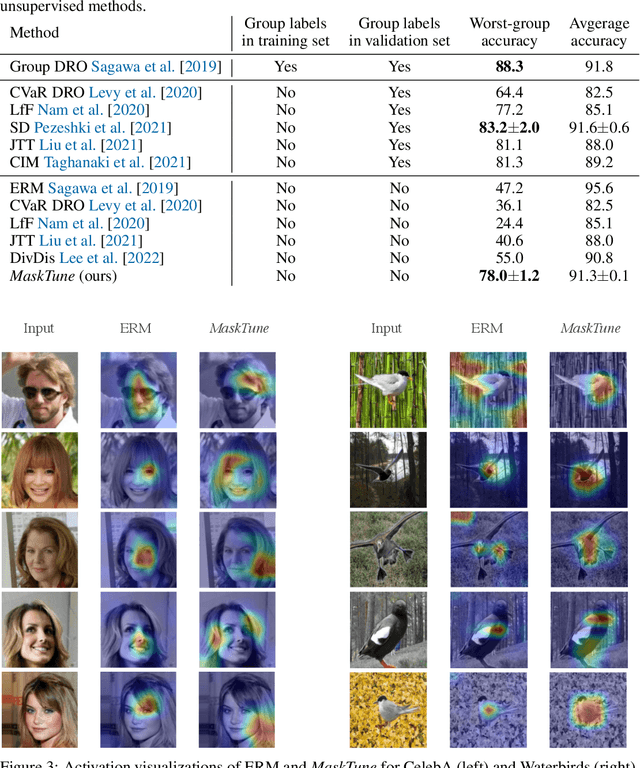
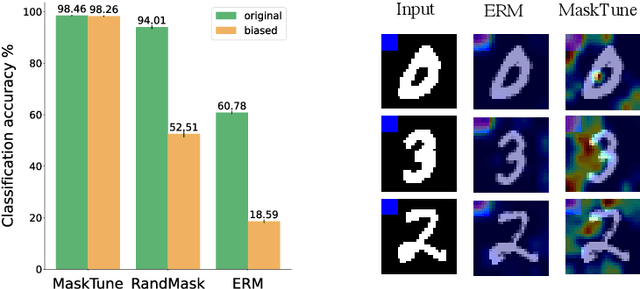

A fundamental challenge of over-parameterized deep learning models is learning meaningful data representations that yield good performance on a downstream task without over-fitting spurious input features. This work proposes MaskTune, a masking strategy that prevents over-reliance on spurious (or a limited number of) features. MaskTune forces the trained model to explore new features during a single epoch finetuning by masking previously discovered features. MaskTune, unlike earlier approaches for mitigating shortcut learning, does not require any supervision, such as annotating spurious features or labels for subgroup samples in a dataset. Our empirical results on biased MNIST, CelebA, Waterbirds, and ImagenNet-9L datasets show that MaskTune is effective on tasks that often suffer from the existence of spurious correlations. Finally, we show that MaskTune outperforms or achieves similar performance to the competing methods when applied to the selective classification (classification with rejection option) task. Code for MaskTune is available at https://github.com/aliasgharkhani/Masktune.