 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
Jun 21, 2024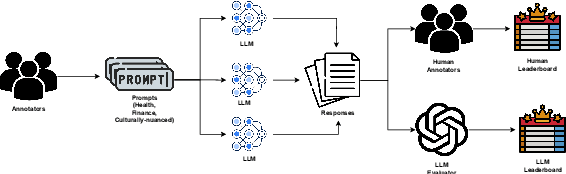
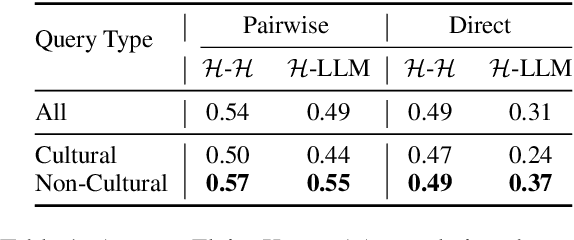
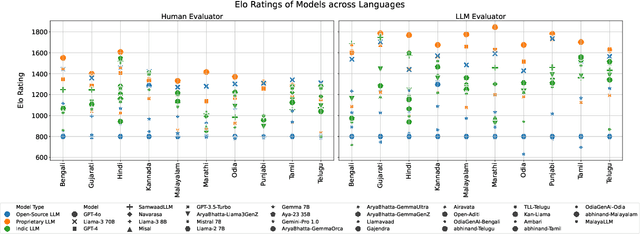
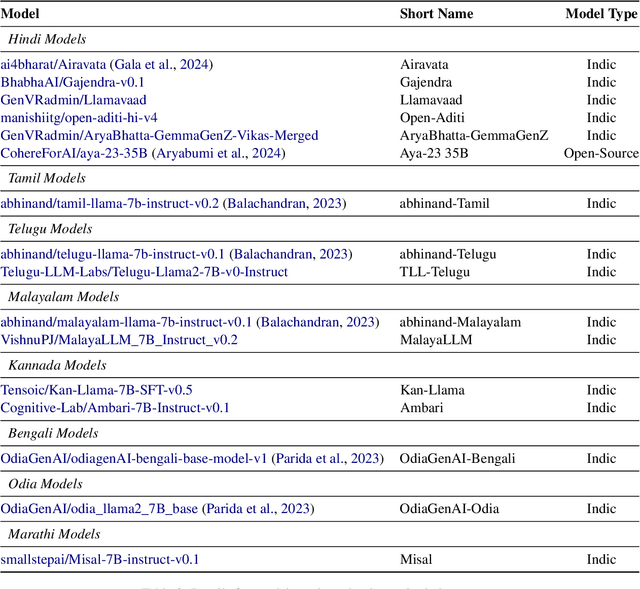
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
RTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Apr 22, 2024



Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.