 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pretraining via Active Forgetting for Improving Cross Lingual Transfer for Decoder Language Models
Oct 21, 2024



Large Language Models (LLMs) demonstrate exceptional capabilities in a multitude of NLP tasks. However, the efficacy of such models to languages other than English is often limited. Prior works have shown that encoder-only models such as BERT or XLM-RoBERTa show impressive cross lingual transfer of their capabilities from English to other languages. In this work, we propose a pretraining strategy that uses active forgetting to achieve similar cross lingual transfer in decoder-only LLMs. We show that LLMs pretrained with active forgetting are highly effective when adapting to new and unseen languages. Through extensive experimentation, we find that LLMs pretrained with active forgetting are able to learn better multilingual representations which translates to better performance in many downstream tasks.
Improving Self Consistency in LLMs through Probabilistic Tokenization
Jul 04, 2024
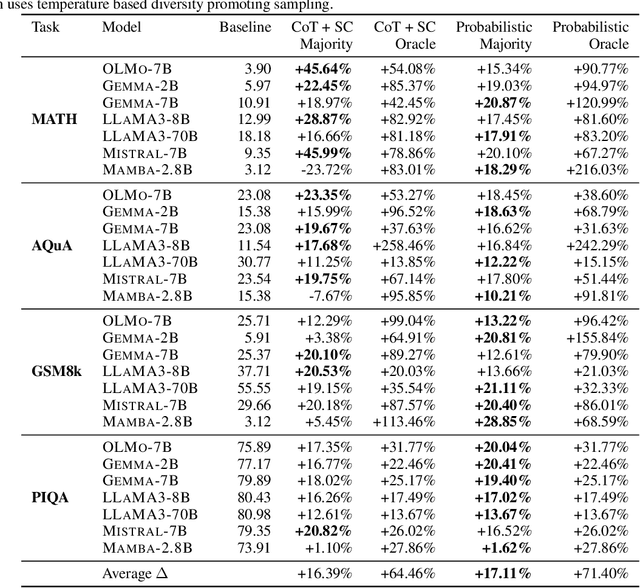

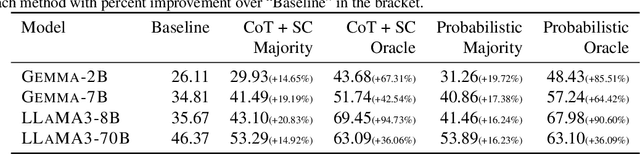
Prior research has demonstrated noticeable performance gains through the use of probabilistic tokenizations, an approach that involves employing multiple tokenizations of the same input string during the training phase of a language model. Despite these promising findings, modern large language models (LLMs) have yet to be trained using probabilistic tokenizations. Interestingly, while the tokenizers of these contemporary LLMs have the capability to generate multiple tokenizations, this property remains underutilized. In this work, we propose a novel method to leverage the multiple tokenization capabilities of modern LLM tokenizers, aiming to enhance the self-consistency of LLMs in reasoning tasks. Our experiments indicate that when utilizing probabilistic tokenizations, LLMs generate logically diverse reasoning paths, moving beyond mere surface-level linguistic diversity.We carefully study probabilistic tokenization and offer insights to explain the self consistency improvements it brings through extensive experimentation on 5 LLM families and 4 reasoning benchmarks.
Efficient Training of Language Models with Compact and Consistent Next Token Distributions
Jul 03, 2024

