 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Engineering a Prompt Engineer
Nov 09, 2023Prompt engineering is a challenging yet crucial task for optimizing the performance of large language models (LLMs). It requires complex reasoning to examine the model's errors, hypothesize what is missing or misleading in the current prompt, and communicate the task with clarity. While recent works indicate that LLMs can be meta-prompted to perform automatic prompt engineering, their potentials may not be fully untapped due to the lack of sufficient guidance to elicit complex reasoning capabilities in LLMs in the meta-prompt. In this work, we investigate the problem of "prompt engineering a prompt engineer" -- constructing a meta-prompt that more effectively guides LLMs to perform automatic prompt engineering. We introduce and analyze key components, such as a step-by-step reasoning template and context specification, which lead to improved performance. In addition, inspired by common optimization concepts such as batch size, step size and momentum, we introduce their verbalized counterparts to the meta-prompt and investigate their effects. Our final method, named PE2, finds a prompt that outperforms "let's think step by step" by 6.3% on the MultiArith dataset and 3.1% on the GSM8K dataset. To demonstrate its versatility, we apply PE2 to the Instruction Induction benchmark, a suite of counterfactual tasks, and a lengthy, real-world industrial prompt. In these settings, PE2 achieves strong performance and outperforms prior automatic prompt engineering baselines. Further, we show that PE2 makes meaningful and targeted prompt edits, amends erroneous or incomplete prompts, and presents non-trivial counterfactual reasoning abilities.
Targeted Data Generation: Finding and Fixing Model Weaknesses
May 28, 2023
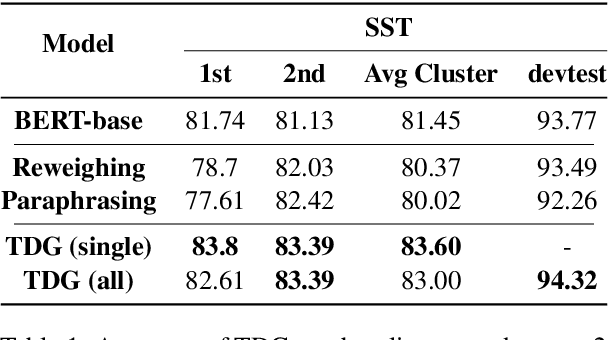


Even when aggregate accuracy is high, state-of-the-art NLP models often fail systematically on specific subgroups of data, resulting in unfair outcomes and eroding user trust. Additional data collection may not help in addressing these weaknesses, as such challenging subgroups may be unknown to users, and underrepresented in the existing and new data. We propose Targeted Data Generation (TDG), a framework that automatically identifies challenging subgroups, and generates new data for those subgroups using large language models (LLMs) with a human in the loop. TDG estimates the expected benefit and potential harm of data augmentation for each subgroup, and selects the ones most likely to improve within group performance without hurting overall performance. In our experiments, TDG significantly improves the accuracy on challenging subgroups for state-of-the-art sentiment analysis and natural language inference models, while also improving overall test accuracy.
Collaborative Development of NLP models
May 24, 2023



