 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and the Future of Work in Africa White Paper
Nov 15, 2024
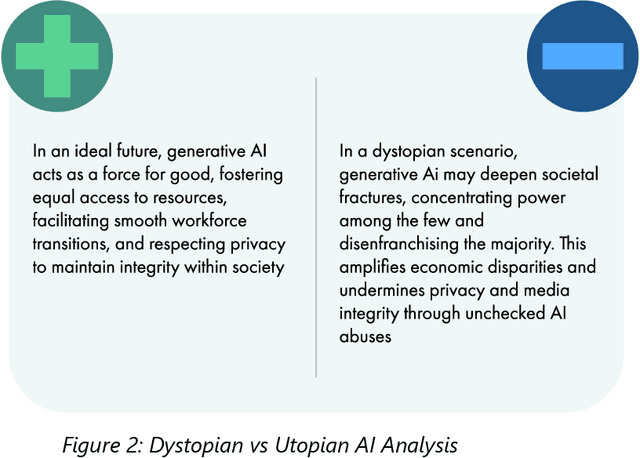
This white paper is the output of a multidisciplinary workshop in Nairobi (Nov 2023). Led by a cross-organisational team including Microsoft Research, NEPAD, Lelapa AI, and University of Oxford. The workshop brought together diverse thought-leaders from various sectors and backgrounds to discuss the implications of Generative AI for the future of work in Africa. Discussions centred around four key themes: Macroeconomic Impacts; Jobs, Skills and Labour Markets; Workers' Perspectives and Africa-Centris AI Platforms. The white paper provides an overview of the current state and trends of generative AI and its applications in different domains, as well as the challenges and risks associated with its adoption and regulation. It represents a diverse set of perspectives to create a set of insights and recommendations which aim to encourage debate and collaborative action towards creating a dignified future of work for everyone across Africa.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.
Prompt Engineering a Prompt Engineer
Nov 09, 2023Prompt engineering is a challenging yet crucial task for optimizing the performance of large language models (LLMs). It requires complex reasoning to examine the model's errors, hypothesize what is missing or misleading in the current prompt, and communicate the task with clarity. While recent works indicate that LLMs can be meta-prompted to perform automatic prompt engineering, their potentials may not be fully untapped due to the lack of sufficient guidance to elicit complex reasoning capabilities in LLMs in the meta-prompt. In this work, we investigate the problem of "prompt engineering a prompt engineer" -- constructing a meta-prompt that more effectively guides LLMs to perform automatic prompt engineering. We introduce and analyze key components, such as a step-by-step reasoning template and context specification, which lead to improved performance. In addition, inspired by common optimization concepts such as batch size, step size and momentum, we introduce their verbalized counterparts to the meta-prompt and investigate their effects. Our final method, named PE2, finds a prompt that outperforms "let's think step by step" by 6.3% on the MultiArith dataset and 3.1% on the GSM8K dataset. To demonstrate its versatility, we apply PE2 to the Instruction Induction benchmark, a suite of counterfactual tasks, and a lengthy, real-world industrial prompt. In these settings, PE2 achieves strong performance and outperforms prior automatic prompt engineering baselines. Further, we show that PE2 makes meaningful and targeted prompt edits, amends erroneous or incomplete prompts, and presents non-trivial counterfactual reasoning abilities.
MEGA: Multilingual Evaluation of Generative AI
Apr 03, 2023



Generative AI models have impressive performance on many Natural Language Processing tasks such as language understanding, reasoning and language generation. One of the most important questions that is being asked by the AI community today is about the capabilities and limits of these models, and it is clear that evaluating generative AI is very challenging. Most studies on generative Large Language Models (LLMs) are restricted to English and it is unclear how capable these models are at understanding and generating other languages. We present the first comprehensive benchmarking of generative LLMs - MEGA, which evaluates models on standard NLP benchmarks, covering 8 diverse tasks and 33 typologically diverse languages. We also compare the performance of generative LLMs to State of the Art (SOTA) non-autoregressive models on these tasks to determine how well generative models perform compared to the previous generation of LLMs. We present a thorough analysis of the performance of models across languages and discuss some of the reasons why generative LLMs are currently not optimal for all languages. We create a framework for evaluating generative LLMs in the multilingual setting and provide directions for future progress in the field.