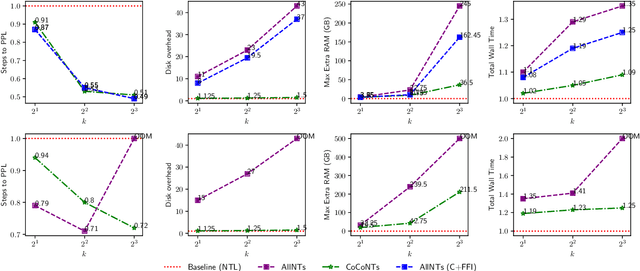

Maximizing the likelihood of the next token is an established, statistically sound objective for pre-training language models. In this paper we show that we can train better models faster by pre-aggregating the corpus with a collapsed $n$-gram distribution. Previous studies have proposed corpus-level $n$-gram statistics as a regularizer; however, the construction and querying of such $n$-grams, if done naively, prove to be costly and significantly impede training speed, thereby limiting their application in modern large language model pre-training. We introduce an alternative compact representation of the next token distribution that, in expectation, aligns with the complete $n$-gram distribution while markedly reducing variance across mini-batches compared to the standard next-token loss. Empirically, we demonstrate that both the $n$-gram regularized model and our approximation yield substantial improvements in model quality and convergence rate compared to existing methods. Furthermore, our approximation facilitates scalability of gains to larger datasets and models compared to the straightforward $n$-gram regularization method.
A Unified Framework and Dataset for Assessing Gender Bias in Vision-Language Models
Feb 21, 2024
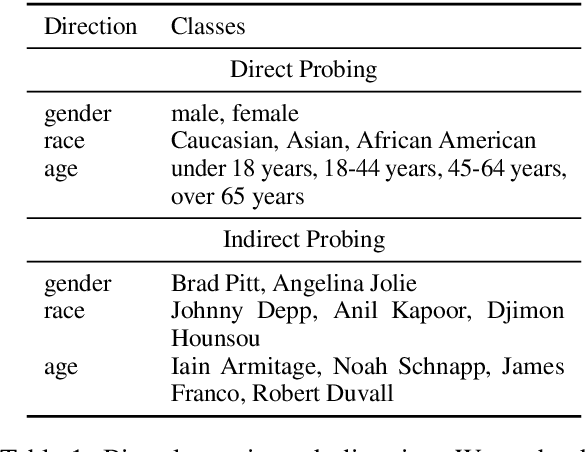


Large vision-language models (VLMs) are widely getting adopted in industry and academia. In this work we build a unified framework to systematically evaluate gender-profession bias in VLMs. Our evaluation encompasses all supported inference modes of the recent VLMs, including image-to-text, text-to-text, text-to-image, and image-to-image. We construct a synthetic, high-quality dataset of text and images that blurs gender distinctions across professional actions to benchmark gender bias. In our benchmarking of recent vision-language models (VLMs), we observe that different input-output modalities result in distinct bias magnitudes and directions. We hope our work will help guide future progress in improving VLMs to learn socially unbiased representations. We will release our data and code.
MAFIA: Multi-Adapter Fused Inclusive LanguAge Models
Feb 12, 2024



Pretrained Language Models (PLMs) are widely used in NLP for various tasks. Recent studies have identified various biases that such models exhibit and have proposed methods to correct these biases. However, most of the works address a limited set of bias dimensions independently such as gender, race, or religion. Moreover, the methods typically involve finetuning the full model to maintain the performance on the downstream task. In this work, we aim to modularly debias a pretrained language model across multiple dimensions. Previous works extensively explored debiasing PLMs using limited US-centric counterfactual data augmentation (CDA). We use structured knowledge and a large generative model to build a diverse CDA across multiple bias dimensions in a semi-automated way. We highlight how existing debiasing methods do not consider interactions between multiple societal biases and propose a debiasing model that exploits the synergy amongst various societal biases and enables multi-bias debiasing simultaneously. An extensive evaluation on multiple tasks and languages demonstrates the efficacy of our approach.
MAPLE: Multilingual Evaluation of Parameter Efficient Finetuning of Large Language Models
Jan 15, 2024



Parameter efficient finetuning has emerged as a viable solution for improving the performance of Large Language Models without requiring massive resources and compute. Prior work on multilingual evaluation has shown that there is a large gap between the performance of LLMs on English and other languages. Further, there is also a large gap between the performance of smaller open-source models and larger LLMs. Finetuning can be an effective way to bridge this gap and make language models more equitable. In this work, we finetune the LLaMA-7B and Mistral-7B models on synthetic multilingual instruction tuning data to determine its effect on model performance on five downstream tasks covering twenty three languages in all. Additionally, we experiment with various parameters, such as rank for low-rank adaptation and values of quantisation to determine their effects on downstream performance and find that higher rank and higher quantisation values benefit low-resource languages. We find that parameter efficient finetuning of smaller open source models sometimes bridges the gap between the performance of these models and the larger ones, however, English performance can take a hit. We also find that finetuning sometimes improves performance on low-resource languages, while degrading performance on high-resource languages.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.
Benchmarking and Improving Text-to-SQL Generation under Ambiguity
Oct 20, 2023
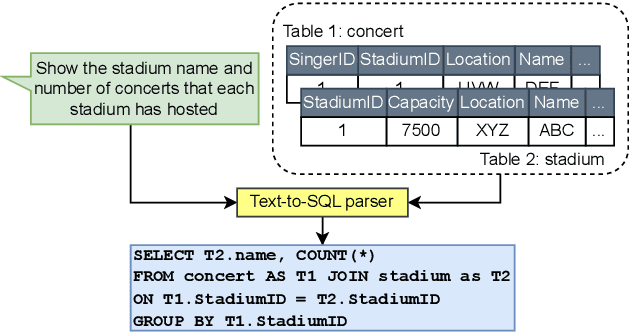