Despite substantial advancements, Natural Language Processing (NLP) models often require post-training adjustments to enforce business rules, rectify undesired behavior, and align with user values. These adjustments involve operationalizing "concepts"--dictating desired model responses to certain inputs. However, it's difficult for a single entity to enumerate and define all possible concepts, indicating a need for a multi-user, collaborative model alignment framework. Moreover, the exhaustive delineation of a concept is challenging, and an improper approach can create shortcuts or interfere with original data or other concepts. To address these challenges, we introduce CoDev, a framework that enables multi-user interaction with the model, thereby mitigating individual limitations. CoDev aids users in operationalizing their concepts using Large Language Models, and relying on the principle that NLP models exhibit simpler behaviors in local regions. Our main insight is learning a \emph{local} model for each concept, and a \emph{global} model to integrate the original data with all concepts. We then steer a large language model to generate instances within concept boundaries where local and global disagree. Our experiments show CoDev is effective at helping multiple users operationalize concepts and avoid interference for a variety of scenarios, tasks, and models.
MaskTune: Mitigating Spurious Correlations by Forcing to Explore
Oct 08, 2022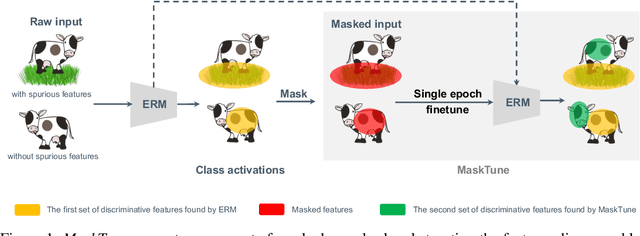
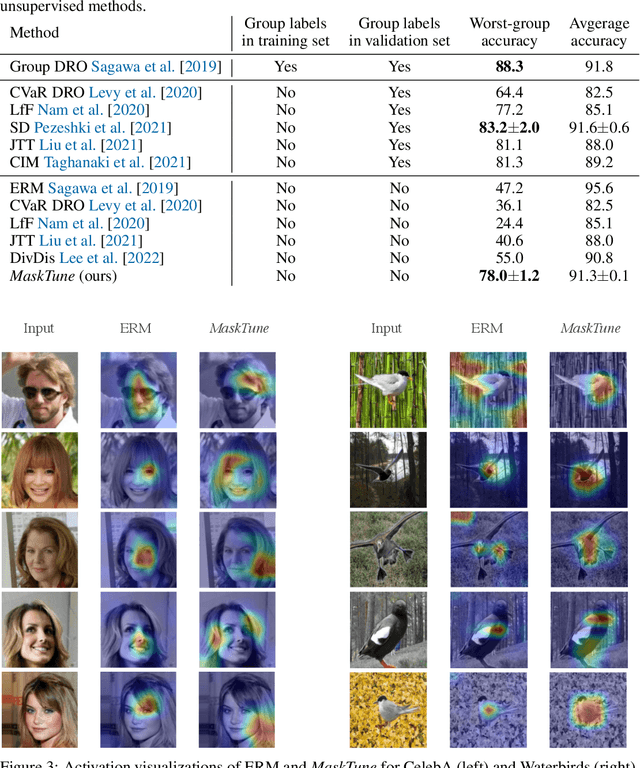
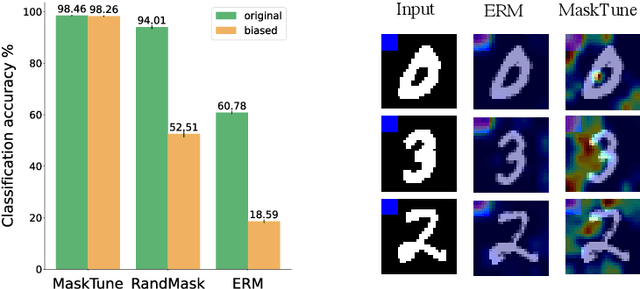

A fundamental challenge of over-parameterized deep learning models is learning meaningful data representations that yield good performance on a downstream task without over-fitting spurious input features. This work proposes MaskTune, a masking strategy that prevents over-reliance on spurious (or a limited number of) features. MaskTune forces the trained model to explore new features during a single epoch finetuning by masking previously discovered features. MaskTune, unlike earlier approaches for mitigating shortcut learning, does not require any supervision, such as annotating spurious features or labels for subgroup samples in a dataset. Our empirical results on biased MNIST, CelebA, Waterbirds, and ImagenNet-9L datasets show that MaskTune is effective on tasks that often suffer from the existence of spurious correlations. Finally, we show that MaskTune outperforms or achieves similar performance to the competing methods when applied to the selective classification (classification with rejection option) task. Code for MaskTune is available at https://github.com/aliasgharkhani/Masktune.
Counterbalancing Teacher: Regularizing Batch Normalized Models for Robustness
Jul 04, 2022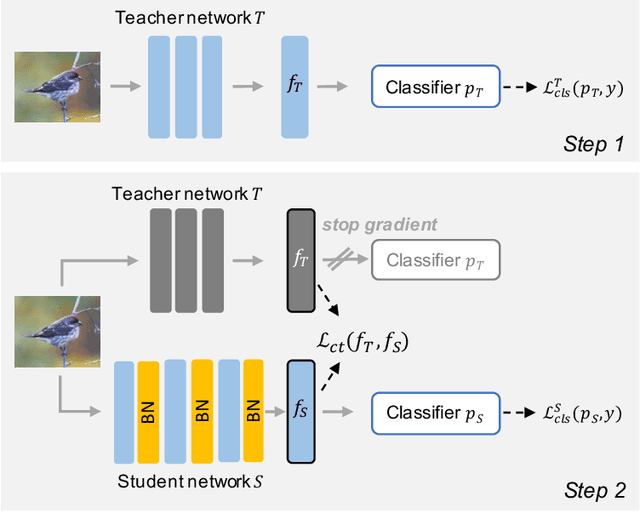
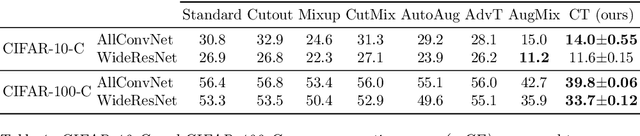
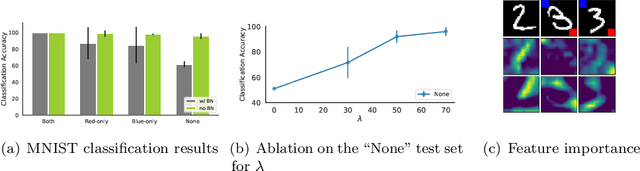
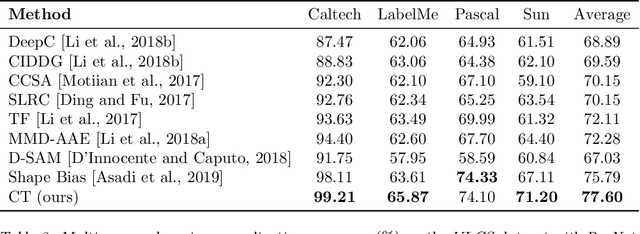
Batch normalization (BN) is a ubiquitous technique for training deep neural networks that accelerates their convergence to reach higher accuracy. However, we demonstrate that BN comes with a fundamental drawback: it incentivizes the model to rely on low-variance features that are highly specific to the training (in-domain) data, hurting generalization performance on out-of-domain examples. In this work, we investigate this phenomenon by first showing that removing BN layers across a wide range of architectures leads to lower out-of-domain and corruption errors at the cost of higher in-domain errors. We then propose Counterbalancing Teacher (CT), a method which leverages a frozen copy of the same model without BN as a teacher to enforce the student network's learning of robust representations by substantially adapting its weights through a consistency loss function. This regularization signal helps CT perform well in unforeseen data shifts, even without information from the target domain as in prior works. We theoretically show in an overparameterized linear regression setting why normalization leads to a model's reliance on such in-domain features, and empirically demonstrate the efficacy of CT by outperforming several baselines on robustness benchmarks such as CIFAR-10-C, CIFAR-100-C, and VLCS.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
Dec 16, 2020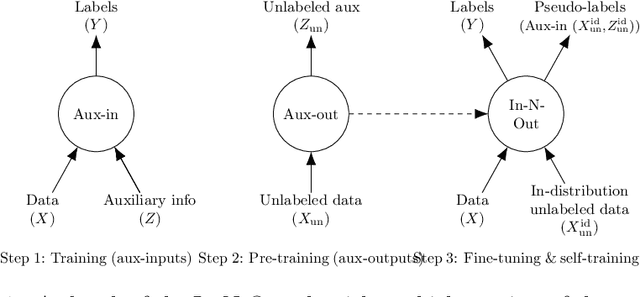
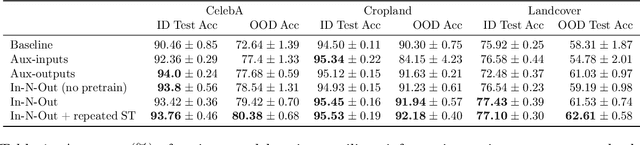

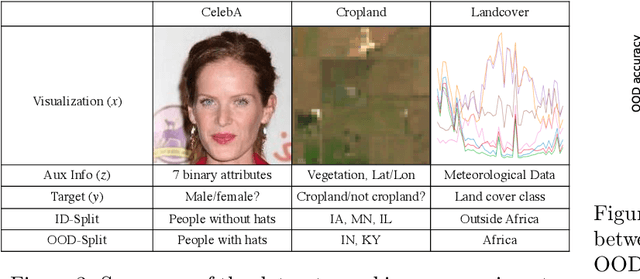
Consider a prediction setting where a few inputs (e.g., satellite images) are expensively annotated with the prediction targets (e.g., crop types), and many inputs are cheaply annotated with auxiliary information (e.g., climate information). How should we best leverage this auxiliary information for the prediction task? Empirically across three image and time-series datasets, and theoretically in a multi-task linear regression setting, we show that (i) using auxiliary information as input features improves in-distribution error but can hurt out-of-distribution (OOD) error; while (ii) using auxiliary information as outputs of auxiliary tasks to pre-train a model improves OOD error. To get the best of both worlds, we introduce In-N-Out, which first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs, then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training). We show both theoretically and empirically that In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error.
Removing Spurious Features can Hurt Accuracy and Affect Groups Disproportionately
Dec 07, 2020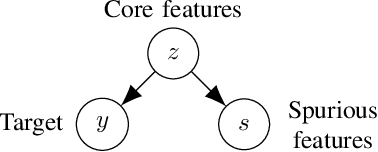