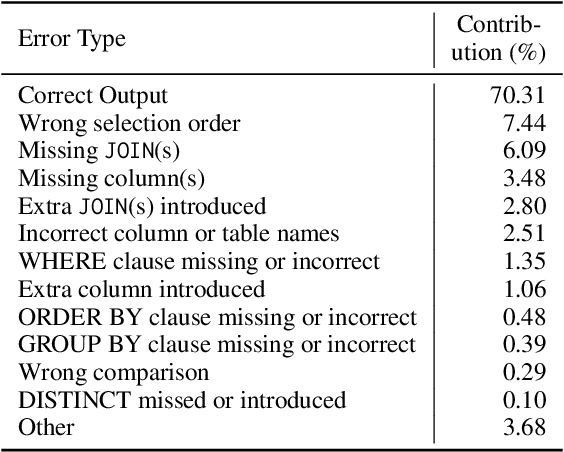
Research in Text-to-SQL conversion has been largely benchmarked against datasets where each text query corresponds to one correct SQL. However, natural language queries over real-life databases frequently involve significant ambiguity about the intended SQL due to overlapping schema names and multiple confusing relationship paths. To bridge this gap, we develop a novel benchmark called AmbiQT with over 3000 examples where each text is interpretable as two plausible SQLs due to lexical and/or structural ambiguity. When faced with ambiguity, an ideal top-$k$ decoder should generate all valid interpretations for possible disambiguation by the user. We evaluate several Text-to-SQL systems and decoding algorithms, including those employing state-of-the-art LLMs, and find them to be far from this ideal. The primary reason is that the prevalent beam search algorithm and its variants, treat SQL queries as a string and produce unhelpful token-level diversity in the top-$k$. We propose LogicalBeam, a new decoding algorithm that navigates the SQL logic space using a blend of plan-based template generation and constrained infilling. Counterfactually generated plans diversify templates while in-filling with a beam-search that branches solely on schema names provides value diversity. LogicalBeam is up to $2.5$ times more effective than state-of-the-art models at generating all candidate SQLs in the top-$k$ ranked outputs. It also enhances the top-$5$ Exact and Execution Match Accuracies on SPIDER and Kaggle DBQA.
Diverse Parallel Data Synthesis for Cross-Database Adaptation of Text-to-SQL Parsers
Oct 29, 2022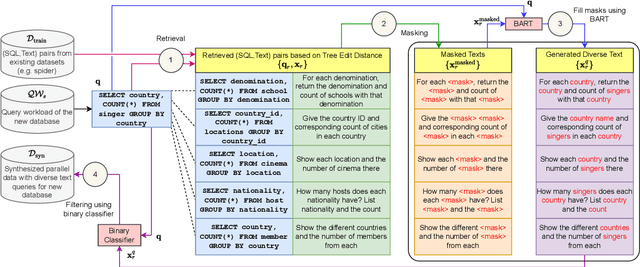
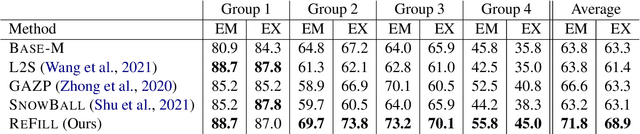
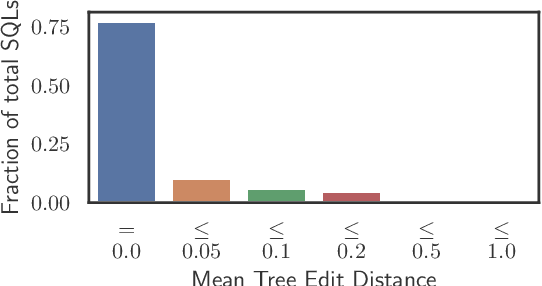
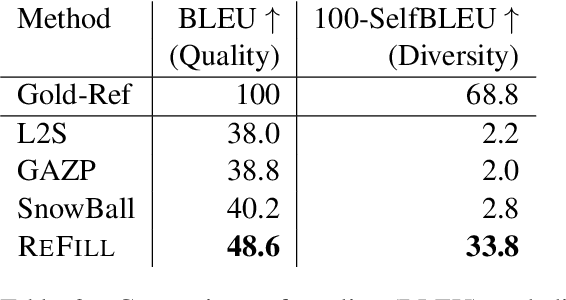
Text-to-SQL parsers typically struggle with databases unseen during the train time. Adapting parsers to new databases is a challenging problem due to the lack of natural language queries in the new schemas. We present ReFill, a framework for synthesizing high-quality and textually diverse parallel datasets for adapting a Text-to-SQL parser to a target schema. ReFill learns to retrieve-and-edit text queries from the existing schemas and transfers them to the target schema. We show that retrieving diverse existing text, masking their schema-specific tokens, and refilling with tokens relevant to the target schema, leads to significantly more diverse text queries than achievable by standard SQL-to-Text generation methods. Through experiments spanning multiple databases, we demonstrate that fine-tuning parsers on datasets synthesized using ReFill consistently outperforms the prior data-augmentation methods.