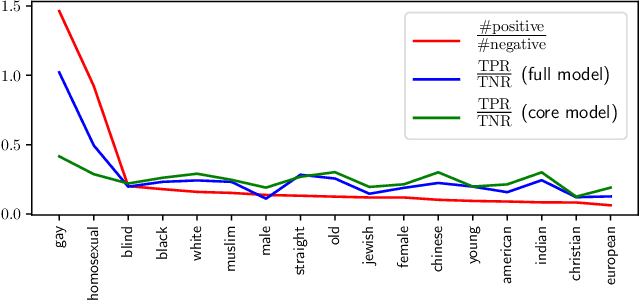
The presence of spurious features interferes with the goal of obtaining robust models that perform well across many groups within the population. A natural remedy is to remove spurious features from the model. However, in this work we show that removal of spurious features can decrease accuracy due to the inductive biases of overparameterized models. We completely characterize how the removal of spurious features affects accuracy across different groups (more generally, test distributions) in noiseless overparameterized linear regression. In addition, we show that removal of spurious feature can decrease the accuracy even in balanced datasets -- each target co-occurs equally with each spurious feature; and it can inadvertently make the model more susceptible to other spurious features. Finally, we show that robust self-training can remove spurious features without affecting the overall accuracy. Experiments on the Toxic-Comment-Detectoin and CelebA datasets show that our results hold in non-linear models.
Noise Induces Loss Discrepancy Across Groups for Linear Regression
Nov 22, 2019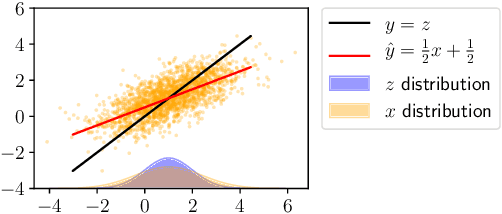

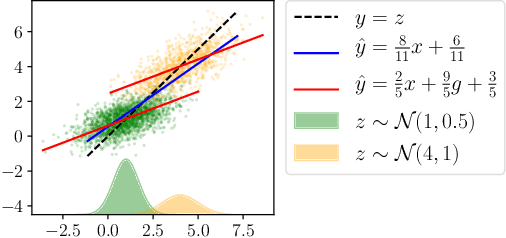

We study the effect of feature noise (measurement error) on the discrepancy between losses across two groups (e.g., men and women) in the context of linear regression. Our main finding is that adding even the same amount of noise on all individuals impacts groups differently. We characterize several forms of loss discrepancy in terms of the amount of noise and difference between moments of the two groups, for estimators that either do or do not use group membership information. We then study how long it takes for an estimator to adapt to a shift in the population that makes the groups have the same mean. We finally validate our results on three real-world datasets.
Maximum Weighted Loss Discrepancy
Jun 08, 2019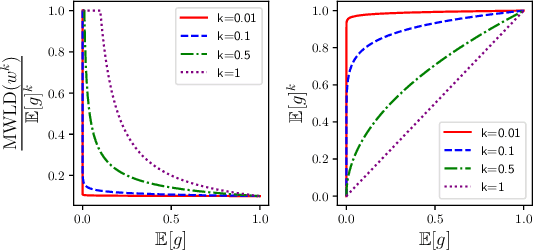

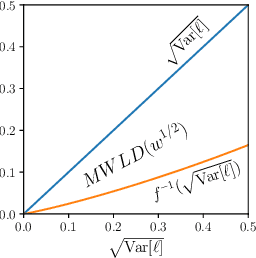
Though machine learning algorithms excel at minimizing the average loss over a population, this might lead to large discrepancies between the losses across groups within the population. To capture this inequality, we introduce and study a notion we call maximum weighted loss discrepancy (MWLD), the maximum (weighted) difference between the loss of a group and the loss of the population. We relate MWLD to group fairness notions and robustness to demographic shifts. We then show MWLD satisfies the following three properties: 1) It is statistically impossible to estimate MWLD when all groups have equal weights. 2) For a particular family of weighting functions, we can estimate MWLD efficiently. 3) MWLD is related to loss variance, a quantity that arises in generalization bounds. We estimate MWLD with different weighting functions on four common datasets from the fairness literature. We finally show that loss variance regularization can halve the loss variance of a classifier and hence reduce MWLD without suffering a significant drop in accuracy.